
AI 能动性的时代要求系统不仅能思考,更要能干活:包括协同编程(人机协作开发)和自动化科学研究。LIMI 仅用 78 个样本就超越 GPT-5 达 14.1%,并发现了能动性效率原则: AI 能动性不仅来源于数据丰富性,更来自于战略性构建。
本文来自于上海创智学院和上海交大刘鹏飞老师团队,团队专注于构建最前沿 AI 系统。核心作者来自于香港理工大学,上海交通大学,以及中国科学技术大学。
从 ChatGPT 到 Claude,从 Codex 到 Claude Code,全球科技公司正在 "能动性" 领域展开激烈竞争。这一趋势反映了产业界的关键认知:能动性能力正成为 AI 系统的核心竞争力,决定着 AI 能否从简单的对话工具演进为真正的工作伙伴。具备能动性的 AI 系统将重新定义人机协作模式,成为推动各行各业智能化转型的关键技术。
什么是 "能动性"?它是 AI 系统主动发现问题、制定假设,并通过与环境和工具的自主交互执行解决方案的能力。这种能力的重要性在于,它使 AI 从被动响应工具转变为主动执行的智能助手,能够独立完成复杂的知识工作任务。例如,让模型从零开始开发一个完整的五子棋游戏需要模型具备需求理解、架构设计、代码实现、调试优化等完整的自主执行能力。这种协作编程场景代表了现代知识工作的典型需求,而具备这种能力的 AI 系统将能够承担大量现实世界的复杂任务。
同样,在科研工作流程中,模型需要完成从文献调研到实验设计,从数据分析到洞察生成的完整链路。能动性使 AI 能够独立推进科学研究进程,这对于加速科学发现具有重大意义。
能动性能力的培养难度远超传统 AI 能力,因为它要求模型具备长期规划、多步推理、工具协调和自主纠错等高阶认知能力。当前主流方法普遍认为复杂的能动性能力需要大量训练数据支撑,遵循传统的规模化定律。这导致了资源密集型的训练流程:收集数万甚至数十万个训练样本,消耗大量计算资源,但效果往往不尽如人意。
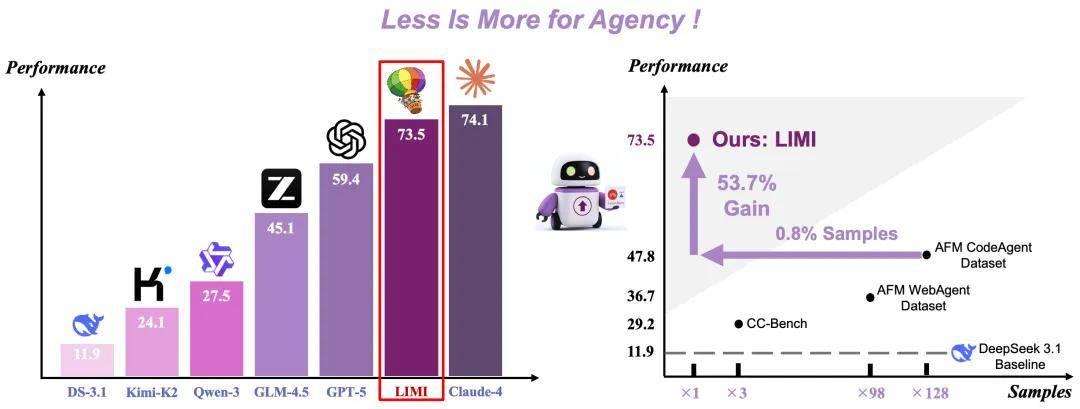
LIMI 的研究结果表明,仅使用 78 个复杂多轮交互轨迹样本,模型就能在能动性基准测试 AgencyBench 上达到开源模型的最佳表现,还超越了 GPT-5 的性能。相比使用 10,000 个样本训练的模型,LIMI 实现了 53.7% 的性能提升,数据使用量却仅为其 1/128。
视频链接:https://mp.weixin.qq.com/s/cDlxo_4vz3do4PNUfImyMw
如图展示了一个模型从头开发的完整可运行的五子棋游戏,这种端到端的自主执行能力正是未来 AI 系统的核心价值所在,证明了其在实际工作场景中的巨大应用潜力。
LIMI 的发现挑战了 "数据规模决定能力上限" 的传统认知,提出了能动性效率原则:模型能动性的发展更依赖于对能动性本质的理解和高质量数据的精准构造,而非简单的数据堆叠。这一发现为大规模部署具备真正工作能力的 AI 系统开辟了可行路径,表明理解能动性的核心机制比盲目扩大数据规模更为重要。

- 论文标题:LIMI: Less is More for Agency
- 论文地址:https://arxiv.org/pdf/2509.17567
- 代码地址:https://github.com/GAIR-NLP/LIMI
- 数据集地址:https://huggingface.co/datasets/GAIR/LIMI
- 模型地址:https://huggingface.co/GAIR/LIMI
- AgencyBench:https://agencybench.opensii.ai/
- SII CLI:https://www.opensii.ai/cli/
从被动响应到主动工作:能动性能力时代的到来
能动性大语言模型(Agentic LLMs)的出现,那些能够推理、行动并自主交互的系统,代表着从被动 AI 助手向具备主动能力模型的范式转变。研究团队将能动性定义为 AI 系统作为自主代理运作的新兴能力:主动发现问题、制定假设,并通过与环境和工具的自主交互执行解决方案。
这一根本能力标志着 "AI 能动性时代" 的到来,其驱动力来自一个关键的行业转变:迫切需要不仅会思考,更会工作的 AI 模型。虽然当前 AI 在推理和生成响应方面表现出色,但产业界需要能够执行任务、操作工具并推动现实世界成果的能动性模型。
然而,能动性模型的训练面临着关键挑战。当前方法普遍假设更多数据能让模型产生更强的能动性能力,遵循语言建模的传统扩展定律(scaling laws)。这种范式导致了日益复杂的训练流程和大量资源需求,但一个根本假设仍未得到检验:模型的能动性能力是否真的需要接触大量训练数据,还是可以通过战略性方法更高效地涌现?
相邻领域的新兴证据暗示了一个令人信服的替代范式。LIMA 仅用 1,000 个精心策划的样本就实现了有效的模型对齐,而 LIMO 证明复杂数学推理能力能够从仅 817 个战略性选择的训练样本中涌现。这些发现表明,战略性数据构造可能在培养复杂 AI 能力方面比数据集规模根本上更强大。
研究团队的 LIMI 给出了答案:模型的能动性能力遵循着与传统扩展方法根本不同的发展原则。通过战略性聚焦协作软件开发和科学研究工作流程,这些领域涵盖了大多数知识工作场景,研究表明复杂的能动性能力可以从少量但精心构造的高质量数据中涌现。
如图 1 所示,LIMI 仅用 78 个训练样本就让模型在 AgencyBench 上达到 73.5% 的性能,不仅超越了所有基线模型,更令人震撼的是,相比使用 10,000 个样本训练的模型实现了 53.7% 的性能提升,用 128 倍更少的数据让模型获得了卓越的能动性能力,彻底颠覆了 "更多数据 = 更强能动性" 的传统认知。
核心领域聚焦:协作编程与科学研究工作流
为了验证 LIMI 提出的战略性数据构造方法,该研究聚焦于两个需要完整能动性能力谱系并涵盖大多数知识工作场景的基本领域。
协作编程代表 LLMs 与人类开发者在上下文丰富环境中协作的软件开发模式。这个领域需要:跨现有代码库的代码理解和生成,通过复杂工具生态系统的开发环境导航,通过调试和优化循环的迭代问题解决,以及技术协调的协作沟通。复杂性在于对开发上下文的整体理解和在不断变化需求下的原则性决策制定。
科学研究工作流程涵盖复杂科学研究过程,包括文献搜索、数据分析、实验设计和洞察生成。这些工作流程需要:对多样化信息来源进行综合,采用适当方法论的实验设计,复杂结果的数据分析和解释,以及跨不同利益相关者格式的知识沟通。
这些任务展现出显著的时间复杂性,表现为需要连贯状态跟踪和累积推理的多轮交互。它们需要战略规划能力,将复杂目标分解为可管理的子目标,同时基于环境反馈适应性调整策略。工具编排能力变得至关重要,因为现实世界的能动性任务需要模型协调调用多个不同工具来完成复杂任务。
如图 2 所示的用户查询示例展现了单个查询的巨大复杂性 —— 从基础到专家级递进的五子棋开发任务涵盖 Web 前端开发、数据过滤、状态管理、规则启发式 AI 和高级搜索算法等多个相互关联的子任务。这种复杂性覆盖了规划、执行和协作等维度,展现了高质量演示中学习信号的密集性。

图 2:用户查询示例,展示了单个查询如何在规划、执行和协作维度上包含多个相互关联的子任务,证明了高质量数据中学习信号的密集性。
精准数据构建:战略策划的系统化方法
LIMI 方法的有效性根本依赖于战略性数据构造,通过真实世界协作任务捕捉本质的能动性行为。该研究团队围绕能动性交互的基本要素形式化数据构建过程,将每个完整交互定义为元组 < 用户查询,能动性轨迹 >,其中用户查询启动协作工作流程,轨迹捕获完整交互序列。
如图 3 所示,LIMI 的训练数据展现了显著的高质量特征:轨迹长度分布广泛,平均达到 42.4k tokens,最长可达 152k tokens,远超传统训练样本的长度。右侧的领域覆盖图显示了数据在协作编程和科学研究工作流程两个核心领域的广泛分布,涵盖了从前端开发、调试、工具调用到论文搜索、深度学习、实验工作流程等多个细分方向。
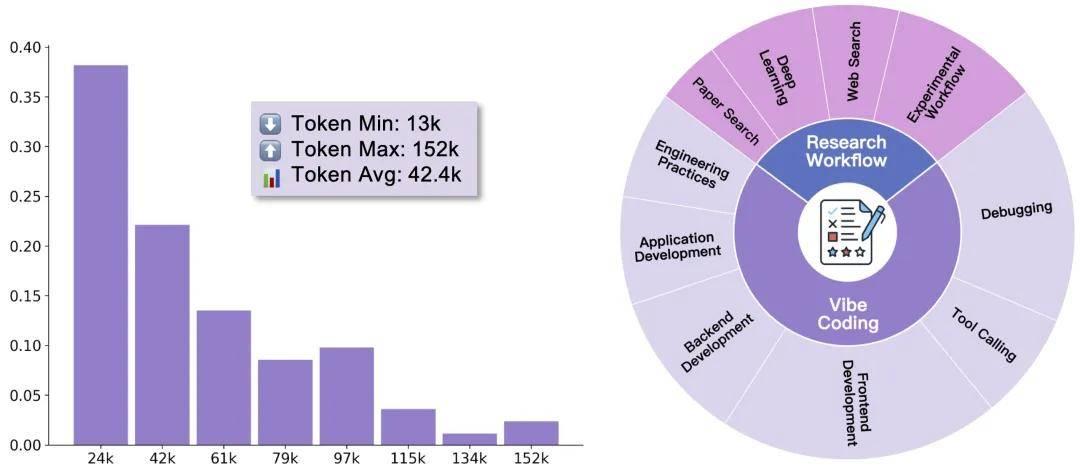
图 3:LIMI 训练数据的特征。左图:轨迹长度分布显示交互复杂性(平均 42.4k tokens)。右图:涵盖 vibe 编程和研究工作流的全面覆盖。
用户查询池构建:真实性与系统性的结合
查询收集策略系统性地结合真实世界场景与战略性覆盖扩展,确保生态有效性和充足的训练多样性。
真实世界用户查询收集: LIMI 从专业开发者和研究者在协作环境中遇到的实际场景收集 60 个查询。这些查询代表跨两个核心领域的真实挑战,具有自然复杂性和上下文丰富性。值得注意的是,大量研究查询来自真实学术论文,确保收集的用户查询具有可信的代表性。
基于 GitHub PR 的查询合成:为了在保持真实性的同时系统性扩展查询池,团队开发了使用 GPT-5 从 GitHub Pull Requests 合成额外查询的流水线。这种方法利用真实代码更改的丰富上下文,采用 GPT-5 的先进推理能力生成反映真实开发需求的协作场景。
系统性策划过程涉及多个质量保证阶段:
(1)选择具有超过 10,000 GitHub stars 的高质量代码仓库,(2)确保软件开发领域的综合覆盖,(3)基于复杂性和实质性进行过滤,(4)采用四名计算机科学博士生作为专家标注员评估合成查询的质量,确保语义对齐和上下文准确性。
通过这种系统化方法,团队最终构建了包含 78 个高质量用户查询的综合池,每个查询都代表来自协作编程或科学研究工作流程的真实协作场景。
轨迹收集:捕获最优能动性行为
为了生成展示最优能动性行为的训练轨迹,研究需要能够支持真实人机协作的复杂执行环境。这个环境必须支持复杂工具交互、维护详细交互日志,并提供现实能动性智能评估所需的操作上下文。
团队选择 SII CLI 作为执行环境,基于其几个关键优势:(1)支持协作编程和研究工作流程的全面工具集成,(2)对高质量训练数据收集至关重要的详细轨迹日志能力,(3)启用自然交互模式的灵活人机协作界面,(4)对需要协调工具使用的复杂多步任务的强大支持。
在 SII CLI 环境内,四名博士生标注员作为人类协作者,与 GPT-5 作为能动性模型协作,在真实协作场景中完成 78 个用户查询的轨迹收集。
对于每个查询,采用迭代收集方法,持续收集轨迹直到任务成功完成。这种持续性方法确保收集的轨迹捕获真实人机交互模式,包括自然的来回沟通、迭代细化过程和表征有效能动性行为的协作问题解决策略。
正如图 3 左侧轨迹长度分布所示,这种方法产生了内容极其丰富、交互高度复杂的高质量训练轨迹数据,平均长度达到 42.4k tokens,远超常规训练数据的复杂度,为模型提供了密集的能动性学习信号。
突破性实验结果:颠覆认知的发现
实验设置与评估框架
为了验证 LIMI 假设并证明战略性数据构造方法的有效性,团队采用了全面的实验框架,跨多个评估维度将方法与强基线模型进行比较。
基线模型评估:团队评估了多样化的最先进基础模型,确保全面比较:GLM-4.5、GLM-4.5-Air、Qwen3-235B-A22B-Instruct、DeepSeek-V3.1、Kimi-K2-Instruct。这个选择涵盖了具有不同架构设计和训练方法的开源模型,支持对能动性能力的严格评估。
模型训练与对比实验:为了系统评估策划训练数据的影响,团队使用收集的数据对 GLM-4.5 和 GLM-4.5-Air 进行微调。所有微调实验使用 slime 框架进行,确保一致的训练条件、超参数优化和公平比较。
此外,为了评估数据策划策略的质量和有效性,团队通过在三个替代数据集上微调 GLM-4.5 进行比较实验:CC-Bench-trajectories、AFM-WebAgent-SFT-Dataset 和 AFM-CodeAgent-SFT-Dataset。这种实验设计支持战略性策划数据与现有大规模能动性训练数据集的直接比较。
评估框架:评估包含两个互补策略,全面验证 LIMI 方法的有效性:
(1)在 AgencyBench 上的主要评估,专门设计用于评估协作场景中的能动性能力;(2)在涵盖工具使用、编程和科学计算的多个基准上的泛化能力评估,确保发现能够泛化到核心领域之外。
AgencyBench 上的卓越表现
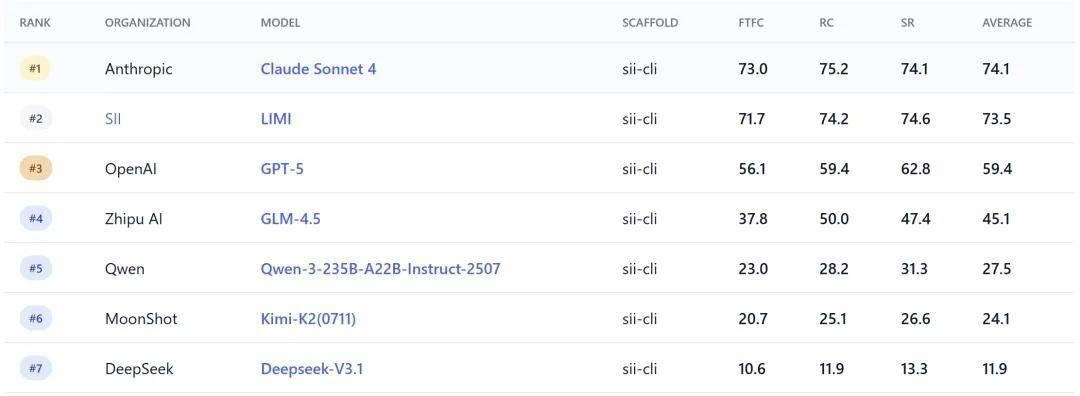
如表 1 所示,在 AgencyBench 基准测试中,LIMI 取得了令人震撼的成绩:
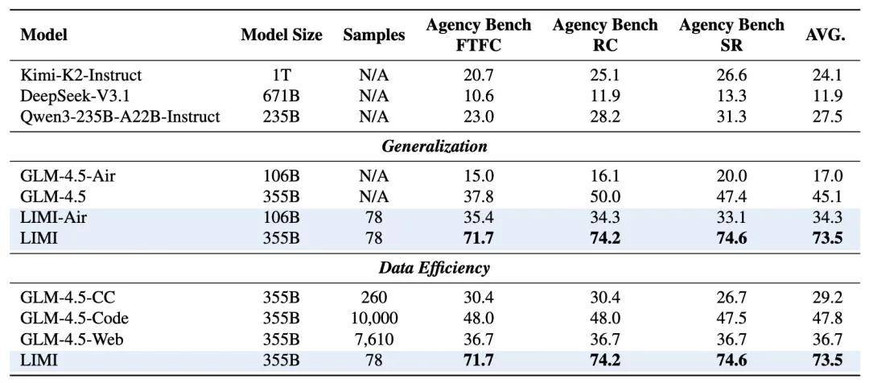
表 1: LIMI 系列模型在 AgencyBench 上的综合比较。模型按评估目的分组:基线比较、泛化能力评估和数据效率验证。
LIMI 达到了 73.5% 的平均得分,显著超越了所有基线模型:GLM-4.5(45.1%)、Kimi-K2-Instruct(24.1%)、DeepSeek-V3.1(11.9%)和 Qwen3-235B-A22B-Instruct(27.5%)。
性能差距在首轮功能完整性(FTFC)方面特别明显,LIMI 达到 71.7%,相比 GLM-4.5 的最佳基线性能 37.8% 实现了显著的 33.9 个百分点改进。类似地,LIMI 以 74.6% 的成功率展示了卓越的任务完成可靠性,大幅超越了最强基线模型 GLM-4.5 的 47.4%。
数据效率的极致体现
最震撼的发现是数据效率对比结果,为核心 LIMI 假设提供了令人信服的实证证据:战略性数据策划在开发能动性智能方面根本上比简单扩展训练数据量更有效。
LIMI 使用仅 78 个精心策划的训练样本就达到了卓越性能,大幅超越了在数量级更大数据集上训练的模型。最引人注目的是与在 AFM-CodeAgent-SFT-Dataset 上训练的 GLM-4.5-Code 的比较:LIMI 的 73.5% 平均 AgencyBench 性能戏剧性地超越了大规模方法实现的 47.8%,尽管使用的数据集小 128 倍(78 vs. 10,000 样本)。
关键数据效率对比:
- LIMI (78 样本) vs GLM-4.5-Code (10,000 样本):25.7 个百分点优势,数据量仅 1/128
- LIMI vs GLM-4.5-Web (7,610 样本):23.5 个百分点优势,数据量仅 1/97
- LIMI vs GLM-4.5-CC (260 样本):18.0 个百分点优势,数据量仅 30%
这些一致的改进证明了战略性数据策划能够比大规模数据收集实现更有效的能力迁移,确立了能动性智能开发中 "少即是多" 范式的广泛适用性。
跨领域泛化验证
如表 2 所示,LIMI 的优势扩展到涵盖工具使用、编程和科学计算的多样化基准测试中,证明了方法的广泛适用性。LIMI 达到 57.2% 的平均性能,超越了所有基线模型,包括 GLM-4.5(43.0%)、Kimi-K2-Instruct(37.3%)、DeepSeek-V3.1(29.7%)和 Qwen3-235B-A22B-Instruct(36.7%)。
值得注意的是,LIMI 在关键编程基准上达到了最高性能(EvalPlus-HumanEval:92.1%,EvalPlus-MBPP:82.3%),并在工具使用任务上展示了竞争性结果(TAU2-bench-airline:34.0%,TAU2-bench-retail:45.6%)。
跨多样化评估领域的一致性能优势证明了战略性数据策划方法产生的广泛模型能力改进,确立了核心协作编程和研究工作流程之外强大的性能表现,表明 LIMI 不是简单的任务记忆,而是真正掌握了可迁移的能动性思维模式。
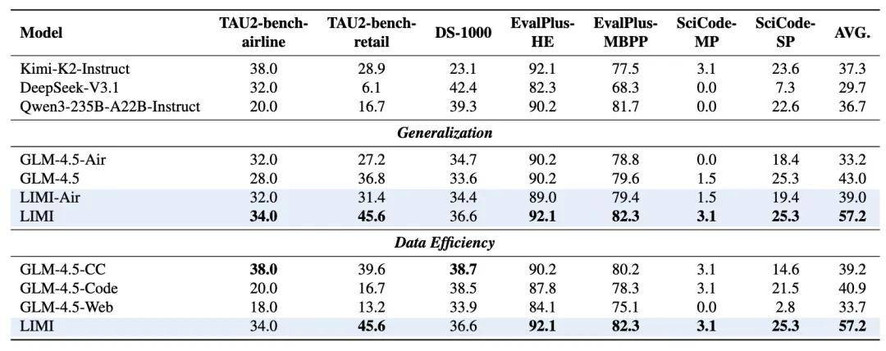
表 2:泛化基准测试的综合性能比较。HE 代表 EvalPlus-HumanEval,MP 和 SP 分别代表 SciCode 的主要问题和子问题指标。平均值包含了 AgencyBench 的表现。
能动性效率原则
基于实验结果,研究建立了能动性效率原则:
模型能动性的涌现并非来自简单数据的堆砌,而是来自高质量能动性数据的精心构造。
这一发现根本重塑了开发能动性大模型以及 AI Agent 的方式,表明掌握能动性需要理解其本质,而不是简单的扩大训练数据规模。
LIMI 促成了能动性训练范式的根本性转换:从 "更多简单数据→更强能动性" 的旧范式,转向 "更高质量的能动性数据→更强能动性" 的新范式。LIMI 认为:能动性本质上是 "潜伏" 于预训练模型中的,关键挑战不是训练新能力,而是找到激活路径。
产业影响与未来展望
对 AI 产业生态的重塑
LIMI 的发现对整个 AI 产业生态具有深远影响:
研发效率革命:小团队凭借精准方法可以与大公司竞争,降低了能动性技术的门槛,促进更多创新性方法的涌现。
资源配置优化:将投入重点从数据收集转向高质量样本设计和生成,从 "资源竞赛" 转向 "数据构造方法竞赛"。
应用落地加速:为实际能动性系统的开发提供了高效可行的路径,在实际应用中提供了具体的指导原则:专注核心场景、完整流程轨迹、质量优先策略。
商业化前景与技术普惠
LIMI 方法的商业化前景广阔:降低开发成本,减少对大规模数据和计算资源的依赖;缩短开发周期,通过精准方法快速获得能动性突破;提高应用效果,在特定领域达到更好的性能表现;普惠化应用,让更多中小企业能够负担得起能动性技术。
未来发展方向
虽然 LIMI 目前主要验证了协作软件开发和科学研究两个领域,但其原理有望扩展到医疗诊断能动性、教育辅导能动性、商业分析能动性等更广阔的认知领域。
未来的能动性系统将发展为多模态能动性,融合视觉、语言、行动等多种模态;自主学习能动性,从被动激活发展到主动进化;以及更完善的理论体系,建立能动性激活的数学模型和评估框架。
结语:开启能动性新时代
LIMI 不仅是一项技术突破,更是 AI 发展理念的根本性转变。它证明了在能动性开发中,理解本质比扩大规模更重要,质量比数量更关键。
78 个精心设计的样本击败万级数据的事实,确立了能动性发展的全新原则:模型能动性来自精心构造,而非数据堆砌。当模型从思考型 AI 转向工作型 AI 时,LIMI 为真正能动性的可持续培养提供了新范式,开启了能动性发展的新纪元,未来充满无限可能。







