AI 一本正经“胡说八道”怎么办?OpenAI 罕见把“幻觉”拆给你看:为什么大模型 80% 正确率就能骗过人类、哪些层在偷偷编故事、RLHF 到底能不能根治。这篇论文像一份“幻觉体检报告”——看完你会知道:幻觉不是 bug,而是统计天性;与其追求零幻觉,不如学会给模型戴“概率口罩”,让系统该自信时自信,该闭嘴时闭嘴。

9月4日,已经很久没有Open的OpenAI发表了一篇题为《Why Language Models Hallucinate》(《语言模型为什么会产生幻觉》)的论文。正如我们从题目中所看到的那样,这是一篇研究AI模型产生幻觉原因的论文。论文公开发表后,也引发了业界的广泛关注。在下不才,也想从普通用户的视角出发,给朋友们分享一下我认为论文里一些需要我们关注的内容。关于AI幻觉,或许你想知道的,都在OpenAI这篇论文里。
先回顾一下AI幻觉
我们先来简单回顾一下关于“AI幻觉”的相关内容。在今年4月份的时候,我曾发表论述AI幻觉的相关视频和文章。在其中就有提及,所谓AI“幻觉”(Hallucination),是指AI会自信地给出看似有理有据却全然错误的回答的现象,也就是我们俗称的“一本正经地胡说八道”。关于AI“幻觉”的具体表现,可以总结为两类情况:无中生有和张冠李戴。
AI存在“幻觉”,这事儿好还是不好呢?我的观点非常明确——弊远大于利。尽管有一些观点认为,AI“幻觉”某种程度上也是AI的一种“开脑洞”的创造力,也有助于激发思维的发散。但即便是“开脑洞”,这也是一种不可预测也不可掌控的“开脑洞”。如果一项特性不可预测也不可掌控,那实际上是无法真正落地成为一项稳定的能力的。
我从事AI培训讲师亦一年有余,在接触大量的企业学员后,愈加坚定了这样的看法:对于企业而言,AI模型的能力强大与否固然重要,但更重要的是服务落地的可用性与稳定性,而其中影响最大的因素,就是“AI幻觉”。
对于AI模型为什么会产生幻觉,能否减少甚至避免AI生成幻觉,相关的话题其实一直是业界关注的话题。而这次OpenAI的论文,则很深入地研究并论证了以上问题。
幻觉的产生是不可避免的
既然AI幻觉是“弊远大于利”,那么我们有办法完全避免幻觉的产生吗?很可惜的是,OpenAI团队给我们迎面拨了一盆冷水。在论文中,OpenAI团队就明确指出,生成可靠信息比判断是否可靠更难,而判断是否可靠本身必然会有失败的地方。
我们知道,生成式AI的本质是“概率生成”,即基于上下文预测下一个字词(Token)。而生成的前提,是“判断”,判断这个句子是否成立。可是,这里的“判断”背后不存在真正的“语义理解”,而只是通过逐词预测的方式,将每一步的条件概率相乘,得到一个总概率值。这个概率值反映了该句子与模型在海量数据中学到的统计规律的符合程度。当一个句子的总概率值高于某个设定的阈值时,即被判断为“成立”,反之则为“不成立”。也就是,AI只要“看起来熟、顺”,就认为这个句子是成立的。
我来举个例子说明,比方说这么一个句子,“万里无云的天空飘着朵朵白云”,这个句子显然是不成立的。但是人类与AI作出“不成立”判断的依据是不同的:人类是从逻辑上推演,既然“万里无云”,那就不应该“飘着白云”;而AI是从概率上看到,“万里无云”,与“飘着白云”搭配在一起的概率,不符合它在训练中总结的统计规律。
很显然,这样的判断方式,并不会完全可靠。因为AI必须会碰到那些“似是而非,真假难辨”的内容,也必须会出错(这就是统计学里的“大数定律”)。OpenAI的论文列举了多种可能导致判断出错的原因,包括:相关数据过少导致模型只能猜测;概念过于复杂模型无法理解;训练数据本身包含错误等等。
剩下的推导就简单了,由于“判断”句子是否成立必然会出错,而每一次出错,都会被放大并传导至生成内容当中。因此,生成式AI是不可避免会产生幻觉的。
人类的鼓励导致了AI幻觉的泛滥
既然AI幻觉的产生是不可避免的,那么是否有可能采取一些措施,尽可能抑制AI产生幻觉呢?理论上是可以的,但实际上我们看到的情况是,AI经常性地出现幻觉。
关于AI模型为什么会经常出现幻觉,OpenAI给出了他们的观点:因为人类训练AI模型的时候,一直都在鼓励它与其放弃,不如蒙一把。论文中汇总了目前绝大多数被广泛用于衡量AI模型能力的主流评估,几乎都采用的是“二元评分制”,即答案只被简单地判定为“正确”(得1分)或“错误”(得0分),也就是“答对得分,答错不得分但也不会额外扣分”。

关于这一点其实很好理解,我们都参加过考试。考试就是典型的“答对得分,答错得0分但不会额外扣分”,所以我们哪怕遇到完全不会的题目,也会尽可能蒙一个答案上去。这一点倾向性也体现在AI模型当中,我们可以来看看OpenAI自家的两个模型参加同一场叫SimpleQA考试的对比结果。
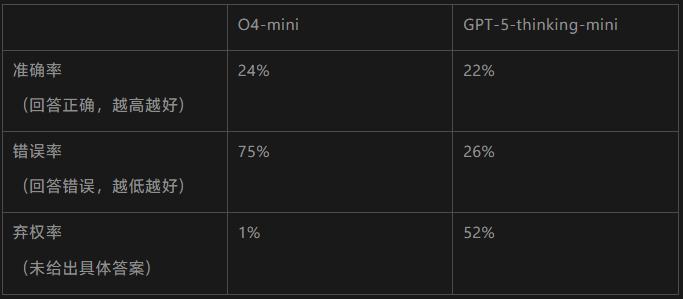
从表中我们可以看到,首先,O4-mini的准确率比它的后辈GPT5都要更强。可是,这样的结果是以非常高的错误率换来的。因为GPT5面对不确定的问题时,会更大胆地放弃,而不是强行蒙一个。这也是为什么虽然O4-mini的准确率略高,可在实际体验中,GPT5才是那个幻觉率更低的模型。
同样的情况,不禁让我想起Deepseek-R1的训练奖励机制(关于Deepseek-R1是如何训练的,之前我也有整理专门的一篇文章),简单来说就是两条:
1)准确度激励:判断答案是否正确。如果模型回答2,则加 1 分;如果答案错误,则不加分。
2)格式激励:模型必须按照要求的格式作答,即需要尝试写出推理过程。
这是一套简洁且巧妙的思维链训练奖励机制,但与此同时我们知道,Deepseek-R1的幻觉率一直较其他模型要高。如今来看,OpenAI的这篇论文所揭晓的,应该就是其背后的原因了。
也就是说,尽管AI幻觉的产生是不可避免的,可正是因为人类的鼓励,才导致了AI的幻觉非但没有被抑制,反而变得更加泛滥。
后续可能的应对策略
现在,让我们来回顾一下整篇论文对于AI幻觉的论述。首先,OpenAI团队从机制上推导出“幻觉的产生是不可避免的”这一结论。原因就是在于判断一个句子是否成立是概率方式的判断。而概率方式的判断,就必然会存在有出错的情况。然而,OpenAI指出,正是在训练过程中奖励机制只专注在得分,等于是鼓励AI“与其放弃,不如蒙一把”的行为,这进一步导致了AI的幻觉非但没有被抑制,反而变得更加泛滥。(哦对了,顺便多说一嘴,网上有一些文章说OpenAI终于“找到了”AI幻觉的原因,这个说法是不准确的。因为上述的这些原因,其实之前业界都有对应的猜测,这次更准确的说法应该是,OpenAI“论证了”AI幻觉的原因)。
既然AI的幻觉是不可避免的,那么应对策略也就剩下尽可能降低AI幻觉的占比。而这里的原因是训练奖励机制鼓励“蒙一把”,那我们就应该调整为鼓励AI“说不知道”,也就是。具体来说,我们可以形成“答对加分,放弃不得分,答错额外扣分”的机制,从而引导AI更严格地衡量回答题目的准确度,只在有相当把握的情况下,才进行回答。与其同时,AI的产品设计,也应该为模型增加“允许AI说不知道”的选择。
一直以来,对于AI幻觉的来源,可谓众说纷纭,这次OpenAI团队的这篇论文,某种程度上算是一种盖棺定论了。我相信,这次关于AI幻觉的研究结论,对于国内外一众的AI产品(尤其是幻觉情况相对较为严重的Deepseek)而言,应该说是指明了后续的改进方向。不久的将来,想必AI产品将会变得“聪明又可信”吧,让我们拭目以待。
本文由人人都是产品经理作者【产品经理崇生】,微信公众号:【崇生的黑板报】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







