Kontext从2025 年 5 月 29 日推出和Dev版本在2025 年 6 月 26 日 正式开源已经过去了一个多月。这篇文章将从Kontext的技术实现原理出发,让各位产品经理对Kontext有着更为全面深入的理解,更加能够抓住AI时代下各个模型的发展脉络。

开源地址(FLUX.1 Kontext [dev])
GitHub:https://github.com/black-forest-labs/flux
HuggingFace官方仓库:
https://huggingface.co/black-forest-labs/FLUX.1-Kontext-dev
FLUX.1 Kontext [max] & [pro] 使用/体验地址
BlackForestLabs官方页面(支持API调用与在线体验):
https://bfl.ai/models/flux-kontext
1.Kontext和GPT-4o图像模型的区别
在Kontext推出之前,当时“图随口变”的唯一玩家只有Chatgpt-4o画图模型。甚至可以这样说,GPT-4o开创了图像领域的一个新时代。自回归 token + 扩散解码让Chatgpt-4o画图模型在复杂文本和连续对话上有着超越当时任何一个模型的能力。而Kontext则是使用“流匹配+上下文融合”替代传统扩散模型,在很多方面甚至超越了Chatgpt-4o画图模型。
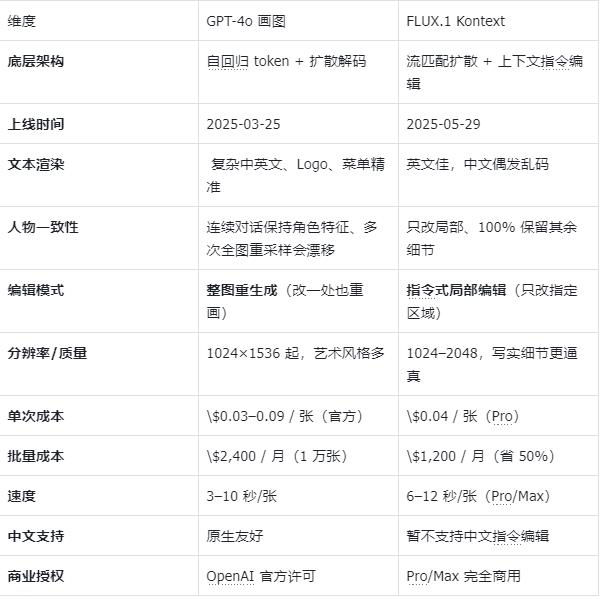
(Kontex 和 GPT-4o图像模型的区别)
在产品场景不同的需求下,在这里我给出自己的一个想法(仅供参考)
- 要做海报/Logo/含大量文字→GPT-4o
- 电商批量换色、抠图、保持SKU细节→FLUXKontextPro
- 社交媒体整活、风格化漫画→GPT-4o(风格口令灵活)
- 预算有限、每月>1万张图→FLUXKontext(成本↓50%)
- 需要连续N轮微调同一张图→FLUXKontext(局部编辑不崩)
2.Kontext的技术原理
FLUX.1 Kontext 就像一位“看图秒懂、指哪改哪”的超级修图师,你只需用平常说话的方式告诉它要改什么,它就能一口气把图修好,而且修得快、修得准。
流匹配+多模态融合+上下文感知
在 FLUX.1 Kontext 中,“流匹配 + 多模态融合 + 上下文感知”三者并非简单叠加,而是协同设计、闭环驱动的一个整体系统,目标是实现快速、精准、多轮一致的图像编辑。下面是其协同工作机制的专业拆解:
1)流匹配(Flow Matching):为整个系统提供“快且稳”的生成路径
作用:在潜在空间中建立一条从噪声到图像的确定性ODE路径,替代传统扩散模型的随机去噪过程。
优势:
- 只需4~8步即可完成高质量生成(传统模型需50+步);
- 路径平滑,适合多轮编辑中反复调用而不累积误差;
- 与上下文感知模块结合,支持局部区域的重采样,而非整张图重绘
简单来说,流匹配 = 给AI装导航,让生成图片走直线,省时间省力气。
把“流匹配”想成快递送货新路线:
- 老式扩散模型:快递员(AI)从你家(噪声图)出发,先绕城市兜50个圈(50步去噪),最后才到终点(清晰图)。
- 流匹配:直接算出一条最短直线,4步就直达终点,又快又不绕路。

(扩散模型生成图片过程)
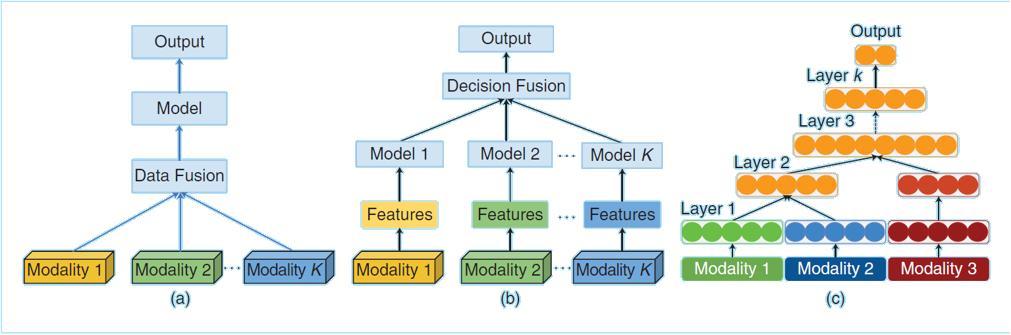
2)多模态融合(Multimodal Fusion):让文本和图像“说同一种语言
输入处理:
- 图像→由强化版VAE编码为潜在向量(保留细节);
- 文本→由T5+CLIP双编码器提取语义;
融合机制:
- 采用双流+单流混合Transformer,先将图文编码为统一语义流;
- 通过交叉注意力机制对齐文本指令与图像区域,实现“指令-像素”映射;
效果:
- 支持“将红框内的茶杯换成茶壶”这类细粒度指令;
- 在KontextBench测试中,跨模态任务得分超出基准模型42%
把“多模态融合”想像你在厨房做菜:
- 眼睛:看见锅里油冒烟。
- 鼻子:闻到糊味。
- 耳朵:听到“滋啦”声突然变大。
如果只靠一种感觉,你可能以为只是油热了,或者只是菜香。但多模态融合就像把这三条信息同时交给大脑:“烟 + 糊味 + 滋啦声”一起出现 → 立刻判断:菜要糊了,赶紧关火!在 AI 里也一样:把图像(看到的)、声音(听到的)、文字(菜谱步骤)一起喂给模型,它就能比单看图片或单看文字更快地得出“马上糊锅”的结论。
(多模态)
3)上下文感知(Context Awareness):让编辑“有记忆、有边界”
核心模块:
- 3D旋转位置编码(3DRoPE):赋予模型空间结构理解能力,知道图像中每个像素在3D空间中的相对位置;
- 上下文编码器:对输入图像进行区域重要性打分,锁定不可变区域(如人脸、主体特征)与可变区域(如背景、配饰);
行为表现:在10轮编辑后,人物特征一致性仍保持96%以上;支持对话式交互:如“先换背景,再加光影”,每轮都在上一轮基础上增量修改
把“上下文感知”想成AI 的“记忆力+分寸感”:
- 你第一次说:“把沙发换成蓝色。”AI记住了:沙发是主角,其他东西别动。
- 第二次说:“再加点靠垫。”AI知道还是同一张图,于是只在沙发上添靠垫,不会莫名其妙把墙也涂蓝。
- 第三次说:“让整体更温馨。”AI回想前两步的改动,微调灯光和色调,保持沙发和靠垫不变。
总结:
上下文感知 = AI 记得你之前说过什么、改过哪里,下一次动手时“只改该改的部分”,不越界、不翻车。
2.Kontext的落地场景
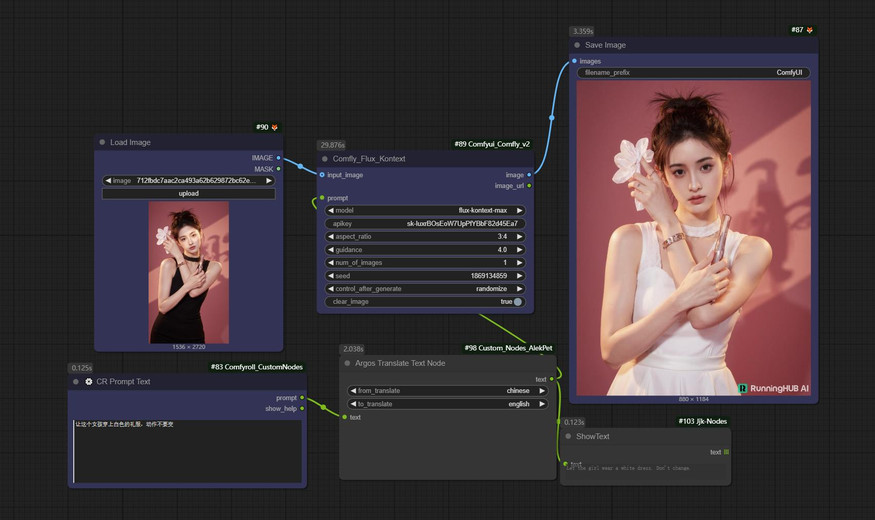
(模特服饰替换)
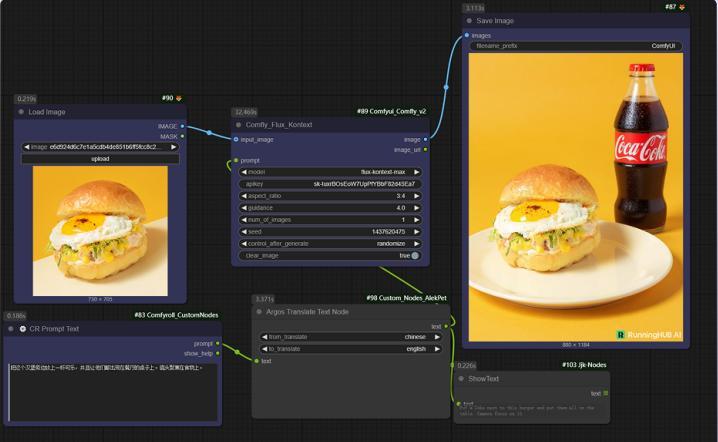
(商业海报)
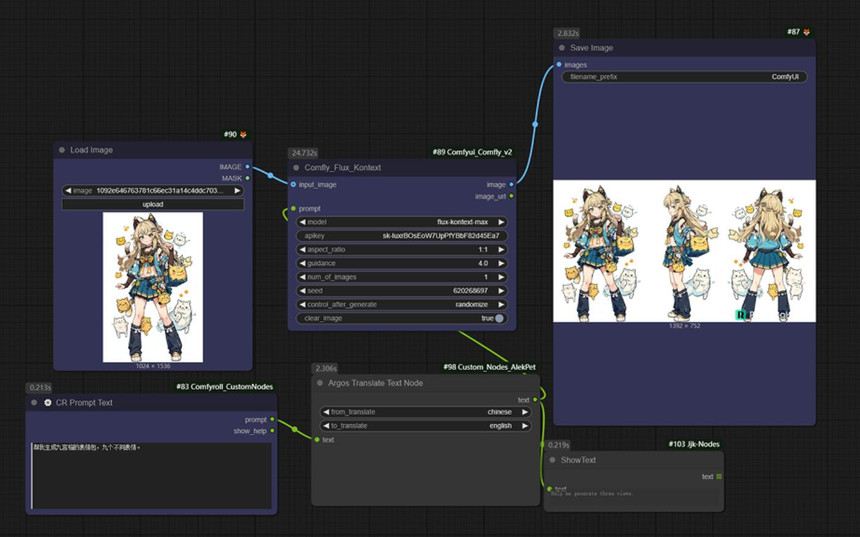
(角色三视图)
总结:FLUX.1 Kontext 像一位“记性好、反应快”的修图师:先直路狂奔(流匹配),同时听懂图文(多模态融合),再只改该改之处,其他纹丝不动(上下文感知)
本文由 @产品经理小易 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议