机器之心报道
编辑:张倩、冷猫
昨晚,自然语言处理顶会 ACL 公布了今年的一个特别奖项 —— 计算语言学博士论文奖。
这个奖项是今年新增的,获奖者是来自美国华盛顿大学的 Sewon Min。她的博士论文题为「Rethinking Data Use in Large Language Models(重新思考大型语言模型中的数据使用)」。

ACL 大会官方表示,「Min 的论文对大型语言模型的行为和能力提供了关键见解,特别是在上下文学习(in context learning)方面。 其研究成果对当今自然语言处理的核心产生了影响。

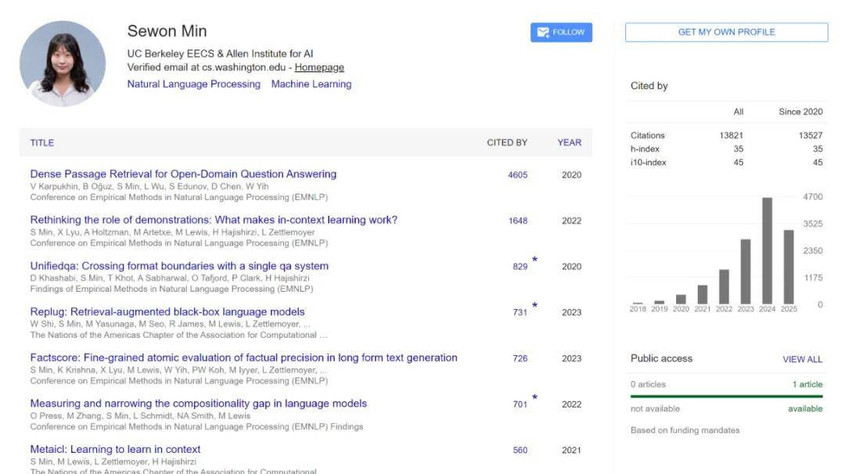
Sewon Min 本科毕业于首尔大学,2024 年在华盛顿大学拿到博士学位,现在在加州大学伯克利分校电气工程与计算机科学系(EECS)担任助理教授。Google Scholar 上的数据量显示,她的论文被引量已经过万。
除了这篇获奖论文,ACL 大会官方还公布了三篇计算语言学博士论文奖提名,获奖者分别为伊利诺伊大学香槟分校博士李曼玲、华盛顿大学博士 Ashish Sharma 和爱丁堡大学博士 Thomas Rishi Sherborne。
以下是获奖论文的详细信息。
ACL 计算语言学博士论文奖
获奖论文:Rethinking Data Use in Large Language Models

- 作者:Sewon Min
- 机构:华盛顿大学
- 链接:https://www.sewonmin.com/assets/Sewon_Min_Thesis.pdf
在这篇论文中,作者讨论了她在理解和推进大型语言模型方面的研究,重点关注它们如何使用训练所用的超大规模文本语料库。
首先,她描述了人们为理解这些模型在训练后如何学习执行新任务所做的努力,证明了它们所谓的上下文学习能力几乎完全由它们从训练数据中学到的内容决定。
接下来,她介绍了一类新的语言模型 —— 非参数语言模型(nonparametric LM)—— 它们将训练数据重新用作数据存储,从中检索信息以提高准确性和可更新性。她描述了她在建立此类模型基础方面的工作,包括首批广泛使用的神经检索模型之一,以及一种将传统的两阶段 pipeline 简化为一个阶段的方法。

她还讨论了非参数模型如何为负责任的数据使用开辟新途径,例如,通过分离许可文本和版权文本并以不同方式使用它们。最后,她展望了我们应该构建的下一代语言模型,重点关注高效 scaling、改进事实性和去中心化。
ACL 计算语言学博士论文奖提名
ACL 会议表示「在众多杰出的投稿中选出优胜者十分困难 —— 因此委员会推荐三位表现同样出色的论文获得特别提名」,因此在这里我们也将这三篇优秀的论文展示给读者。

论文 1:Event-Centric Multimodal Knowledge Acquisition

- 作者:Manling Li
- 机构:伊利诺伊大学香槟分校(UIUC)
- 链接:https://www.ideals.illinois.edu/items/128632
「发生了什么?是谁?什么时候?在哪里?为什么?接下来会发生什么?」是人类在面对海量信息时理解世界所需回答的基本问题。
因此,在这篇论文中,作者聚焦于多模态信息抽取(Multimodal Information Extraction, IE),并提出以事件为中心的多模态知识获取方法(Event-Centric Multimodal Knowledge Acquisition),以实现从传统的以实体为中心的单模态知识向以事件为中心的多模态知识的跃迁。
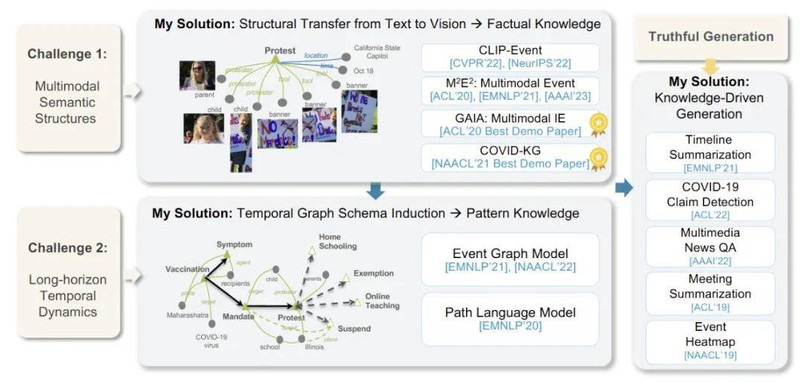
作者将这一转变分为两个核心部分:
理解多模态语义结构以回答「发生了什么?是谁?什么时候?在哪里?」,即知识抽取。由于这些语义结构具备抽象性且难以锚定于图像中的具体区域,通用大规模预训练方法难以实现语言与视觉模态间的有效对齐。
为此,作者将复杂事件语义结构引入视觉 - 语言预训练模型(称为 CLIP-Event),并首次提出跨模态零样本语义迁移方法,从语言迁移到视觉,解决了信息抽取任务在迁移性上的瓶颈,并首次实现了零样本多模态事件抽取(M2E2)。
理解时间动态以回答「接下来会发生什么?是谁?为什么?」,即知识推理。
作者提出了事件图谱结构(Event Graph Schema),首次支持在全球事件图上下文中进行推理与替代性预测,并提供结构化解释。
她提出的多模态事件知识图谱(Multimedia Event Knowledge Graphs),使机器具备从多源异构数据中发现并推理真实知识的能力。
本文作者李曼玲(Manling Li)于 2023 年毕业于 UIUC,计算机科学 PhD,导师是季姮(Heng Ji)。根据其领英信息,2023 年 8 月 - 2024 年 8 月,李曼玲在斯坦福大学人工智能实验室任博士后研究员。
李曼玲在斯坦福的导师是斯坦福大学助理教授、清华姚班校友吴佳俊, 并在李飞飞教授的指导下开展研究工作 。
目前,Manling Li 正在西北大学担任助理教授,带领机器学习与语言实验室(MLL Lab),致力于多模态智能体 AI 模型的尖端研究。实验室网址:
https://mll-lab-nu.github.io
论文 2:Human-AI Collaboration to Support Mental Health and Well-Being

- 作者:Ashish Sharma
- 机构:华盛顿大学
- 链接:https://digital.lib.washington.edu/researchworks/items/2007a024-6383-4b15-b2c8-f97986558500
随着全球心理健康问题的日益严重,医疗系统正面临为所有人提供可及且高质量心理健康服务的巨大挑战。
论文作者探讨了人机协作如何提升心理健康支持的可获取性与服务质量。
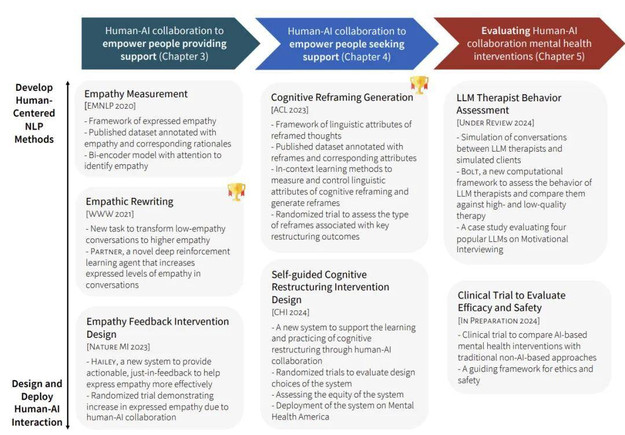
首先,作者研究了人机协作如何赋能支持者,帮助他们开展更高效、富有同理心的对话。论文以 Reddit 和 TalkLife 等在线互助平台上的互助者为研究对象。
通过强化学习方法,并在全球最大互助平台上开展一项涵盖 300 名互助者的随机对照试验,结果表明,AI 反馈机制显著提升了他们在对话中表达共情的能力。
其次,他探讨了人机协作如何帮助求助者,提升其对自助式心理干预工具的使用体验和效果。
这类干预(如认知行为疗法中的「自我训练工具」)往往认知负荷重、情绪触发强,从而影响其大规模推广。以负性思维的认知重构为案例,作者在一个大型心理健康平台上对 15,531 名用户进行随机试验,结果显示,人机协作不仅帮助用户缓解负面情绪,还为心理机制研究提供了理论支持。
第三,他系统评估了用于心理支持的人机协作系统。作者探讨了如何基于临床试验框架,有效评估 AI 心理干预在短期与长期的表现。同时设计了一套计算框架,用于自动评估大语言模型作为「治疗师」的行为表现。
本文作者 Ashish Sharma 于 2024 年毕业于华盛顿大学,计算机科学 PhD, 研究曾获得 ACL 杰出论文奖、The Web Conference 最佳论文奖,以及摩根大通人工智能研究博士奖学金。
目前,Ashish Sharma 正在微软应用研究院(Microsoft Office of Applied Research)担任高级应用科学家,研究方向聚焦于人机协作系统的开发与优化。
论文 3:Modeling Cross-lingual Transfer for Semantic Parsing

- 作者:Thomas Rishi Sherborne
- 机构:爱丁堡大学
- 链接:https://era.ed.ac.uk/handle/1842/42188
语义解析将自然语言表述映射为意义的逻辑形式表示(例如,lambda 演算或 SQL)。语义解析器通过将自然语言翻译成机器可读的逻辑来回答问题或响应请求,从而充当人机交互界面。语义解析是语言理解系统(例如,数字助手)中的关键技术,它使用户能够在不具备专业知识或编程技能的情况下通过自然语言访问计算工具。跨语言语义解析使解析器适应于将更多自然语言映射到逻辑形式。当代语义解析的进展通常只研究英语的解析。语义解析器的成功跨语言迁移通过扩大这些工具的使用范围来提高解析技术的实用性。
然而,开发跨语言语义解析器引入了额外的挑战和权衡。新语言的高质量数据稀缺且需要复杂的标注。在可用数据的基础上,解析器必须适应语言在表达意义和意图方面的变化。现有的多语言模型和语料库也表现出对英语的固有偏见,对使用者较少或资源较少的语言的跨语言迁移效果参差不齐。目前,还没有教授语义解析器新语言的最优策略或建模解决方案。
这篇论文考虑语义解析器从英语到新语言的高效适应。他们的研究动机来自一个案例研究:一名工程师将自然语言数据库接口扩展到新客户,在有限的标注预算下寻求对新语言的准确解析。克服跨语言语义解析的开发挑战需要在模型设计、优化算法以及数据获取和采样策略方面进行创新。
论文的总体假设是,跨语言迁移可以通过在高资源语言(即英语)和任务中未见过的新语言之间对齐表示来实现。作者提出了不同的对齐策略,利用现有资源,如机器翻译、预训练模型、相邻任务的数据,或每种新语言中的少量标注示例。他们提出了适合跨语言数据数量和质量的不同建模解决方案。
首先,他们提出了一个集成模型,通过多个机器翻译源来引导解析器,通过利用较低质量的合成数据来提高鲁棒性。其次,他们提出了一个零样本解析器,使用辅助任务在新语言中没有任何训练数据的情况下学习跨语言表示对齐。第三,他们提出了一个高效的元学习算法,在训练期间使用新语言中的少量标记示例优化跨语言迁移。最后,他们提出了一个潜变量模型,使用最优传输明确最小化跨语言表示之间的差异。
论文的结果表明,通过在明确优化准确解析和跨语言迁移的模型中组合最少的目标语言数据样本,准确的跨语言语义解析是可能的。
本文作者 Thomas Rishi Sherborne 2024 年在爱丁堡大学拿到计算机科学博士学位,2024 年 4 月作为一名技术人员加入 Transformer 作者 Aidan Gomez 创办的 AI 创企 Cohere,致力于挖掘大语言模型在企业应用中的潜力。
有意思的是,Thomas Rishi Sherborne 在自己的 Linkedin 界面写到「我目前不寻求新的职位,任何关于招聘的私信都不会回复(无一例外)」。看来,他对于 Cohere 的这份工作还是很满意的。
接下来,我们将继续关注 ACL 大会的奖项颁发情况,敬请关注后续报道。







