衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
全球首个具备模拟推理能力的具身模型来了!
谷歌DeepMind正式发布新一代通用机器人基座模型——Gemini Robotics 1.5系列。
它不止于对语言、图像进行理解,还结合了视觉、语言与动作(VLA),并通过具身推理(Embodied Reasoning)来实现“先思考,再行动”。
这一系列由两大模型组成:
- Gemini Robotics 1.5(GR 1.5):负责动作执行的多模态大模型;
- Gemini Robotics-ER 1.5(GR-ER 1.5):强化推理能力,提供规划与理解支持。
其中,ER代表“具身推理”。
这意味着GR-ER 1.5是全球首个具备模拟推理能力的具身模型。

不过,GR-ER 1.5并不执行任何实际操作,GR 1.5正是为执行层而生。
两者结合,能让机器人不仅完成“折纸、解袋子”这样的单一动作,还能解决“分拣深浅色衣物”甚至“根据某地天气自动打包行李”这种需要理解外部信息、分解复杂流程的多步任务。
甚至,它能根据特定地点的特定要求(比如北京和上海的不同垃圾分类标准),自己上网搜索,以帮助人们完成垃圾分类。
而且用上GR 1.5系列的模型,还能够在多种不同的机器人之间进行能力的零样本跨平台迁移。

Unbelivable~
毫不夸张地说,这是谷歌继Gemini 2.5之后,又一个将通用AI推向现实世界的重要里程碑。
哈斯比斯也激动表示:
GR 1.5以多模态Gemini为基础,展示了其能够理解并推理物理世界的强大功能。
未来机器人将变得至关重要——我们对这项开创性工作感到非常兴奋!
GR 1.5系列五大能力展示
先来看一段视频——
我们来把GR 1.5系列在发布中展示的能力,总结为五个关键词:
执行复杂长程任务,中间还能自我检测并修正
不仅限于一次抓取、一次搬运,GR 1.5能执行包含多步子任务的长流程。
比如:
- 把不同颜色的衣服分类;
- 从衣柜取出雨衣,再打包进行李箱;
- 在厨房完成配料准备,甚至尝试烹饪流程。
在GR 1.5这里,任务被分解成多个阶段,机器人逐一完成。

更重要的是,在执行任务的过程中,GR 1.5能检测成功与否,并自动修正。
适配多种机器人硬件
同一个模型,既可以驱动低成本双臂机器人ALOHA,还可以驱动工业级Franka,还可以驱动人形机器人Apollo。
一整个丝滑无缝迁移使用。
这意味着,不需要针对每个平台单独训练,一个通用模型就能上手不同团队、不同形态的多种硬件。
跨机器人迁移
谷歌DeepMind机器人部门负责人Carolina Parada表示:
如今的机器人高度定制化,部署困难,往往需要数月时间来安装一个只能执行单一任务的单元。
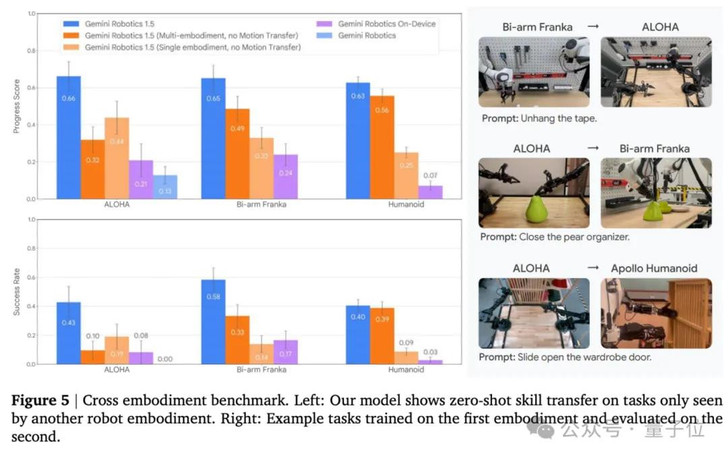
转观GR 1.5系列,这个模型在ALOHA上学会的技能,可以直接迁移到Franka;在Franka上训练的操作,能零样本转移到Apollo。
这背后的关键在于Motion Transfer技术(详细介绍见后文),使机器人不再局限于“谁教谁用”,而是真正形成跨平台的通用动作理解。

推理型具身模型
如前文介绍,GR-ER 1.5是一个具身推理模型。
这使得GR 1.5系列加持下的机器人在行动前,会在内心生成一段内心独白。
它会先用自然语言把复杂任务拆解为小步骤,再逐一执行。
这种显性思考不仅让机器人更稳健,也让人类可以清晰看到它的思考过程,提升了可解释性。

GR 1.5系列的两款模型协同工作,共同推理思考如何完成任务。
如下图展示:

安全可解释
在演示中,研究人员展示了GR 1.5系列加持下的机器人,在操作中如何自我修正:
比如抓起水瓶失败后,立刻转换方案,用另一只手完成任务。
同时,模型还能识别潜在风险,避免危险动作,确保在人类环境中运行时的安全性。

提出全新“Motion Transfer”机制
Gemini Robotics 1.5最大的突破,在于实现了“规划+执行”的完整闭环。
前面我们已经提到过,这一系列由两大模型组成:
- GR 1.5:VLA模型,专注将语言/视觉输入转化为动作输出。
- GR-ER 1.5:强化推理的Vision-Language模型,负责高层规划、工具使用与进度监控。
两款模型都基于Gemini基础模型构建而来,但已使用适应物理空间操作的数据进行微调。
其中,前者是执行者,能够直接把自然语言和视觉输入转化为低层级的机器人动作。
后者是大脑指挥官,负责理解复杂任务、做出高层规划,并在必要时调用外部工具、监控任务进度。
二者组合成一个Agentic Framework,让机器人不仅能听懂指令,还能思考如何完成并执行到底,以此实现“规划+执行”的闭环。

支撑这一体系的,是GR 1.5系列庞大而多样化的数据来源。
一方面,团队采集了大量真实机器人在ALOHA、Franka、Apollo等平台上完成的成千上万种操作数据。
另一方面,数据集中还引入了互联网中的文本、图像与视频信息,确保模型既拥有来自现实的动作经验,具备广泛的语义与世界知识。
要真正让不同形态的机器人共享技能,单靠数据还不够。
为此,研究团队提出了全新的Motion Transfer机制。
Motion Transfer的核心思路,是把不同机器人平台的运动轨迹和操作经验,映射到一个统一的动作语义空间中。
这样一来,看似完全不同的硬件——比如机械臂与人形机器人——在模型眼中就有了共通语言,于是能把不同机器人平台的动作映射到一个统一的表示空间,使得GR 1.5系列具备操作经验跨机器人迁移的能力。
更重要的是,Motion Transfer不只是做简单的对齐,它还结合了跨平台的大规模数据。
它“提炼”出了物理世界的通用规律:
物体怎么被抓住、怎样保持平衡、不同环境下动作要如何调整……以此增强任务泛化和跨机器人迁移测试的能力和水平。
同时,在训练过程中,大约九成以上的迭代都在MuJoCo仿真环境中完成,模型先在虚拟世界里快速试错、迭代,再迁移到真实机器人进行验证。
这样一来,不仅显著提升了研发效率,也保证了在现实硬件上执行时的稳定性与安全性。
三大核心创新,还不牺牲安全性
研究团队提出,GR 1.5系列的核心价值,在于同时实现了三个方面的创新与突破。
最引人注目的,是它让机器人具备了思考推理的能力。
在传统的模型中,动作往往是对指令的直接映射,而 GR 1.5 在行动前会先生成一段思考轨迹,把复杂任务拆解成小步骤,再逐一执行。
这种显性推理不仅让机器人在多步任务中更稳健,还让研究人员和用户能够直接看到它的思考过程,增强了可解释性和信任感。
另一项突破是跨平台的技能迁移。
过去,机器人学习往往被局限在某一特定平台上,数据难以复用。
但GR 1.5系列在引入Motion Transfer机制后,把不同机器人之间的动作经验抽象到统一空间,使得在机器人甲身上学到的技能,可以直接迁移到机器人乙身上——甚至在未见过的新环境中也能顺利执行。
这意味着机器人不再被硬件形态束缚,而是能够共享整个生态的知识与经验。
与此同时,具身推理模型GR-ER 1.5把“理解物理世界”的能力推向了新高度。
它不仅能进行空间理解和任务规划,还能实时评估任务进度,识别潜在风险,甚至在复杂场景中做出类似人类的推断与修正。
在学术基准测试中,GR-ER 1.5在空间推理、复杂指点、进度检测等任务上全面超越了GPT-5和Gemini 2.5 Flash,刷新了业界的表现上限。

研究团队还对GR 1.5系列做了更多评测:
在230项任务的基准测试中,GR 1.5在指令泛化、动作泛化、视觉泛化和任务泛化四个维度上都表现出色,明显优于前代模型。
在长时序任务上,结合GR-ER 1.5的系统,任务完成进度分数最高接近80%,几乎是单一VLA模型的两倍。
尤其值得注意的是,在跨机器人迁移测试中,模型展现出了前所未有的零样本迁移能力。
更关键的是,这种强大性能并没有以牺牲安全为代价。
如下图数据显示,GR 1.5 在ASIMOV-2.0安全基准中表现出更高的风险识别与干预能力,能够理解动作背后的物理风险,并在必要时触发保护机制。
配合自动红队测试的持续打磨,模型在抵御对抗攻击、避免幻觉响应等方面也展现出更强鲁棒性。

One More Thing
让我们简单回溯一下——
今年3月,谷歌首次推出了让机器人拥有多模态理解能力的Gemini Robotics系列;6月,又推出了Gemini Robotics On-Device,这是一个针对快速适配和机器人硬件上稳健灵巧性进行优化的本地版本。
Parada表示,随着这次更新,GR系列正从执行单一指令转向对物理任务进行真正的理解和解决问题。

But!
噔噔噔,最后敲个黑板:
目前,开发者已经可以通过Google AI Studio中的Gemini API使用GR-ER 1.5,而GR 1.5只供少数谷歌DeepMind的合作伙伴使用。
等等党们,看来还要再等等等等等一会了……
参考链接:
[1]https://x.com/demishassabis/status/1971292365592854602?s=46&t=fzKJptGJMpr-yj3MUXd6HA
[2]https://arstechnica.com/google/2025/09/google-deepmind-unveils-its-first-thinking-robotics-ai/
[3]https://www.theverge.com/news/785193/google-deepmind-gemini-ai-robotics-web-search
[4]https://the-decoder.com/google-deepmind-brings-agentic-ai-capabilities-into-robots-with-two-new-gemini-models/
— 完 —
量子位 QbitAI · 头条号
关注我们,第一时间获知前沿科技动态







