在过去的大模型实践中,我们重塑了软件开发范式,从人工编码逐步转为辅助编码,从最初的工具逐步进化为智能编程助手,编码的体验在飞速发展。
在演进的过程中,逐步延伸出了性能、安全、成本等当下的核心问题,而随着系统复杂度的提升和业务定制化需求增强,工具和 Agent 的生态能力逐渐成为提升工程效率、增强平台能力的关键,是未来发展的基石。
本文整理自字节跳动 Trae 架构师陈仲寅在 AICon 2025 上海 的分享 “打造可扩展的生态体系:从 MCP 到 Agent 集成的实践与趋势”。本次分享将深入探讨如何通过 MCP 以及 Agent 构建一个可扩展的生态体系,内容涵盖自定义 Agent 的设计与接入方式、如何与一方内部工具集成、MCP 等三方生态工具如何共建。同时,也将展望下一阶段的技术演进方向,包括语言无关的能力扩展方式与云原生场景下的新挑战。
8 月 22~23 日的 AICon 深圳站 将以 “探索 AI 应用边界” 为主题,聚焦 Agent、多模态、AI 产品设计等热门方向,围绕企业如何通过大模型降低成本、提升经营效率的实际应用案例,邀请来自头部企业、大厂以及明星创业公司的专家,带来一线的大模型实践经验和前沿洞察。一起探索 AI 应用的更多可能,发掘 AI 驱动业务增长的新路径!
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
最近,AI agent 这一话题非常火热。Trae 作为国内较为知名的 AI IDE,已经在这一领域积累了不少实践经验。今年 4 月中下旬,我们发布了大版本更新,除了原本主要负责聊天的“chat”和负责写代码的“builder”这两个 agent 外,还新增了 MCP 模式和自定义 Agent 模式。这些新功能极大地拓展了用户的应用场景。
今天的分享将从 AI 与 IDE、Agent 与 IDE 的关系入手,逐步介绍我们的 Agent 在 IDE 中的细节情况以及演进过程。最后,我会探讨 Agent 中的 tool 如何与第一方和第三方 tool 相结合,其中的难点、落地问题以及协作过程。此外,我还会列举一些案例,展示实际效果,并对未来进行展望。
Al 与 IDE
Trae 是今年年后首次对外发布的产品,至今不过三个多月,是一款非常年轻的产品。在 Trae 出现之前,我们使用传统的 IDE 进行代码开发。在信息化时代之前,我们甚至使用打孔机和编织器记录数据,那时还没有代码和 IDE 的概念。
随着信息时代的到来,开发者和集成开发环境的概念才逐渐形成。当时,开发工具主要分为两类:文本编辑器和集成开发环境。文本编辑器如 Vim 和 Ultra Editor,并非专为编码设计。而以微软的 Visual Studio 为代表的集成开发环境则功能强大、集成度高。
此外,Java 领域出现了 Eclipse、NetBeans,JetBrains 的 WebStorm 和 IDEA 等工具,它们都以功能全面著称。
然而,随着硬盘存储成本的增加,人们发现无需使用如此笨重的集成环境,轻量化的编辑器逐渐受到关注。例如,Atom、VSCode 等轻量化 IDE 通过插件扩展支持多种编程语言,使 IDE 从“大而全”向“轻快”转变,甚至融入了标准化和开源的理念。
 <!---->
<!---->从去年开始,AI 技术迅速发展,相关产品层出不穷。从 GitHub 的 Copilot 到 Cursor,再到我们的 Trae,都朝着 AI 与 IDE 结合的方向发展。最初,人们对 AI 的预期仅限于聊天对话,未意识到其对 IDE 的巨大影响。
随着 AI 能力的增强,例如 Claude 4 的发布,人们对 AI 编程的需求不断增加,主要体现在两个方面:一是代码补全,例如在补全代码后,光标自动跳转到下一行并预测用户下一步操作,甚至修改代码;二是在不同场景下提供辅助决策,帮助用户快速理解项目文件结构或总结,通过联网获取更准确的信息,以辅助而非直接影响代码编写。
在代码补全方面,AI 时代的交互形态与以往大不相同。以 GitHub 的 Copilot 为例,传统方式是通过 IDE 索引 API 实现补全,用户需要点击弹出引导。而如今,交互方式转变为“ghost text”(幽灵代码),用户只需按下 Tab 键即可完成补全,这种正反馈非常强烈。
Cursor 的多点补全能力则是 AI 编程的进一步演进,它通过 AI 预测下一个编辑位置和内容,让用户获得更爽的体验,这也是 Cursor 受欢迎的原因之一。我希望 Trae 也能具备这种能力。
 <!---->
<!---->代码问答方面,ChatGPT 作为先行者,以 Chat Bot 形式集成问答功能,不仅可以回答问题,还能帮助用户学习新语言、生成代码、查看报错信息,甚至替代了部分谷歌搜索和 Stack Overflow 的功能。GPT 不仅满足于代码问答,还推出了 Code Interpreter 功能,将代码编辑区域集成到 APP 中,允许模型在类似沙箱的环境中执行 Python 代码。
其他竞品也在朝着类似方向努力,例如 Claude 的 Artifacts 和 GPT 的 Canvas 画布,这些功能都在尝试拓展 AI 的编辑能力,但目前仍处于早期尝试阶段,尚未形成完善的应用。
 <!---->
<!---->AI 与 IDE 的结合目前看起来是最完善的方式,尤其是对于程序员来说。它让用户问答交互更加自然,无需切换窗口拷贝粘贴,所有操作都可以在一个 IDE 中完成,更贴近开发者习惯。
同时,我们还可以整合上下文环境,快速获取 IDE 中的仓库目录结构、文件内容、终端输入输出等信息,使上下文更加完整。目前,AI 编程 IDE 呈现出欣欣向荣的状态,例如 Cursor、Windsurf 和我们的 Trae,都在朝着这个方向努力。
尽管 Trae 仅发布了三个月,但迭代速度非常快。最初,我们仅支持代码问答的 chat 模式,用户需要手动将代码应用到编辑器中,这类似于手动挡。随后,我们发布了 Builder 模式,可以自动读取代码、生成代码并修改编辑器内容,甚至在编辑器报错时自动修复,还能打开浏览器和终端,实现了从手动挡到自动挡的转变。
在 4 月份的大版本更新中,我们对 chat 模式和 Builder 模式进行了升级,新增了 MCP 能力和自定义 Agent 模式。MCP 包含大量第三方工具定义,这些定义会塞入系统提示中,导致提示内容膨胀。
为了稳定性,我们将 MCP 单独抽离为一个 Agent,与 Builder 分离。自定义 Agent 模式也非常有趣,用户可以添加自定义系统提示词和选择的 MCP 工具,使其成为专属的 Agent。
 <!---->
<!---->以两个 Agent 为例,第一个是我们创建的 FE Master Agent,它集成了 Figma 的 MCP,据统计,超过 50% 的用户首次使用时会将 Figma 转换为前端代码。第二个是 Change Log Agent,它可以自动生成变更日志,这在通用 Builder 中很难完成,除非编写大量提示词。
现在,我们开放了这一能力,用户可以在自定义 Agent 中轻松完成。这些自定义 Agent 切实改变了研发流程。我个人非常喜欢的一个功能是,在开发完成后,让 Agent 生成 diff 文档,告诉后续的同事我修改了哪些代码,供他们参考。
Agent 与 IDE
首先,让我们来看看大家通常认为的 Agent 的样子。Anthropic 提出的 Agent 概念本质上是一个大循环。我重新绘制了这个循环的上半部分,Agent 实际上是主体的包部分,包括几个大的模块:第一个是感知,第二个是中间的规划和决策。Agent 需要外部信息的输入,就像人一样,它需要外界的状态、记忆体验,以及我们输入的知识。
基于这些信息,Agent 最终会根据决策结果产生策略并执行。当然,在执行过程中,可能会出现错误、中断、异常或失败。此时,就需要一个补偿的 retry 机制,让 Agent 返回到上一步。这就是 Agent 本身的工作流程。
第二部分是环境部分,环境部分主要负责调用外部的 Tool。这些 Tool 会有几种状态,比如成功或失败。
我们会根据成功或失败来奖励或加强反馈的整个过程,然后将结果再反馈给 Agent,从而形成一个完整的循环。可以看到,最重要的两个部分是 Action 和 Feedback,这其实也是 Agent 工作流中最重要的两个部分。
 <!---->
<!---->不同的应用场景下,Agent 的组成和实现方式会有所不同。在实际的 IDE Agent 设计中,我们更多地考虑的是它的思考和调度能力,以及我们认为最重要的两个方面:工具的调用能力和 context 获取能力。
此外,我们还会考虑上下文获取以及其他一些信息。上下文其实包括几个部分:对于 AI IDE 来说,会有用户的输入、工程侧的内置固有逻辑、模型主动调用工具的结果,以及历史的长期记忆和短期记忆。这些共同构成了我们整个上下文体系。
 <!---->
<!---->目前,我们的目标是将 Agent 打造成一个专属的辅助开发工程师。然而,这件事并不简单,我们只是在逐步演进并改变用户习惯。虽然模型在不断进化,从 Claude 3.5、3.7 到 4,评分在不断提高,但我们仍然发现它存在不足。因为它的经验不足,我们提供的上下文不够多,所以它在写代码时经常会出错,不符合用户的习惯。
因此,目前很多人处于跷跷板的两端:一部分人非常信任模型,将其放在所谓的 Builder 模式中,让它完全自动化运行;而另一部分人则不太信任模型,觉得模型对他们有较大干扰,宁愿手动操作。这就形成了两个不同的派系,或者说两种不同的使用方式,这种情况非常常见。
昨天有个讲师提到,一些写传统语言的同学特别抗拒使用 AI,即使使用 AI,也要把控每一个流程;而另一些同学则完全信任 AI,从 0 到 1 完全由 AI 生成。这就是两个非常明显的派别。
下图展示了整个 AI Agent 聊天面板的细节分解。从对话框中我们可以看到几个重要部分:用户交互层和核心功能层。用户交互层包括用户对话管理,即左边看到的 Input 和 Output 的对话信息。Project 层是工程侧的一个虚拟概念,对应一个大项目。
Proposal 对应的是意图分解,比如模型拿到需求后,第一步要去理解用户的需求。如果是一个简单的通用任务,比如询问天气,它就不属于 Coding 流程,所以需要单独分解。第二个是 tool call 的调用,后面我们会讲到,每次 Plan 阶段的调用都会是 Tool call。
Plan 是一个计划分解,我们会把用户的需求,比如做一个网站,分解为几个步骤:第一步搭建脚手架,第二步创建目录,第三步写入文件。Step shot 快照可能用户看到的比较少,但它潜移默化地存在于我们的项目结构中,它可以让我们整个项目代码更加稳定。
当 AI 写错文件时,它可以快速回滚到第一轮、第二轮、第三轮,类似于 Git 的概念。Understanding 是一个项目理解模块。再底层是一些基础能力层,比如调用大模型加密,我们有一些 CKG 知识图谱,以及数据库的本地存储。最后是远端的大模型提供。
 <!---->
<!---->整个 AI Agent 最重要的能力是思考规划、执行以及观察反馈的循环。这个大图其实就是反馈循环在 AI Agent 上的更细节的落地。
整个 AI Agent 的工程能力分为几个部分:第一部分是用户提出需求后,需求到达 Agent 本身,这是一个从 proposal 到 plan 的解释流程。它先做意图识别,如果是常规问答就简单回答;如果不是常规问答,就会进入 plan 阶段,分析代码并给出提案。Plan 过程中可能会有 Plan 1、Plan 2、Plan 3,它会构造一个 Prompt 发给大模型。在发给大模型时,大模型的信息一直在思考,并以流式输出返回给 agent。
此时,Agent 有两个动作:一个是渲染给前端,给前端发一个事件说要展示一个卡片对应到 Tool Code 调用;第二个是执行 Tool 的过程。
所以,执行 Tool 和给前端渲染是两个并行的流程。这个大致流程与 Agent 之前所说的概念流程几乎一致,但在不同场景的实现中,比如在 AI Coding 的编辑器实现中,其实是不一样的,因为那个只是概念,而这是实际的落地。
 <!---->
<!---->IDE 中有许多内置工具,比如我们的一方工具文件。首先是文件操作工具,文件分为增、删、改,也就是 write 部分工具,我们单独将其分为一类。第二个是文件查看,也就是 read 工具,剩下的还有一些文件搜索、关键词搜索。第二块是终端命令工具,主要与 IDE 能力相关,叫 Terminal 工具。
Terminal 工具主要有两个:一个是 run terminal,一个是 get terminal output,即获取 Terminal 结果。第三块是代码检索工具,可能是关键词检索、代码知识检索,这是项目理解的部分。第四块是项目结构本身的检索,比如文件目录的创建、l 把目录树打出来等,这些都属于项目管理工具。在实际调用过程中,用户 IDE 的消息输入后,会经过大模型的整体分析。我们之前已经提到过,它会有一个意图理解以及 Plan 计划步骤,最终实际调用到我们工具 Tool 层面。
它会将执行消息发送给 IDE 右侧来实现,使其能够在 IDE 中展示对应结果。同时会给当前 UI 推送一个工具卡片,使其能够在 IDE 中展示对应框架。卡片就是当文件写入时,我们会有一个圈圈在 loading,因为那时大模型还没结束,但我们知道要改哪个文件,所以会先预先填一个 UI,让用户感知,否则用户会卡在那里黑屏很久。
这是一个增强体验的过程。在大模型工具调用结束后,卡片的结果才会真正被写入。这就是一个流式的过程,在此之前它是一个 loading 状态,这就是工具执行流程。
<!---->目前,所有工具在大模型中都保持了一个固定的结构。我们来细看一下工具到底是什么。
所谓的工具,其实是一个包裹在 XML 标签中的描述信息,分为几大块:一块是基本工具,比如工具的名字、工具的 Description 描述;另一块是比较重要的,代表工具到底能干什么、它的流程是什么以及它的入参是什么;还有一块可能是 Few Shot,我们要告诉大模型这个工具的示例是怎么调用的、能干什么。基本上所有工具都是这样的模式。
有人会问,既然有些模型支持 Native Function Call,因为我们支持几乎所有模型,包括市面上国内的 DeepSeek、谷歌的 Germany、Claude 系列等。有些模型可能不支持 Native Function Call,所以为了这些模型的兼容性,我们采用了在 System Prompt 里面构造 Tool List 的方式,将整个 Tool 的结构描述出来。
这也是为什么之前提到会有 Builder with MCP 的问题,因为 MCP 的 Tool 和这个一样都要放在一个很大的 prompt 里面,造成 prompt context 不够,就会出现问题。
 <!---->
<!---->Tool 与 Agent 的演进
在我们的开发过程中,最迫切需要解决的问题之一是工具的复用性。许多用户向我们反馈,虽然现有的工具调用功能已经很好,但他们希望将自己开发的工具集成到 IDE 中供更多人使用。这在当时让我们感到非常困扰。然而,就在 3 月份,MCP 的出现为我们带来了转机。
它不仅解决了如何将第一方和第三方工具混合使用的问题,还规范了标准协议,使得竞品能够迅速接入。这既满足了用户的诉求,也让我们能够跟上竞品的步伐,解决了三方工具复用的难题。为了实现这一点,我们迅速做出了决策,决定将 MCP 接入我们的系统。
MCP 的客户端接入非常方便,因为它提供了完善的 SDK,包括适用于 Node.js 和 Python 的客户端。通过 JSON RPC,我们可以直接调用 MCP,使其与我们的 Agent 紧密集成。
然而,这也带来了第一个问题:结构不一致。我们原本的工具是通过 XML 定义的,而 MCP 则通过 JSON 描述接入。由于模型的解析能力有限,这种结构差异会导致幻觉问题,模型无法理解为什么会有两种不同的结构。
为了解决这一问题,我们设计了一个名为“Run MCP”的新工具,专门用于将第三方工具和第一方工具汇聚在一起。Run MCP 的结构与之前的工具完全一致,只是它专门用于调用 MCP。
在接入第三方工具时,我们首先需要解决的是意图冲突问题,也就是所谓的“工具打架”问题。为了解决这一问题,我们设计了 Run MCP。
此外,还有一个问题是历史会话轮数超限。Run MCP 本身是一个标准的 MCP 工具,它并不特别复杂。它是由大模型生成的调用返回的 Response,以 JSON 形式展示,但其定义是 XML。核心在于 description 部分,它描述了 Run MCP 的功能,即在 MCP Server 中运行 MCP 工具并列出可用的 MCP 服务。
我们将 MCP Server 的结构放在了系统提示中,并将 Input schema 用 MCP Data 包裹起来,因为 MCP 只能以 JSON 形式存在。这样,模型能够更好地理解内容,并在需要调用 MCP 时,主动从 MCP Server 中寻找所需的 MCP 服务。模型的智能程度超出了我的预期。
 <!---->
<!---->多轮历史工具的问题仍然存在。由于 MCP 会带来历史会话的膨胀,而我们的一些模型的上下文窗口并不大,例如有些模型只有 32K,Prompt 的长度限制非常严格。
在前几次交互中,由于上下文为空,问题并不明显。但一旦达到上限,模型就会出现问题,例如输出截断、直接崩溃、无法响应等。一般来说,上下文窗口的 token 数量是输入和输出共享的,如果输入超出了限制,输出必然会减少,从而导致卡住、卡死、不输出或随意截断等问题。
为了解决这一问题,我们采取了一些措施。首先,我们对无用的信息进行了处理,例如最初的几轮用户输入和工具调用的内容。我们没有直接丢弃这些信息,因为它们在未来可能仍然有用,而是进行了压缩。我们主要压缩了历史信息,例如用户输入、助手输出以及工具调用的入参和结果。
通过这些处理,我们节省了大约 1/5 的 token 长度。当然,还有其他信息裁剪的方法,但由于与主题无关,我们在这里不再展开。
 <!---->
<!---->在第三方 MCP 工具接入后,用户遇到不支持的功能时,MCP 可以提供解决方案。然而,仅靠 MCP 是不够的,因为 MCP 只是开放了 Prompt 部分,但没有人使用。因此,我们在不影响原有系统提示的基础上,开放了一个名为“user prompt”的小段落,专门用于注入用户输入。
当然,我们加入了一些引导和限制,例如优先级限制,以确保模型不会执行某些操作。这就是大家在 4 月份看到的自定义 Agent 版本。
用户也提出了多 Agent 的需求。目前,大多数 Agent 都是单 Agent,当一个 Agent 承担过多职责时,效果必然会受到影响。
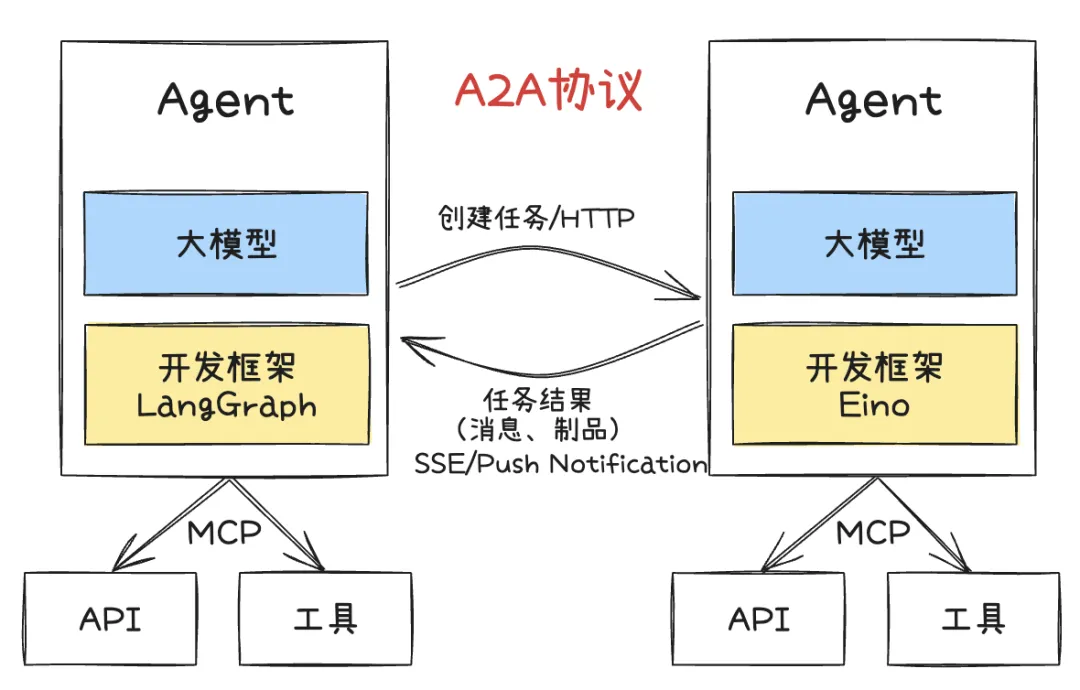
因此,我们希望将 agent 的能力分为两部分,例如,一个负责生成计划,另一个负责生成代码。我们考虑过采用社区的 AtoA 协议,但发现落地难度较大,因此最终没有选择。
在我们的实现中,我们设计了几个 Agent:一个主 Agent 和两个子 Agent。每个子 Agent 都有自己的工具来执行不同的任务。这种架构看起来很美好,但实际上却衍生出了两种形态。
第一种是 Workflow 驱动的形态,即完成第一步后进行第二步,完成第二步后进行第三步。例如,我们有一个需求 Agent,它会生成需求文档,然后将其传递给计划 Agent 进行规划设计,最后进行编码。
然而,这种架构存在一些问题,因为在每一步中,Agent 可能需要不同的用户输入,这使得这种架构不太适合以串行方式演进。
 <!---->
<!---->我们又考虑了另一种方式,即完全由大模型驱动。这也是最常见的方式,有一个父 Agent 来驱动整个流程,汇总所有子 Agent 的信息,而子 Agent 则专注于执行自己的逻辑,并将结果返回给父 Agent。
然后,父 agent 会根据这些信息决定下一步调用哪个子 Agent,以及何时结束流程。这是一个由大模型驱动的案例,目前发现效果还可以,但仍然存在一个问题:第一次调用哪个 Agent 并不容易解决。
最终,我们决定采用一种折中的方式。我们用 Workflow 的思路确保首次调用某个特定的 Agent,然后后续流程完全由模型自由发挥,根据需要调用不同的 Agent。
这种方式既遵循了首次执行某个 Agent 的流程,又为模型提供了足够的自由度,使其可以根据意图自由地执行后续的 agent。当然,这是目前最直观、最可能的实现方式,也是我们在 trae 中尝试过并能够落地的方式。
然而,随着未来模型的提升,或许在未来,我们可以完全信任模型,达到完全智能化调度的水平。因此,我们认为实际情况可能是工程和模型驱动共同协作来完成整个目标。
 <!---->
<!---->案例分享
在我们社区中,用户常常利用我们的自定义 Agent 来完成一些相当实用的任务。比如,有些用户会详细地描述需求,填写相关信息,然后借助我们的 Agent 来提交代码。
这个过程相当高效:Agent 会自动处理 issue,代写代码,随后通过 issue 提交代码,并最终自动发起 PR。整个流程涵盖了从修复代码到提交 PR 的完整环节,显得非常智能,目前也确实能够实现。
 <!---->
<!---->除了与编码直接相关的任务,我们的 Agent 还能承担一些行政助手的角色。这表明我们的 IDE 不仅仅是一个代码编辑器,它还能在用户的日常生活中发挥更广泛的作用,提供各种形式的帮助。
 <!---->
<!---->未来展望
展望未来,我们相信 AI Agent 的发展方向将是多模态融合。目前,我们的 Agent 主要依赖文本输入,但未来可能会支持更多形式的输入,比如语音等。
结合特定领域的知识建模,以及不断增强的推理能力,Agent 将变得更加智能和高效。基于现有的 MCP 协议体系,未来可扩展的工具集成以及与物理环境的交互能力也将成为可能,例如在计算机使用场景中的应用。
未来的 Agent 可能会朝着多 Agent 协作的方向发展。虽然目前 AtoA 是一种可行的方式,但未来可能会出现更多类似的 Agent 间协作模式。Agent 不仅能够自主决策和自我优化,还可能具备解决未知问题的能力。
尽管我们无法预知模型发展的最终目标,但至少有一点是明确的:大家都对模型的未来发展充满信心,相信它将为我们的工作和生活带来更多可能性。