掌握 RAG(检索增强生成),就是把大模型从“聪明却不可靠的演讲家”升级为“随时查资料、句句有出处”的超级顾问,让 AI 功能在产品里真正可用、敢用、可持续用。作为AI产品经理的我们,这也是必须掌握的技术原理。

RAG解决了AI大模型什么问题?
幻觉(Hallucination)
传统大模型靠内部参数“猜”答案,知识盲区只能靠编造填补,导致事实性错误频发。RAG 把回答建立在检索到的原文片段上,模型只负责“总结引用”,显著降低一本正经胡说八道的概率。
知识时效性
训练一次百亿级模型≈烧掉一栋楼的钱,不可能周周重训。RAG 把知识外置到可热插拔的索引库,更新文档即可秒级生效,让模型永远“活在今天”。
领域专业壁垒
通用模型对垂直领域(医疗、法律、金融)往往一知半解。RAG 允许接入私有知识库(监管条文、内部 SOP、病历库),无需重训即可让模型瞬间变成“领域专家”。
长文本窗口受限
上下文长度始终是硬瓶颈。RAG 把超长文档拆块建索引,按需检索 Top-K 片段塞进有限窗口,既突破长度限制,又避免无关信息稀释注意力。

一句话总结:RAG 把大模型从“靠记忆答题”转变为“带着参考资料答题”,一次性扫清了幻觉、时效、专业、合规、长文本、成本六大落地障碍,让高智商模型真正变成可上线、可维护、可盈利的企业级产品。
RAG工作链路拆解(RAG是如何工作的)
总的来说,RAG的运行分为两个流程,第一个流程为准备(提问前),准备流程又包含了两个阶段。第一个阶段为分片,第二个跌断为索引。第二个流程则是回答(提问后),整个流程包含四个阶段。第一个阶段为召回,第二个流程为重排,第三个流程为生成。
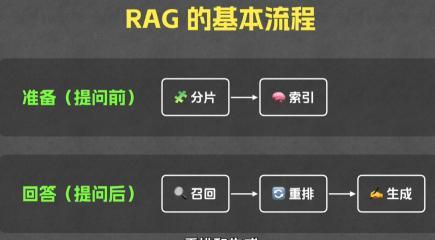
准备环节(分片 -> 索引)
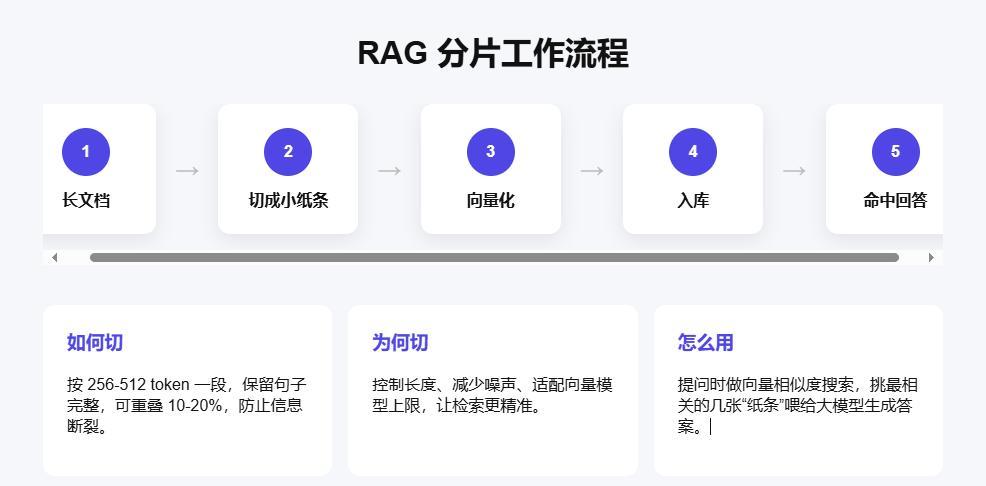
分片:在 RAG(Retrieval-Augmented Generation)系统中,“分片”(Chunking/Splitting)是提问前准备阶段的第一步,也是决定后续召回与生成质量的关键环节。它的核心任务是把长文档切成语义相对独立、长度适中的小片段,再向量化并入库,供检索时精准命中。
1)目标
在知识库构建阶段,将原始文档(PDF、Word、Markdown 等)切成若干chunk(也称 passage/block),使每个 chunk 既能表达完整语义,又不会过长,避免
- 超出 Embedding 模型最大 token 限制
- 检索时带入大量无关信息,稀释注意力
2)主流切分策略
- 固定长度切分(Fixed-Size):按 256/512/1024 token 一刀切,允许重叠 20~50 token 保持上下文
- 递归字符切分(Recursive):优先按段落→句子→单词切,尽量不断句,LangChain、LlamaIndex 默认实现
- 语义切分(Semantic):先按句子/段落做向量,连续段向量余弦相似度骤降处下刀,保证主题一致
- 结构切分(Document-Structure):利用标题、列表、表格等标记,把“一节 / 一张表 / 一段代码”整体作为 chunk
- LLM 智能切分:让大模型阅读后自行决定“这句话意思完整了吗?”——效果最佳,但成本高
总结:把一本厚书先剪成一页页“小纸条”,根据裁剪方式得不同纸条呈现的样子不同;但是最终想要达成的目的就是让AI更好理解我们上传的知识内容。
索引:RAG 的索引阶段其实只做一件事:把“一堆文字”变成“可快速查找的向量仓库”。整个过程可以拆成两步,但每一步都围绕“让检索又快又准”这个目标展开。
- 向量化。每个文本块被送入Embedding模型,如BGE、E5或OpenAI的text-embedding-ada-002,输出一串几百到上千维的浮点向量。向量之间的距离越近,表示原文本语义越接近。
- 索引构建。这些“文本块—向量”对会被写入向量数据库(FAISS、Chroma、Pinecone等)。数据库内部会建立近似最近邻索引(HNSW或IVF),把高维向量组织成图或簇结构,使得后续查询能在毫秒级返回与问题向量最接近的k个文本块。
当用户提问时,系统用同样的 Embedding 模型把问题转成向量,直接在索引里做向量检索,把最相关的文本块送给大模型生成答案。索引本身不再动态更新。
总结:把 RAG 索引想成“做奶茶外卖”:
- 把各种水果、珍珠、茶包全部拆成小包,方便一次一勺(切分)。
- 给每包贴上二维码,扫码就能知道是“草莓味”“椰果”“乌龙”等(向量化)。
- 把这些小包按口味排进透明冷柜,柜门贴着“果味”“奶味”“茶味”标签(建索引)。
- 客人说“我要草莓奶盖”,店员扫码“草莓+奶盖”二维码,瞬间拉开对应抽屉,抓出最匹配的小包,摇一摇就出杯(检索+回答问题)。
一句话:提前把配料分好、贴码、排队,客人一点单就能秒配。

模型回应环节(召回 -> 重排 ->生成)
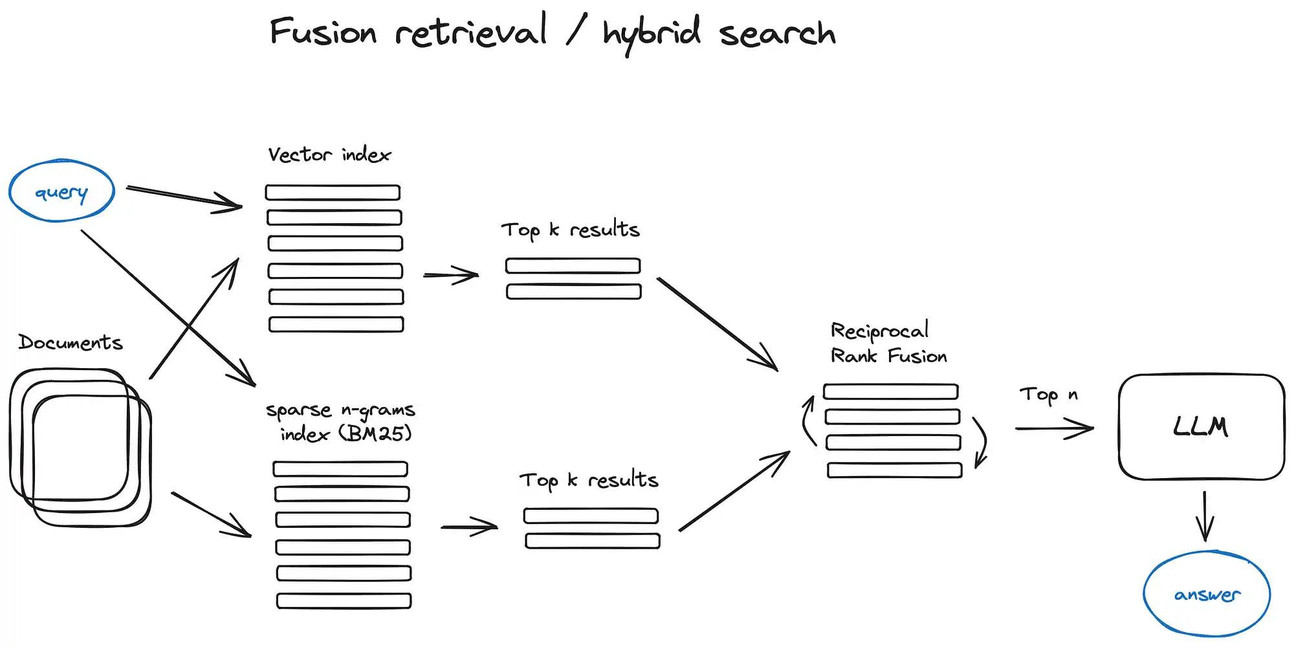
召回:召回阶段把“用户问的问题”变成一段高维语义向量,然后用这段向量去一个预先建好的向量库中做最近邻搜索。整个流程可以拆成下面五步:
1)统一编码
同一个经过训练的语义编码器,既把知识库里的每一段文本压缩成固定长度的语义向量,也把实时输入的问题压缩成同样长度的语义向量。这样问题和文档就在一个空间里可比了。
2)构建索引
知识库的全部向量被一次性放进一种专门支持“最近邻快速查找”的索引结构,常见的是分层可导航小世界图或倒排加乘积量化混合结构。索引只保存向量和指向原文的指针,不保留原文本身。
3)在线查询
当用户输入问题后,编码器立刻把它变成向量,然后把这个向量送到索引里。索引利用预先构建的图或聚类信息,只探索少量节点就能锁定一批候选向量,而不是逐个比对全文。
4)相似度计算
对候选向量逐一计算与问题向量的语义距离,距离越小表示内容越接近。计算完按距离从小到大排序,挑出最靠前的若干条结果。
5)返回片段
每条结果只包含原文档的标识和段落位置,系统根据这些标识把对应的原始文字片段取出,作为召回结果输出。
总结:召回就像图书馆找书,先把每本书的内容变成一张“小纸条”,纸条上写着这本书的“意思”。你提问题时,也给你写一张“问题纸条”。系统拿你的纸条去跟所有书纸条比相似度,挑出最像的前几本,把对应的书页拿出来交给你。
重排:重排环节只负责把已召回的候选段落重新排序,核心是一套“段落级重排器”。其工作机理可拆成四层:
- 输入构造对每个候选段落,先把它和查询拼成一段联合文本,并在两者之间插入特殊分隔标记,形成统一格式的输入序列。
- 深层交互编码把联合文本送入一个经过交叉注意力训练的Transformer。模型内部让查询的每个词与段落里的每个词做双向关注,捕捉细粒度匹配信号,如实体对齐、同义改写、上下位关系等。
- 相关性打分Transformer的最后一层输出被池化成单一向量,再接一个小型前馈网络,输出一个介于零到一的相关度分数。分数反映该段落回答查询的可能性。
- 结果重排与截断按分数降序排列所有候选;若系统有“top-k”限制,则只保留前k条;若需多样性,可在排序后做去重或聚类微调,再输出最终顺序。
总结:重排就像一次“二次面试”。
- 把问题和每段候选文字当成一对“面试官和应聘者”,一起放进一个聪明的小模型。
- 小模型让两边互相提问、对答案,看契合度有多高。
- 契合度高的应聘者得分高,低的得分低。
- 按分数从高到低重新排队,只留最前面的几位,后面的直接淘汰。
就这么简单。
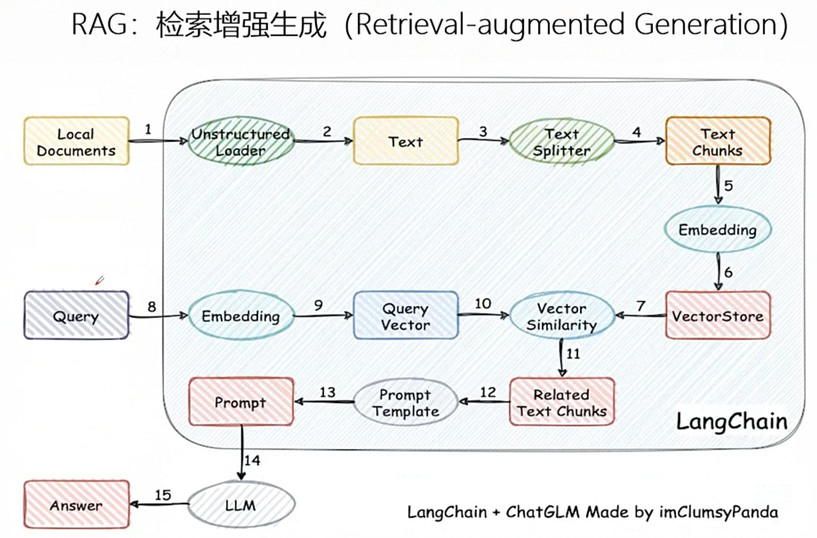
生成:生成阶段只负责一件事:拿到经过重排后留下的精炼上下文,与用户问题一起,生成一段连贯、准确、可控的最终答案。其工作流程可拆成四层:
1)输入封装
系统把用户问题放在最前面,随后插入若干条上下文段落,段与段之间用特殊分隔符隔开,整体再附上一段系统级提示,告诉模型“请严格依据下文内容作答,不要杜撰”。
2)位置编码与注意力掩码
为了让模型在阅读时知道哪些词来自问题、哪些词来自哪一段上下文,编码器会给每个位置打上可区分的标识,并在注意力层设置掩码,使生成过程中的每一步只能“看见”前面已经出现的所有信息,防止自环泄露。
3)逐词生成
模型以自回归方式一次输出一个词。每一步都重新扫描整段已见文本,依据上下文语义、事实一致性、语言流畅度以及预设风格,动态决定下一个最合理的词。若遇到冲突信息,模型会优先采信排序靠前的段落;若段落本身含糊,模型会采用保守策略,给出“根据现有资料无法确定”之类的表述。
4)后处理与输出
生成的原始文本先经过敏感词过滤、重复片段合并、引用标记插入等后处理,再返回给调用方。部分系统还会附带一个置信度评分,用于提示哪些句子直接摘抄自原文、哪些句子是模型综合后的转述,方便用户二次核查。
总结:生成就像“开卷考试的最后一道大题”:
把题目和参考资料一次性摆到模型面前。
模型先通读一遍,心里记下哪些段落能直接回答,哪些只是背景。
然后开始一句一句写答案:
- 能照抄的照抄,能改写就改写;
- 遇到冲突就挑最靠前的段落为准;
- 实在找不到就老实写“资料里没说”。
写好后自动检查错别字、重复句,再把引用标出来,交卷。
本文由 @产品经理小易 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议