AI文生图技术正在改变内容创作的边界,但你真的理解它的底层原理吗?本文将从系统视角出发,带你厘清扩散模型的生成机制、关键技术路径和演化趋势,用通俗易懂的方式打开“一句话生成一张图”背后的黑盒世界。

过去这一年,AI文生图技术已经火遍全网,大家或多或少都体验过,指挥AI肆意创作的魅力。
但市面上关于文生图的介绍非常零散,网上虽然有不少科普,但大多局限于工具教学(比如怎么用Midjourney、Stable Diffusion),或者稍微讲讲扩散模型,但能把整个文生图技术链路讲清楚的系统化内容,相对较少。
这篇文章就是我作为AI从业者,把过去自己学习、工作中积累的文生图相关知识,系统性地整理出来。
我将分享哪些内容?
这篇文章不会深入讲文生图用到的向量、算法细节,而是围绕“AI是怎么理解你说的话,并一步步画出图”的流程,尽可能用简单易懂的文字,一口气讲清楚文生图的底层逻辑。
我们就一张图的生成开始说起,这是我用 GPT 4o 生成的一张图片:

Prompt:Lone Tree at Dawn: a tranquil pre-dawn landscape under a vast indigo sky, featuring a solitary tree standing calmly on the horizon. The sky fades beautifully from deep midnight blue to a warm amber glow, signaling the first light of day. In the distance, gentle silhouettes of wind turbines line the far ridge, barely visible in the dim morning haze. The composition emphasizes negative space, with the tree perfectly framed against the glowing sky. The scene evokes stillness, solitude, and quiet hope. Delicately composed, subtly lit, and cinematic in mood. clear space above the subject, –ar 21:9 –raw –profile po9pk1w
我通过截图的方式,记录了它诞生的过程:
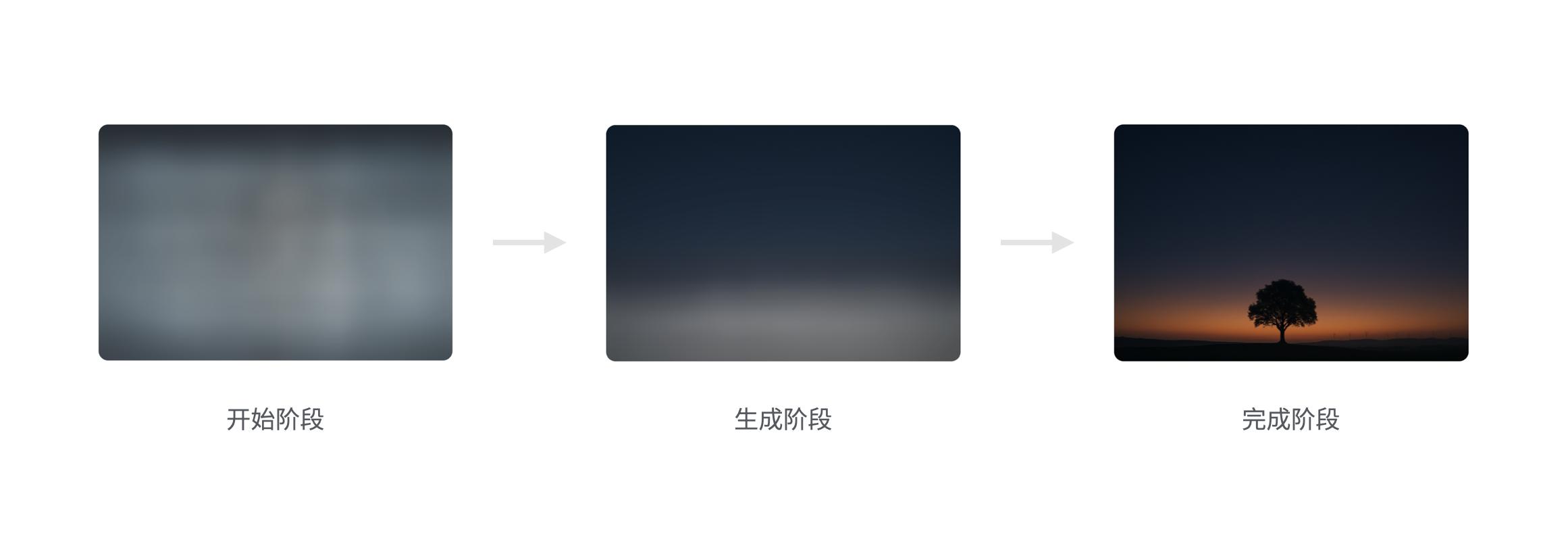
按照惯性思维来说,生成图片的过程应该是「从模糊到清晰」,是 AI 在一张模糊的草图上“逐步完善细节”。
但为什么实际情况是,从开始阶段到完成阶段,无论是色彩还是构图,都相差甚远呢?因为开始阶段的图片,是纯粹由噪声构成的。
“噪声”是什么:图像中没有任何结构和意义的随机像素点,类似于小时候电视没信号时出现的“雪花屏”,黑白点杂乱跳动,没有任何图像内容
换句话说,AI生成图片,并不是“画出来的”,而是从由噪声中“还原”出来的。
这一切究竟是怎么发生的?从文本到图片,模型到底都做了什么?
1. 文生图的起源:CLIP模型
CLIP 模型的设计目标,是打通图像和文字这两种完全不同的信息表达方式,把文字和图像映射到同一个高维向量空间中——也就是我们常说的嵌入空间(embedding space)。
CLIP 的结构包括两个独立的编码器:一个处理图像,一个处理文字。它们分别把输入内容压缩成长度相同的向量(通常是 512 维),然后通过对比学习的方式进行训练。
所谓对比学习,就是让匹配的图文对(positive pairs),比如“cat”的图片和“a photo of a cat”,之间的向量距离尽量接近;而不匹配的组合,比如“cat”的图片和“dog”的文本描述,则尽量远离。
久而久之,模型就学会了如何让「图片」和「文字」,在向量空间中相互对应。
更有意思的是,这个嵌入空间不仅能用来对齐图文信息,还支持向量之间的概念运算。
举个例子:
“一个戴帽子的人” – “一个没戴帽子的人” = “帽子”
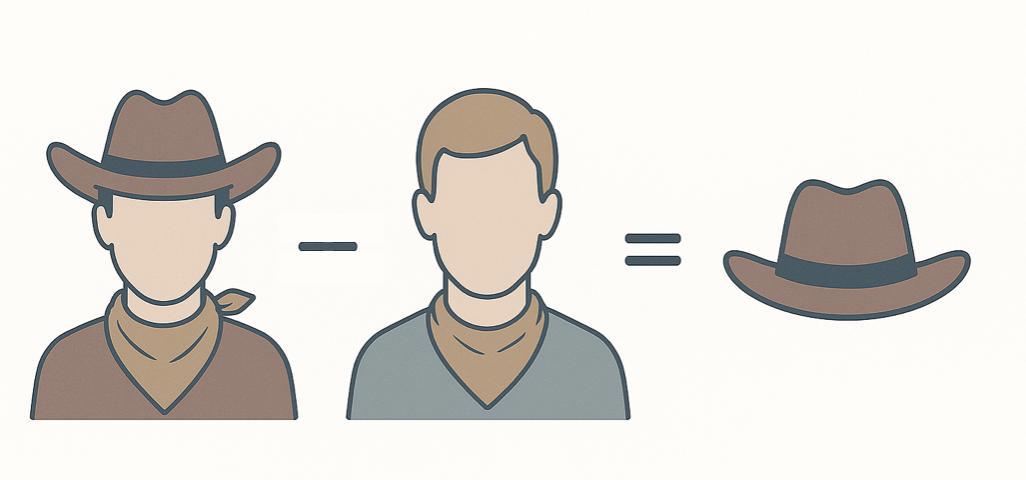
这说明 CLIP 不只是把图和字对起来,它还能识别出“帽子”这个概念,并且能够拎出来单独分析、单独处理。
然而,CLIP 虽然能读懂图像信息,也能读懂文字信息,但却不能自己提笔,根据文本信息输出图像,那AI是怎么生成图片的呢?
生成的部分,就轮到扩散模型(Diffusion Models)登场了。
2. 扩散模型:由噪声反推画面

2020年,伯克利大学的一组研究人员发表了一篇开创性论文,提出了一个听上去有些反直觉的做法:让 AI 从一堆随机噪音出发,一步步“倒推”出一张完整的图片。
这套方法被称为 DDPM ,也就是“去噪扩散概率模型”。
简单来说,他们训练模型的目标是,让模型学会一个另类的任务:不是从一张白纸开始画图,而是反过来,从一张已经被“完全打乱”的图中,把内容一点点还原回来。
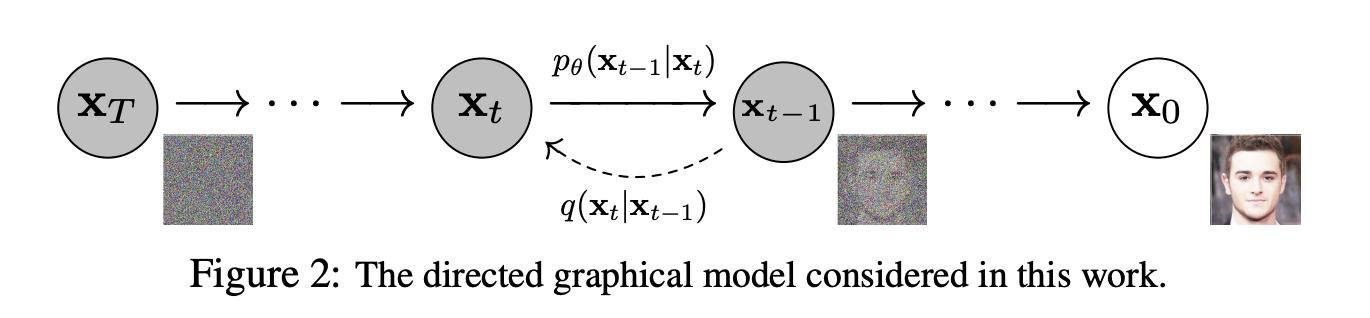
具体做法是:先从真实图片出发,逐步加入随机噪音,直到图像完全变成一张看不懂的点阵图;然后训练一个模型,按相反的顺序,一步步去掉这些噪音,最终还原原图。
这一方法的神奇之处,不只是逆向思维本身,还在于几个核心突破:

第一,伯克利团队发现:让模型一步步减少噪声,效果并不好,反而是直接预测整张图中一共加了多少噪音,然后反推,还原的速度快且准确率较高。
就像修复一张揉皱的画,与其想着一层层、一步步抚平,不如先直接告诉 AI ,它本来是什么样子,然后再揉皱,让 AI 还原,效果还更好。这是一个非常有意思的结论,我会在本文结尾处,结合一本书细聊。
第二,他们还发现,在“去噪”的每一步中,加入一点点随机噪音,反而能提高最终图像质量。
这听上去像反向操作,但其实非常关键,因为不加噪音的话,模型容易走到“平均值”的方向,也就是生成一张“最安全”的图,比如既像猫又像狗,又像山又像海,啥都有一点,但啥都不像,更像多个事物的平均值。
而如果在去噪的过程中适当加一点噪音,就像是给模型一些自由发挥的空间,它不会被困在模糊的、最保险的平均值里,最终生成更有细节、更鲜明、更真实的图像。
第三,从数学上看,这个过程其实模拟了物理里的“扩散过程”的反方向,属于一种随机微分方程的解法。沿着这条思路,研究者们还进一步提出了 DDIM(Denoising Diffusion Implicit Models),即去掉中间的随机跳动,只保留主要的还原路径。
DDIM的结果就是模型能用更少的步骤、更短的时间,生成同样质量的图像,大大减少生成步骤和算力成本。
从那之后,扩散模型真正成为生成图像的主流方法。我们今天看到的 Stable Diffusion、Midjourney、DALL·E 等等,几乎都是在这套原理上生长出来的。
现在,我们有了一个能画画的扩散模型,有了一个能理解文本和图像的 CLIP 模型,接下来关键的问题就是——怎么把这两者组合起来,让AI“按我们说的去画”、做到真正意义上的“AI文生图”?
3. CLIP 如何为扩散模型引路?
前面我们提到,CLIP 模型擅长理解信息,能把文字和图像都转化成向量,并放进同一个语义空间里,但它自己不会“动手画画”,只能判断“这张图像像不像你说的东西”,这就是 CLIP 的正向用法:输入图和词,它帮你判断图文是否匹配。
而扩散模型虽然能画,但画的时候没有方向感。
那有没有办法把 CLIP 的语言理解能力,和扩散模型的生成能力结合起来?让前者负责理解语义,后者负责还原图像,从而实现一种从文字直接生成图像的闭环?OpenAI 在 2022 年提出的一种架构做到了。
这个方法简单来说,就是把 CLIP 的文本编码器和扩散模型结合起来,先把用户输入的 prompt,比如“一个骑马的宇航员”变成向量,再让这个向量嵌入到每一步的去噪声操作中,作为一种条件去输入。

这种方式反向使用 CLIP的方式,就叫 UnCLIP,它不是让模型理解图像,而是反过来使用 CLIP ,它先用 CLIP 的文本编码器把一句话(比如“一个骑马的宇航员”)变成一个语义向量,然后在扩散模型生成图像的每一步中,把这个向量当作“目标方向”,指导模型往这个方向画图。
为什么这样做效果会好?因为 CLIP 在训练时吸收了大量图文对,它的语义空间非常丰富。通过它的文本向量,来指导扩散模型,本质上就是在把 CLIP 的语义空间当成地图,帮助扩散模型在高维噪声中找准目标,按照我们的 prompt 去进行生成。
上面的文字稍微有些难懂,这里贴个省流版:
把 CLIP 理解为高德地图,prompt 是输入的目的地坐标,扩散模型负责开车,抵达目的地。
这项技术后来在 OpenAI 的 DALL·E 2 中被正式商用化,成为首批高质量、强指令响应的文本生成图像产品。
至此,生成式 AI 从“能画”到“遵循人类指令作画”,从自由发挥进化到精准理解,AI 的文生图能力,也就基本成型了。
不过,早期使用过 Midjourney 等文生图产品的用户朋友应该知道,要让 AI 画出来的东西如你所愿,还是有一定距离。
用过 Midjourney 早期版本的用户应该有类似体验:你输入一句 prompt,比如“一个穿宇航服的猫在沙漠里骑车”,结果出来的图可能是——画了一片沙漠,但是没猫;或者有只猫穿着衣服但不是宇航服。
这可能不是你的 prompt 没写清楚,而是模型知道没有完全遵行指令,因为它虽然收到了 prompt ,但这个 prompt 对模型而言只是一个建议,不是强制执行。因此它在生成图像的每一步中,其实还是边画、边理解、边推测你给出的建议,因此容易走偏。
有没有一种办法,能把 prompt 的重要性放大、让模型更好地遵循 prompt 的要求进行图片生成?
这就是接下来我们要讲的无分类器引导(Classifier-Free Guidance)要解决的问题。
4. 生图能力再进阶:无分类器引导(CFG)
为了解决模型“理解了但没照做”的问题,OpenAI 在 2022 年提出了一种方法,叫做“无分类器引导”(Classifier-Free Guidance,简称 CFG)。
这个方法的核心目的是:增强生成模型对文本提示的响应能力,使其在生成图像时更精确地执行语义指令。
传统的生成方法,虽然可以让模型根据文字生成图像,但在实际使用中经常出现目标元素缺失、位置错误、细节偏弱等问题。原因在于 prompt 虽然提供了生成方向,但模型在生成过程中,并没有足够强的机制去判断自己偏离了多少,也缺乏手段主动修正方向。
而 CFG 的提出,正好解决这个“没有校准系统”的问题。它的做法是,在模型训练阶段混合使用两类样本:一类带 prompt ,另一类不带 prompt 。这使得模型学会了两种生成路径:
一是遵循 prompt 进行图像生成的路径;二是抛开 prompt 自由发挥的生成路径。
而到了生成阶段,系统可以同时执行这两条路径,分别得出两个潜在的结果,然后计算出两者之间的差异
——这个差异就是模型从「自由发挥」转为「严格遵循 prompt 」的引导方向。通过给这个方向乘上一个放大系数,引导信号被系统化地注入到每一步图像生成的过程之中。
这个放大的系数,通常是一个可以手动调节的参数,用于决定 prompt 对生成结果的干预程度,系数越大,生成图像越严格遵循 prompt ,但也可能牺牲构图的自然度;系数越小,图像自由度更高,但对于 prompt 的遵循能力也会相应减弱。
举个具体的例子,prompt 为 “一个穿宇航服的猫在沙漠中骑车”时,如果 CFG 系数设置较低,模型可能会只画出沙漠场景,猫或宇航服元素缺失;而系数调高后,猫的形象开始清晰出现,穿着宇航服,甚至包含车辆元素,整个画面与提示词高度一致。
相比以往需要额外训练分类器来判断图像是否符合 prompt 的做法,CFG 更为简洁有效。
它不依赖额外的模型来进行遵循能力提升,而是在同一个生成架构内,通过对比生成路径的方式,直接获取引导方向,大大提高了执行效率和模型稳定性。
因此从这项技术被提出之后,几乎所有主流的扩散图像生成产品,都开始集成 CFG,包括后续版本的 Midjourney(主观猜测从V3以后开始集成 CFG)、Stable Diffusion(v1.4开始集成CFG)等等。
CFG也让模型成为从“能画图”,进阶到“画得准”,让生成式 AI 从「理解语义」,进一步走向「可控生成」。
结尾
回顾整条文生图技术链条,我们看到一个清晰的演化逻辑:
- CLIP建立了图文共通的语义空间,让模型能理解文字与图像之间的联系;
- 扩散模型提供了一种惊艳的生成机制,让图像可以从纯噪声中逐步还原出来;
- UnCLIP架构使模型不仅听得懂人话,还能朝着需求目标进行生图;
- CFG则进一步强化了prompt在生成过程中的主导性,提升了准确度与可控性。
一些看起来毫不相关的、甚至完全不同的技术、完全不同的研究方向,单拎出来好像都没有任何价值,但最终却形成了一个伟大的、颠覆人类历史的图像生成系统,它能够接受模糊的输入、理解抽象的语义、执行目标引导,并在迭代中优化结果。
如果从方法论的角度来看,这整套体系并不是依靠“教模型如何一步步画出一张图”,而是通过建立空间、构建目标、释放自由度,让模型自己在混沌中寻找最优路径。这种训练机制的精髓,不在于控制每一个步骤,而在于设置目标,并设计出一种可以自我纠偏、自动趋近目标的训练机制。

这刚好跟《为什么伟大不可以被计划》中提出的观点高度契合:伟大的成果往往不是依靠一套清晰可控的计划达成的,它们更常见的路径是:先明确一个清晰的、正确的方向,然后在不断试探和调整中,一步步走出属于自己的路径。
这和人生的选择,似乎有共通之处?
很多人总希望生活能像写代码一样,有明确的路径、有确定的成功方法,但现实往往不是那样的。大多数时候,你只能先确认自己想往哪个方向走,然后接受中途的混乱、不确定性,甚至是偏离,然后再一点点把它拉回正轨。
AI 文生图不就是这样吗?从一堆随机噪声开始,一次次尝试,一点点修正,最后才画出想要的图。
所以我们也许并不需要太过于着急,也并不需要早早计划好自己的成功路径。
只要确定方向是对的,就值得一直走下去。
本文由 @比沃特 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pixabay,基于CC0协议