长上下文大语言模型推动了众多下游应用的发展,但也带来了计算和内存效率方面的重大挑战。为了应对这些挑战,围绕 KV 缓存的长上下文推理优化方法应运而生。然而,现有基准测试通常仅关注单请求场景,忽视了 KV 缓存在实际使用中的完整生命周期。
在 AICon2025 上海站上,微软亚洲研究院研究开发工程师姜慧强带来了题为《以 KV 缓存为中心的高效长文本方法》的演讲,分享了 SCBench 这一全面的基准测试工具,并对目前主流的推理优化方法进行梳理,还介绍了各类高效长文本方法,包括 MInference, MMInference, RetrievalAttention 等。
长文本大语言模型的应用和推理挑战
目前,支持长上下文的大语言模型(LLM)已成为主流,广泛支撑各类下游应用。更长的上下文窗口能够显著提升模型的智能表现。例如,我们可以将会议纪要、技术文档或企业知识注入模型的上下文中,增强其问题理解与解决能力。在代码场景中,诸如自动纠错、生成 PR 等任务也高度依赖于模型处理长上下文的能力。
当前,像 Gemini 等前沿模型已支持千万级 token 的上下文窗口,显著提升了下游任务的效果,特别是在 Agent 类应用中表现尤为突出。例如,Manus 就高度依赖超长上下文进行智能决策。
与此同时,近年来涌现出的推理型 LLM 也越来越依赖长上下文能力以提升推理效率。在不少真实场景中,推理长度常常超过数万 token,借助更长的上下文,模型可以做出更复杂、更智能的判断。
如今,长上下文已成为 LLM 的“标配”。千万级 token 的上下文容量已经可以容纳完整的代码库,例如我们可以将整个 Python 项目的 repo 作为输入交给模型,让它辅助完成复杂的调试或 PR 操作。同时,这样的窗口也能承载极长的视频信息,比如将完整的《指环王》三部曲作为输入,驱动模型完成长链条、多层次的推理任务。
 <!---->
<!---->然而,尽管长上下文为大模型带来了更强的智能能力,但其使用成本极高,推理速度也显著降低,面临两个主要挑战。
第一个挑战是计算复杂度带来的延迟瓶颈。由于注意力机制在上下文长度上的平方级计算复杂度,模型在执行上下文预填充(Prefilling)阶段的延迟极高。例如,在一张 A100 GPU 上推理一个 8B 参数规模的模型,处理 100 万 token 的输入可能需要超过 30 分钟。而若要将 1M token 推理服务化为一个响应时间仅为数十秒的 API(如 GPT-4o 所提供的能力),往往需要动用数十张 GPU,带来极大的云端资源压力与成本负担。
第二个挑战是 KV Cache 带来的存储压力。 为了提升解码阶段的速度,现代推理系统普遍采用 KV Cache 技术。但在长上下文场景下,即使采用 8bit 等低精度量化方式,单个请求的 KV Cache 存储开销仍可高达数十 GB。这对 GPU 显存构成极大压力,也严重制约了多请求并发处理能力,进一步推高云端部署成本。
 <!---->
<!---->针对上述两个挑战,我们提出了多项优化方案:我们通过 MInference 显著降低了上下文预填充(Prefilling)阶段的延迟,最高可减少一个数量级;同时,RetrievalAttention 有效缓解了 KV Cache 的显存压力,使得即使在消费级显卡如 RTX 4090 上也可支持 128K token 的上下文推理。
在真实的 LLM 推理服务场景中,系统通常需要同时处理多个用户请求,因此系统级的跨请求优化尤为重要。最常见的策略之一是 Prefix Cache 复用。例如,在使用统一系统提示词(system prompt)的场景中,不同请求间往往存在大量上下文重叠。如果能够复用这部分 KV Cache,将显著降低重复计算开销。目前市面上主流的推理框架大多围绕 KV Cache 构建,利用跨节点 KV Cache 管理来提升整体处理效率。
因此,我们也采用以 KV Cache 为中心 的设计思路,将 LLM 推理流程划分为多个阶段。一个典型的推理流程如下:
Prefilling 阶段:当请求到达后,Prompt 会经过 LLM 计算并生成初始的 KV Cache,此阶段我们可采用高效计算策略(如 MInference)以降低延迟;
KV Cache 存储阶段:KV Cache 生成后在写入内存或显存前,可以进行压缩等操作,以减少空间开销;
KV Cache 召回与加载阶段:在 Decoding 阶段,从存储中读取 KV Cache 时仍有进一步优化空间,通过合理的数据布局与预取机制缓解内存瓶颈,提高解码效率。
通过上述全链路优化,我们在保证模型智能能力的同时,大幅提升了长上下文 LLM 推理的可扩展性与经济性。
 <!---->
<!---->当前主流推理优化方法与技术
我们首先回顾一下目前主流的推理优化方法和对应的技术。
 <!---->
<!---->在 LLM 推理服务(LLM serving)中,优化手段大致可以分为两类:
算法层优化:主要包括解码策略的设计,提升如内存利用率、计算效率等模型内部指标;
系统层优化:涵盖低精度量化、并行计算、内存管理与请求调度等方面,用于提升推理系统整体的吞吐与资源使用效率。
其中,以 KV Cache 为核心的优化技术中,Prefix Caching 是应用最广泛的一种。其基本思想是:对多个请求中可复用的前缀部分,在 Prefilling 阶段预先计算出对应的 KV Cache,并将其卸载(offload)到远端存储介质,例如通过 RDMA 存入分布式缓存系统。当新请求到达时(例如多轮对话中的后续轮次),系统可以从远端快速加载已有的 KV Cache 并回填至本地推理引擎中,从而避免重复计算,极大提升效率。
Prefix Caching 已广泛应用于主流的 LLM API 服务商与推理框架中,尽管在实现细节上存在差异。例如,SGLang 最初采用基于前缀树(prefix trie)的方法,在不同请求间快速查找可复用的 KV Cache。最新版本则更倾向于使用哈希函数来判断 KV Cache 是否命中,这种方式在实际应用中具有更强的鲁棒性,能够适配更复杂的模型行为。
最基础的 Prefix Caching 要求前缀完全匹配,但在真实应用中,用户请求可能仅相差几个字符,或者因编码问题存在轻微差异,导致无法命中 KV Cache。尽管这些请求在语义上高度相似,传统缓存机制也无法直接复用。对此,我们可以引入语义级匹配机制,通过识别最长公共前缀或相似语义段,并配合小范围重算,进一步提高缓存命中率与整体性能。
以 KV Cache 为中心的 LLM 推理架构
 <!---->
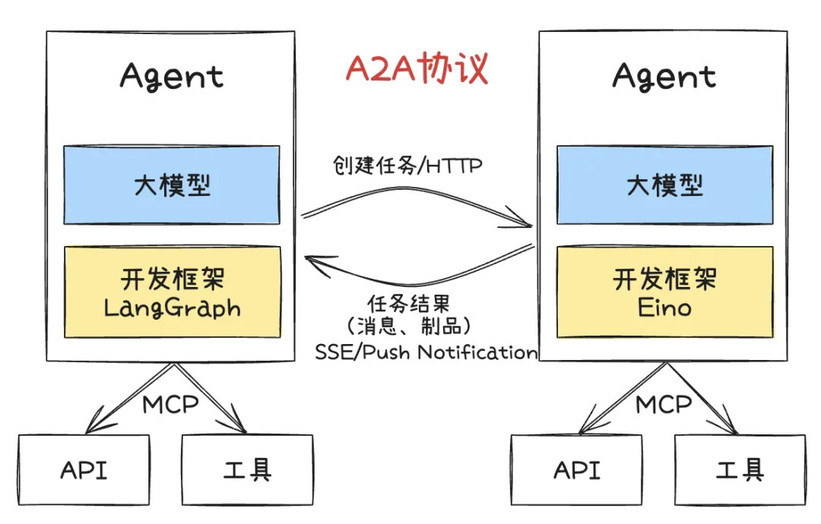
<!---->围绕 KV Cache 的推理优化方法,可以大致划分为以下四个阶段,每一阶段都具备可挖掘的优化空间:
第一阶段:KV Cache 生成(KV Cache Generation)
传统方法通常采用 Full Attention 来计算生成 KV Cache,此过程计算量大、延迟高。为了提升效率,可以从 token 粒度出发进行多种优化:
Prompt 压缩:对冗长提示词中的低贡献部分进行截断或重构;
注意力结构替换:例如将标准 Attention 替换为线性 Attention 等近似模块,降低计算复杂度;
动态稀疏化(Dynamic Sparsification):基于 Attention 的动态稀疏性,仅保留关键 token 间的连接,减少冗余计算。
第二阶段:KV Cache 压缩与存储前处理
在生成 KV Cache 之后、写入内存或显存之前,可进一步压缩数据以减小存储开销:
KV Cache 量化:将 KV Cache 的存储精度从 FP16 降至 INT8、甚至 2bit,在保持模型精度的同时大幅节省显存;
KV Cache 压缩:移除部分不必要 token 的 KV,对齐 KV 存储与 token 重要性,降低线性增长的显存成本。
第三阶段:KV Cache 的语义检索
KV Cache 存入缓存池后,在后续请求中进行复用时,可采用语义级召回机制,替代传统的完全匹配:通过语义哈希、向量相似度等手段,识别上下文含义相似但字面略有差异的请求;结合局部重算策略,提高 Prefix Cache 的命中率。
第四阶段:KV Cache 解码加载优化
在解码阶段,KV Cache 的加载成为显存带宽瓶颈,尤其在 GPU HBM 与 CPU DRAM 间反复搬运时会带来显著延迟。为此,可考虑在 decoding 过程中 sparse load KV cache 从而降低 memory bound issue。
 <!---->
<!---->在许多实际场景中,KV Cache 是高度可复用的,例如 repo 级别的 debugging、长上下文的问答、多轮对话,或 Self-play 推理等。但以往的相关工作普遍忽略了整个 KV Cache 的生命周期,仅关注其某一阶段的优化。而我们提出的 SCBench 明确建模了两种典型的共享上下文模式。
第一种最常见的场景是多轮对话:用户可能会基于同一个上下文(如一个大型代码库)连续追问多个问题,产生多个请求。
第二种场景出现在企业级内部应用中:公司内部的文档资源可能被多个开发人员反复查询,尽管每个人提出的问题不尽相同,但它们通常都围绕同一 code base 展开,具有高度的上下文重叠。
针对这两类场景,我们分别构建了两种共享上下文模式,并据此提出系统化的评测方法。为了更全面地评估模型在长上下文环境下的表现,我们进一步定义了多个能力等级,包括:字符串级的上下文召回;语义级的上下文召回;基于自然语言描述召回相关代码库的能力;面向复杂文档的问答能力。
 <!---->
<!---->第二类能力是 Global Information 理解能力,用于评估模型是否能够有效提取和利用上下文中的全局关键信息。这类能力常出现在 many-shot 的 ICL(In-Context Learning)、内容汇总任务,或者基于长上下文进行的复杂数学推理等应用中。
第三类是 多任务处理能力。在真实场景中,用户往往会在一次会话中提出多个不同类型的问题,问题种类之间存在频繁切换。这要求模型不仅要具备对话上下文的保持能力,还需具备在多个任务之间灵活切换的能力。
将上述三类能力与前文提出的两种共享上下文模式相结合,构成了我们提出的 SCBench。该基准测试共包含 12 个子任务,覆盖 13 种主流长上下文建模方法,并纳入了此前提到的 四类 KV Cache 优化策略,旨在全面衡量模型在实际长上下文推理任务中的表现。
 <!----> <!---->
<!----> <!---->我们也基于此提出了一个新的方法,名为 Tri-shape 方法。我们发现它相比之前的 A-shape 可以显著提升第一轮的指令遵循能力。
 <!---->
<!---->我们还发现了两个非常关键的结论:
第一,支持多轮解码能力必须具备 O(n) 级别的内存存储能力。
在多轮对话或推理中,若采用 token 级别的压缩策略,尽管在第一轮(Turn 0)可能表现良好,但随着对话轮次的增加,其性能将出现明显衰减。这说明,若要实现稳健的多轮响应能力,模型需要保留完整的上下文信息,单靠压缩技术无法长期维持性能。
第二,在长文本生成(Long-generation)场景中,模型容易出现 distribution shift(分布漂移)问题。
具体表现为:模型在生成第一个 token 时关注的上下文区域,与生成第二个 token 时关注的区域存在显著偏移。这种关注点的转移可能导致生成内容在语义上出现不一致或脱节的问题,对长文本生成任务的稳定性构成挑战。
 <!---->
<!---->我们还发现对于不同任务种类,性能衰减的差异会非常大。比如说对于更细粒度的一些任务,更需要完全匹配或语义匹配时,这时性能 drop 会比较大。如果是一些更加全局的任务,可能你可以做更大的优化。
 <!---->
<!---->以上是我们关于 distribution shift 的可视化。比如说 turn 1 它关注到的信息是第二个尖峰,然后在 turn 2 它可能关注到的信息就会发生非常大的迁移,对我们的优化产生一些挑战。
以 KV 缓存为中心的高效长文本方法
这一部分会介绍我们的三个工作,包括我们在 Prefilling 和 Decoding 的优化。这些优化是基于我们的一些观察结果。
 <!---->
<!---->我们的第一个观察结果是:注意力机制本质上是高度稀疏的,并且这种稀疏性具有强烈的动态变化特征。
如图 (a) 所示,在一个 128K 的上下文窗口下,我们从中仅召回 4K 的 KV Cache,此时的稀疏率高达 96.4%。也就是说,仅使用 约 3% 的 KV Cache 即可恢复超过 95% 的 Attention Recall,表明绝大多数注意力计算实际上是冗余的。
而在图 (b) 中,我们进一步将某个上下文下激活的 KV Cache 索引(index)迁移复用于另一个上下文下的请求,结果稀疏召回率从原先的 96.4% 降低至 83.7%。尤其是在部分 Attention Head 上,稀疏率下降更加显著,对模型性能造成明显影响。这一现象表明:注意力的稀疏性不仅高度依赖具体上下文,而且在不同上下文之间具有显著差异。
值得强调的是,这种动态变化的稀疏性不仅出现在 Prefilling 阶段,在 Decoding 阶段同样存在,说明它是长上下文推理中的普遍现象,对系统优化设计具有重要启发意义。
 <!---->
<!---->我们的第二个观察结果是:注意力的稀疏性在空间结构上表现出显著的局部性(locality)特征。
结合已有研究,我们注意到注意力矩阵往往呈现出“A-shape”结构,即关注分布集中在输入序列的开头部分以及当前位置附近的局部窗口。但除了这种全局 + 局部的关注模式外,我们还发现部分 Attention Head 呈现出更特殊的空间结构:
竖线模式:表示该 Head 强烈关注少量全局关键 token;
斜线模式:可能与 RoPE 编码中的 N-gram 局部信息捕获有关;
块状局部模式:某些 Head 的关注点在空间上聚集于特定位置区域,表现为 block-level 的局部性。
这些模式在每个 Head 内具有相对固定的结构,但其具体激活区域仍会随上下文变化而动态变化,因此我们将其归类为动态稀疏(Dynamic Sparsity)。
这种带有局部性的动态稀疏特征为 GPU 加速提供了天然契机:
通过设计细粒度、结构感知的动态稀疏编译器,我们可以显著提升 Tensor Core 的利用率,从而在保持模型性能的同时获得更高的推理效率。
 <!---->
<!---->基于上述观察,我们提出了 MInference 1.0,该方法利用注意力的动态稀疏性来减少实际参与计算的 token 数量,从而加速长上下文推理过程。
MInference 1.0 主要包含两个阶段:
Offline 阶段:我们对每个 Attention Head 进行模式搜索,识别其最优的稀疏结构(Pattern),以捕捉其固有的关注模式;
Online 阶段:针对已识别的模式,动态估计当前上下文下的稀疏激活区域,并在推理过程中进行加速。
在加速实现上,我们将稀疏模式融合到底层 kernel 中。例如,在 FlashAttention 基础上实现 blockwise 的稀疏计算,并结合 PIT,对注意力权重进行变换与重构,以实现更细粒度的计算优化。
通过上述方法,MInference 1.0 最高可实现 10 倍加速,将原本需要 30 分钟的推理任务压缩至 3 分钟内完成。在实际部署中,我们将原本需要 60 张 A100 GPU 才能完成的 1M token、20 秒延迟级别的推理服务,缩减为仅需 8 张 A100,即单节点即可完成服务部署,大幅降低了算力需求和成本。
 <!---->
<!---->对于性能评估,我们测试了不同的 Benchmark,在不同的 depth 和上下文窗口下它的表现都非常好。我们也测了一些非常难的任务,可以看到它的性能非常接近 Full Attention,甚至有些时候还会超过 Full Attention。
 <!---->
<!---->我们还测试了它在端到端场景和微 Benchamrk 下它的延迟加速比,结果最多可以做到 10 倍加速,kernel 级别上我们可以做到 15 倍加速。如果是基于 CUDA 版本,大概还可以有 1.5~2 倍的提升。
在很多实际的长文本场景下,输入更多是多模态的,比如说我们会输入一些长视频或很多图片来让 LLM 帮助我们去做推理或 GUI Agent 的场景。这种场景下面临的挑战会有所不同。
 <!---->
<!---->我们的观察发现,在多模态场景中,模型的注意力机制往往表现出更明显的偏置特征,尤其是在时域(temporal)和空域(spatial)维度上。这种偏置在 Attention 模式上体现为更规整的结构,常常呈现出类似网格(grid-like)的排列。
这种网格状模式的出现,主要源于多模态输入中视频帧或图像 Patch 的结构特性:每一帧之间、每个 Patch 之间的关注关系高度相似,导致注意力分布在空间和时间维度上都形成规律性的“网格”。
然而,这种 Attention Pattern 的网格结构并不天然适配 GPU 上 Tensor Core 的计算特性。Tensor Core 更擅长处理 块状(block-wise) 的稠密矩阵运算,而网状结构的稀疏性难以直接映射到高效的 block 计算中。
针对这一问题,我们利用注意力结构中的可交换性(permutation invariance),在行和列两个维度上对网格模式进行变换重排,从而将其重新映射为更适合 Tensor Core 加速的块状结构,有效提升了计算效率。
 <!---->
<!---->我们的第二个观察发现是在更加复杂的多模态场景下,输入往往并非单一模态(如纯视频或纯文本),而是呈现出混合输入的特征。例如,一个用户可能首先向 LLM 输入一段较长的视频,接着让模型生成图像内容,再将生成的图像反向输入模型继续推理。在这种交互式的流程中,模型所接收到的是多个模态交错组成的混合输入。
在这种混合输入场景下,不同模态之间会形成明显的模态边界(modality boundary)。根据我们的分析,这些边界可大致分为三类:
仅影响 K 轴(Key) 的边界;
仅影响 Q 轴(Query) 的边界;
同时影响 Q 和 K 两轴 的复合边界。
这些边界会打破原始的注意力结构,导致计算效率下降、注意力模式紊乱等问题。
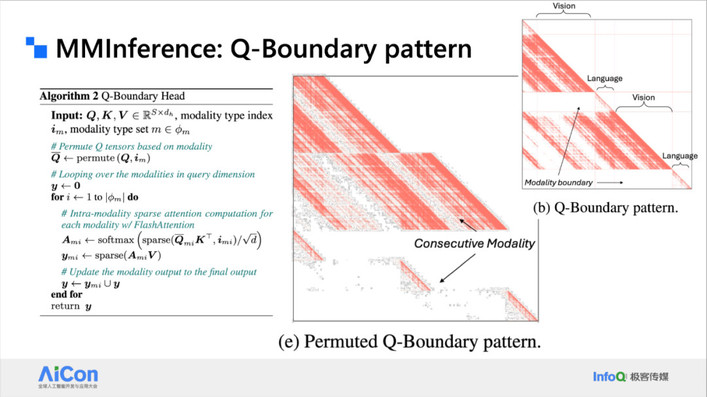
为了解决上述挑战,我们提出了一种基于 Permutation(排列变换) 的方法。考虑到实际应用中模态数量是有限的(如音频、视频、文本等),我们可以通过对输入顺序进行排列重组,将不同模态在注意力结构中局部聚合,使得原本割裂的模态区域在计算图中更加紧凑。这种方式不仅有助于恢复注意力结构的局部性,还可以显著降低计算复杂度,提升多模态混合输入下的推理效率。
 <!---->
<!---->基于这一点我们提出了 MMInference。它是由两个级别的 Attention 来处理,包括模态之间和模态内部的 Attention Pattern。对于网状模式,我们通过置换将它置换到最下和最右边,通过一些密集三角形来处理,这种 dense 的计算是 GPU 友好的。
 <!---->
<!---->我们还将现有的多种动态稀疏注意力(Dynamic Sparse Attention)方法统一到了一个通用框架中。该框架将所有动态稀疏方法划分为三个标准步骤:
模式定义(Pattern Definition):首先,基于对注意力行为的观察,我们为每种方法定义其对应的稀疏模式。例如,有的模式强调局部窗口,有的偏好全局 token 或语义 token,这一步决定了稀疏结构的基本形态。
稀疏估计(Sparse Estimation):第二步是动态估计哪些位置的注意力连接会被激活。这个估计过程的计算复杂度可以是 (例如基于 token 重要性的轻量估计),也可以是 (如基于先验 Attention 分布的精确模拟),具体取决于目标场景与精度需求。
内核融合与调度优化(Kernel Integration & Scheduling):在获得稀疏 Index 后,我们将其融合到底层计算内核中进行优化。由于 Tensor Core 更擅长执行稠密计算,我们会在真正进入计算前对数据进行稀疏 -aware 的置换(permutation)与调度,尽可能将稀疏模式映射为连续、块状的数据块。
特别是在解码阶段,内存带宽成为主要瓶颈。通过上述稀疏置换优化,显著降低了解码时的加载与访存开销,从而有效缩短推理延迟。当数据加载完成后,送入 Tile 的就是结构良好的密集计算块,可充分发挥 Tensor Core 的计算性能。
 <!---->
<!---->以上是一些置换的细节,我们实际上就是做了一些 Index 的 shifting,比如说跳行或跳列读取,然后我们就可以把竖线和斜线置换成非常密集的三角形。
 <!---->
<!---->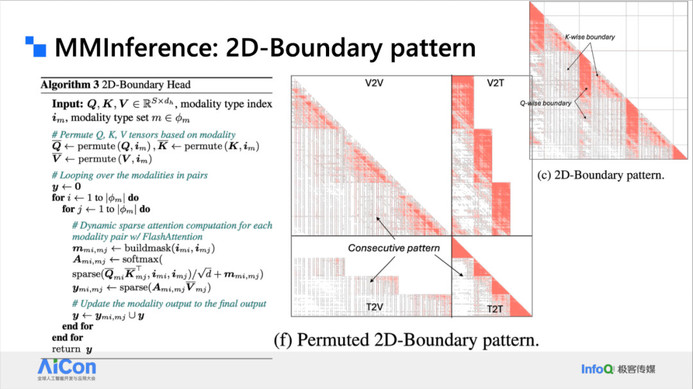 <!---->
<!---->对于不同的模态约束而言,我们也是做类似的变换。
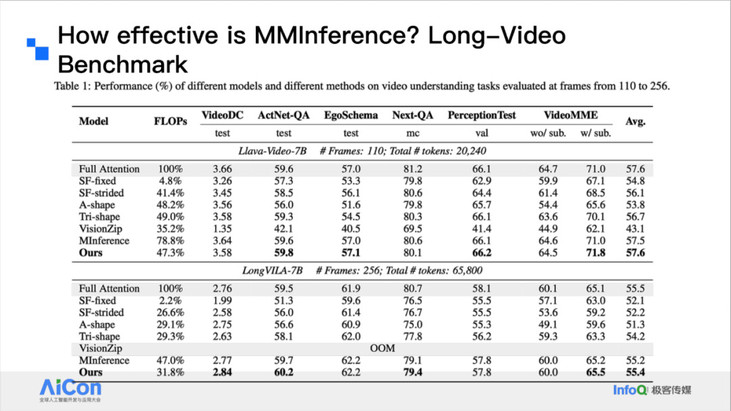
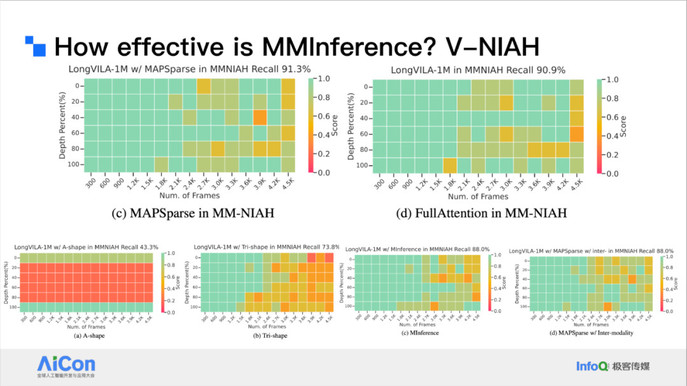
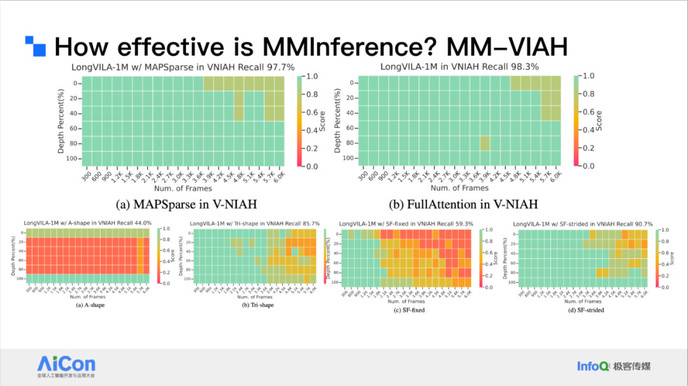
我们也评测了一些复杂场景下它的性能,包括视频理解场景、视频中穿插文本的混合模态场景等。我们也测试了延迟和 Micro Benchmark。
 <!---->
<!----> <!---->
<!----> <!---->
<!---->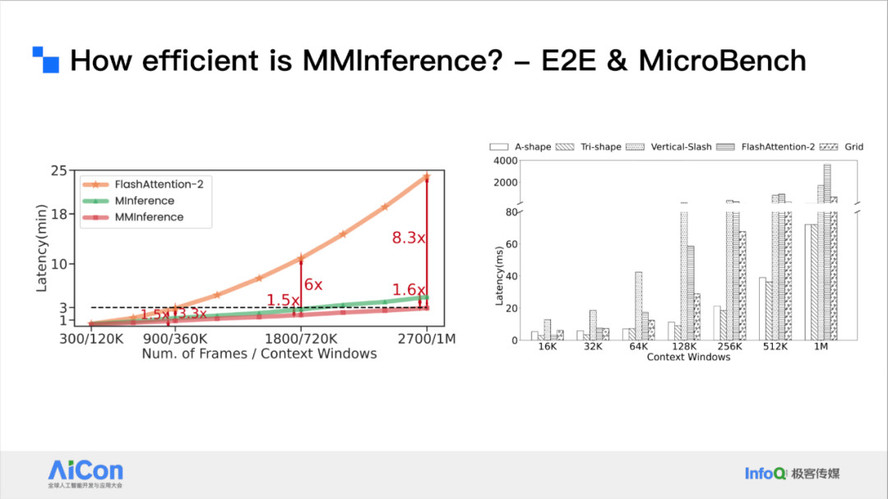 <!---->
<!---->结果发现它最多可以做到 8.3 倍端到端的加速,相对于之前的单文本方法会有 1.6 倍的加速。
我们也做了一些分析,研究动态稀疏模式如何从纯文本的竖线斜线 shifting 到更加规整的网状形态。
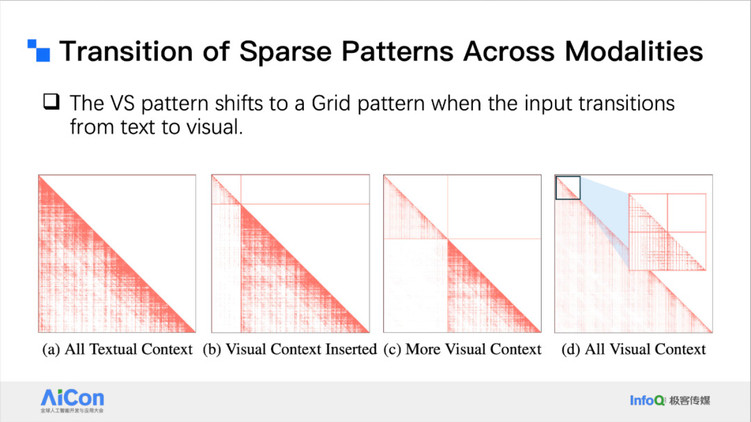 <!---->
<!---->在 MInference 发布之后,社区对动态稀疏注意力及其高效推理方法的关注显著提升,陆续出现了许多类似方向的工作。整体来看,这些方法大致可以归类为几个方向:
第一类方法关注于如何使用更细粒度的估计策略来提升稀疏模式的准确性。最初的假设是:某一 Attention Head 的稀疏结构相对稳定,可以提前静态建模。然而,我们的进一步观察发现,在不同输入上下文和任务场景下,稀疏结构可能会发生动态变化。
为应对这种动态性,新的方法尝试引入更加灵活的估计机制。例如,采用 top-p(或 Top-K)策略 对注意力权重进行动态筛选,或者根据请求本身的内容特征估算其所需的计算资源。这类策略在稀疏性建模时不仅能保留关键路径,还能根据上下文或 token 重要性自适应调整计算范围,实现更加精细化的推理资源分配。
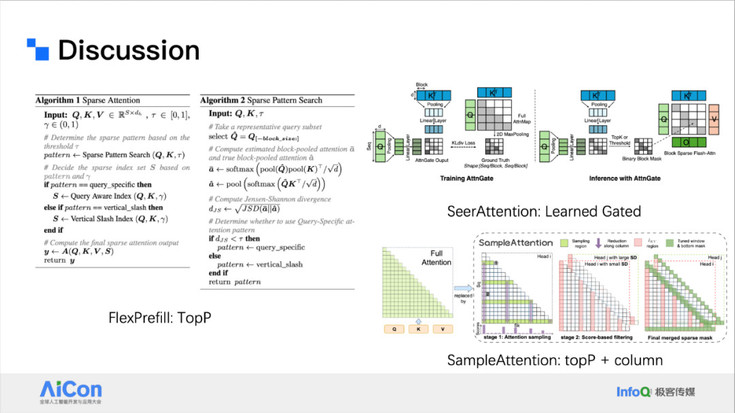 <!---->
<!---->第二类方法则侧重于在估计阶段引入参数化,以提升稀疏结构预测的准确性与效率。相比于复杂的全局估计方法,这些策略尝试通过更简洁、可扩展的方式进行建模,例如结合 Top-P 策略与 Column-Level 的注意力模式估计,在保留关键注意力路径的同时大幅减少冗余计算,实现估计过程的线性化。
第三类方向关注于将稀疏建模方法反哺至模型训练阶段,实现训练效率与推理效率的协同优化。典型代表包括:DeepSeek 的 NSA(Neural Sparse Attention):将稀疏注意力结构直接纳入训练流程,引导模型学习更加稀疏、可预测的注意力模式; Moonshot 的 MoBA(Mixture of Blockwise Attention):以稀疏 block 结构为基本单元,引入 block 级稀疏性建模,并在训练中对 block pattern 进行动态调度。
这类方法表明,稀疏建模不仅可以作为推理阶段的优化手段,还可以通过训练阶段的结构引导,在长文本任务中显著提升模型性能与效率,实现训练–推理的一体化协同设计。
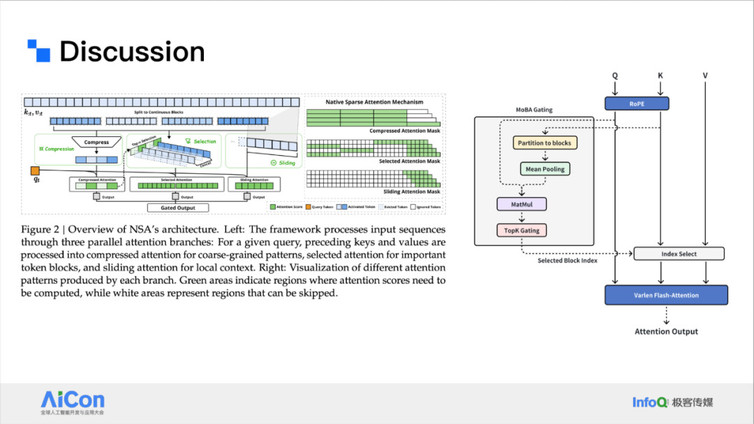 <!---->
<!---->此外,在视频或图像生成的场景中,也会使用类似动态稀疏注意力的方法实现加速。
 <!---->
<!---->比如说像快手可灵这种场景,我们要生成一个非常长的视频,它的上下文窗口也非常长。快手的上下文可能在几百 k 量级,但就计算而言它的稀疏性也非常大。针对这一点,整个社区也做了类似的一些优化。
动态稀疏方法也可以用在解码阶段。因为注意力非常稀疏,这种稀疏就可以分解成 topK 和 topK 的计算。topK 又非常适合利用向量 index 来处理。
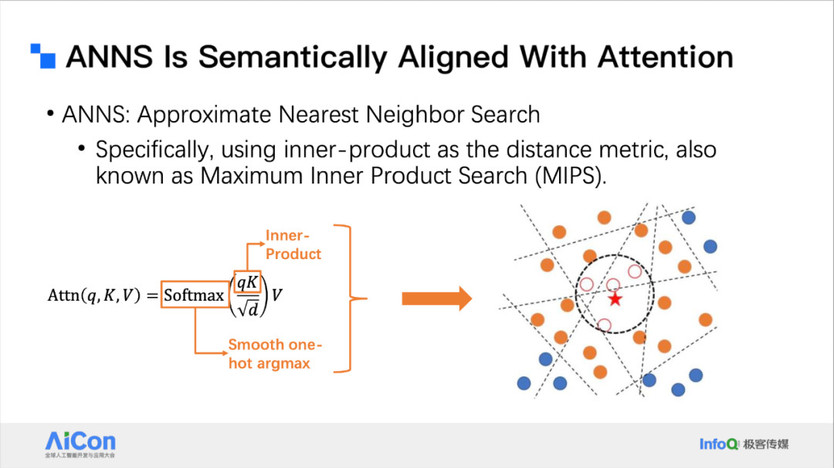 <!---->
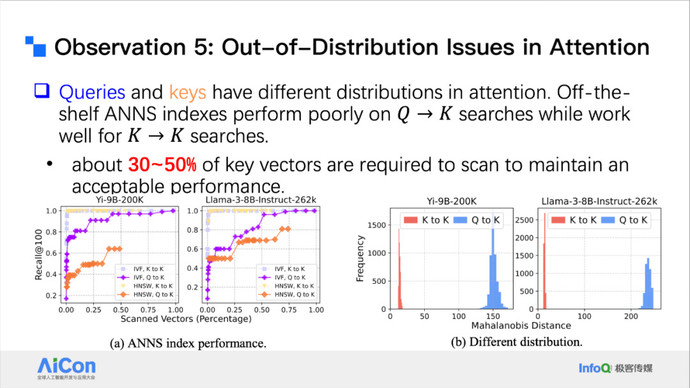
<!---->基于上述背景,我们进一步开展了相关研究,重点关注稀疏注意力检索中的索引机制设计问题。我们发现,传统向量索引(vector index)方法很难直接应用于注意力机制中,其主要原因在于存在明显的 Out-of-Distribution(OOD)问题。
在一般检索任务中,Query 和 Key 的分布相对一致,因此向量索引可有效工作。但在注意力机制中,Query 的分布往往与 Key 显著不同,特别是在不同位置、不同层或不同模态下,Query 表征可能具有更强的语义偏移或上下文依赖性。
我们实验发现:如果希望向量索引在注意力中达到较高的召回率(例如 95% 的 Attention Recall),实际需要扫描超过 50% 的 Key 向量。这使得原本期望通过 top-K 检索获得的计算复杂度优势基本消失,难以实现理论上的 O(log n) 检索加速,甚至带来额外的计算与调度开销。
 <!---->
<!---->为了解决这一点,我们提出了 RetrievalAttention 方法。它是一个 GPU 和 CPU 的联合执行方案,我们可以用一个非常低端的 GPU 加上一些还比较强大的 CPU 来替代一些高端 GPU。比如说我们可以在 4090 上推理 128k 的长文本推理。在 Prefilling 阶段,因为其计算特别慢,我们在它算 flash Attention 的同时,把 KV Cache 搬到 CPU,在 CPU 里构建好标定好向量 index。
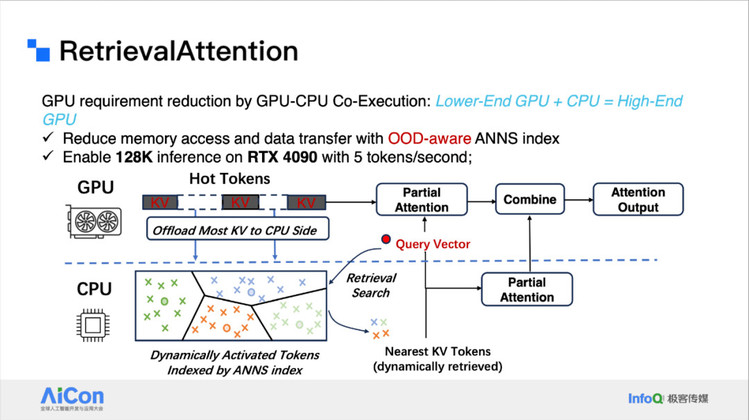 <!---->
<!---->当解码时,新的 query 生成的时候,我们把 query vector 搬到 CPU 去查询 topK,和只算 topK 的部分注意力,也就是 Partial Attention。因为它的计算量很小,所以在 CPU 上面算也不太慢。通过这样的方法我们就可以做到在 4090 上每秒 5 token 的推理速度。
 <!---->
<!---->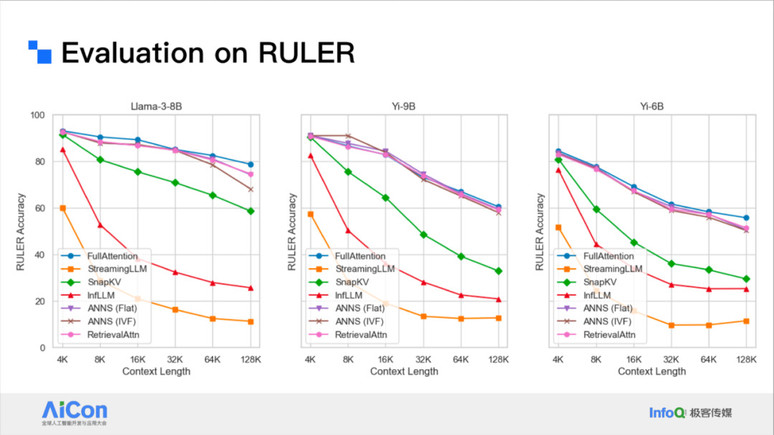 <!---->
<!---->上图是对应的性能结果。我们的方法也可以用于 Long generation 场景。
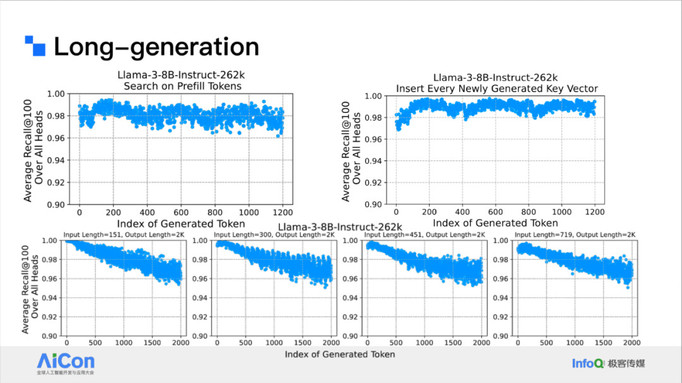 <!---->
<!---->在这个场景下我们可能需要做一些 index 更新。
总结与展望
我们从 LLMs 的推理是围绕着 KV cache 为中心进行展开,回顾了场景的 LLMs 推理方法,重点讨论了 prefix caching 相关技术。并以 KV cache 为中心对 long context methods 进行分类。并详细介绍了围绕 KV cache 为中心的分析工作 SCBench,动态稀疏注意力机制工作 MInference,MMInference,RetrievalAttention 等工作。
我们的工作发表了很多顶级会议论文,获得了很多荣誉,也被应用在 vLLM 和 SGLang 等推理框架中,以及被应用在例如 Qwen-Turbo-1M 等线上场景中。
 <!---->
<!---->展望未来,动态稀疏性除了能加速 Prefilling 和 Decoding 外,还可以用在长文本 Extension 阶段和 Long Generation 阶段来提升效率。也可以考虑将其用在强化学习训练阶段。我们也在思考将其用在预训练阶段,用更原生的这种高效架构提升训练和推理的效率。
嘉宾介绍
姜慧强,微软亚洲研究院研究开发工程师。姜慧强毕业于北京大学。研究聚焦于系统与算法的联合优化,以及高效推理和训练方法的探索,涵盖多个前沿领域,包括动态稀疏注意力机制(如 MInference 和 RetrievalAttention)、KV 缓存优化(SCBench)、提示压缩(LLMLingua)、稀疏推理(PIT)、推测性解码、模型压缩、神经架构搜索和高效微调等。在 ICLR、NeurIPS、ICML, SOSP、ACL、EMNLP、ICCV 等国际顶级会议上发表了数十篇高水平论文,并以领域主席和审稿人的身份积极参与学术社区的建设和服务。