
传统 video dubbing 技术长期受限于其固有的 “口型僵局”,即仅能编辑嘴部区域,导致配音所传递的情感与人物的面部、肢体表达严重脱节,削弱了观众的沉浸感。现有新兴的音频驱动视频生成模型,在应对长视频序列时也暴露出身份漂移和片段过渡生硬等问题。为解决这些痛点,Infinitetalk 引入 “稀疏帧 video dubbing”。
这一新范式从根本上重新定义了 video dubbing,将其从简单的 “嘴部区域修复” 转变为 “以稀疏关键帧为引导的全身视频生成”。该模型不仅能够实现口型与配音的精准同步,更实现了面部表情、头部转动和肢体语言与音频所表达情感的自然对齐,消除长视频生成中的累积误差和突兀过渡。
InfiniteTalk 是由美团视觉智能部主导研发的新型虚拟人驱动技术,技术论文、代码、权重已开源。 美团视觉智能部能围绕丰富的本地生活电商场景,建设从基础通用到细分领域的视觉技术能力,包括视觉生成大模型、多模交互虚拟人,助力营销创意生产和商家低成本直播;文档、商品、安全多模态大模型,助力商家开店经营、平台商品治理和违规账号治理;人脸识别、文字识别、细粒度图像分析、高性能检测分割、街景理解成为公司基础设施能力。

- 项目主页:https://meigen-ai.github.io/InfiniteTalk/
- 开源代码:https://github.com/MeiGen-AI/InfiniteTalk
- 技术报告:https://arxiv.org/abs/2508.14033
我们先看示例:
一、引言 ——video dubbing 的一个长期痛点
长期以来,video dubbing 一直面临一个核心的 “僵局”—— 其编辑范围的局限性。传统的 video dubbing 技术,例如 MuseTalk 和 LatentSync,通常专注于对嘴部区域进行 “修复式” 编辑,以实现口型与新音频的同步。这种方法的主要局限在于,它几乎不触及人物的面部表情、头部转动和肢体动作。
这种 “局部编辑” 的策略导致了一个严重的矛盾:当配音表达出强烈的情感(例如激动、愤怒或喜悦)时,视频中人物的身体姿态却保持着僵硬或静止状态。例如,一段充满激情的对话,人物却只是面部肌肉轻微抽动,身体保持纹丝不动。这种视听信息的不一致性会严重破坏观众的沉浸感,使生成的视频显得不自然,缺乏说服力。这种矛盾感的存在,从根本上制约了配音视频的质量,并成为内容创作者亟待解决的难题。如图 1 所示。

随着人工智能技术的发展,一些音频驱动的视频生成模型应运而生,试图解决这一问题。然而,直接将这些模型应用于长 video dubbing 任务,同样暴露出新的、且同样关键的挑战。
首先是基于图像转视频(Image-to-Video, I2V)的方法。这类模型通常以视频的首帧图像作为初始参考,然后根据音频生成后续的视频序列。虽然这种方法在理论上提供了更大的动作自由度,但它存在严重的 “累积误差” 问题,如图 2 (left)。由于模型缺乏持续的原始关键帧作为锚定,在生成较长的视频序列时,人物的身份特征(如面部细节、发型等)会逐渐偏离源视频,甚至背景的色调也可能发生不可控的偏移,导致视频质量随时间推移而下降。
其次是基于首末帧转视频(First-Last-frame-to-Video, FL2V)的方法。该方法试图通过同时使用视频片段的起始帧和终止帧作为参考来解决累积误差。然而,这种策略带来了另一个问题:过渡生硬, 如图 2(right)。FL2V 模型生成过程缺乏从前一片段向后一片段传递的 “动量信息”,不同视频片段之间的动作衔接会显得突兀和不自然,打破了视频流的连续性。与此同时,其过于严格地遵循固定的参考帧,强制生成的视频在片段(chunk)的边界上精确复制参考帧的姿态,即使这种姿态与新音频的情感或节奏相悖。
这两种主流 AI 方案的局限性揭示了一个核心矛盾:即 “局部编辑的僵硬” 与 “全局生成的失控”。传统方法因编辑范围狭窄而僵硬,而新兴的 AI 生成模型则在长视频的连贯性上遭遇了挑战。

二、新的范式:稀疏帧 video dubbing
为了从根本上解决上述挑战,Infinitetalk 引入了一个全新的技术范式 ——“稀疏帧 video dubbing”。这一范式彻底改变了 video dubbing 的技术哲学:它不再将任务定义为对嘴部区域的 “修复”(inpainting),而是将其重构为一场 “以稀疏关键帧为引导的全身视频生成”。其核心理念在于,不是逐帧地、僵硬地复制源视频,而是策略性地仅保留和利用源视频中的少数关键帧(sparse keyframes)作为核心参考。这些关键帧如同 “视觉锚点”,在生成过程中发挥着至关重要的作用。
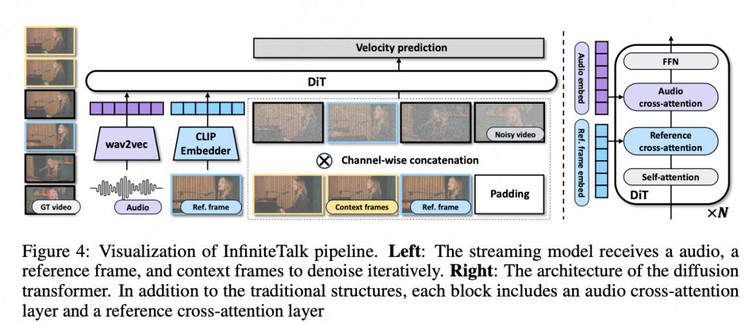
为了应对无限长度的视频序列生成任务,InfiniteTalk 采用了流式(streaming)生成架构,整体网络框架如图 4 所示。其工作原理是将一个超长视频分解为多个小的、可管理的视频片段(chunks),然后逐一进行生成。然而,与简单的分段生成不同,InfiniteTalk 的核心在于其精巧设计的 “上下文帧”(context frames)机制。
当模型生成一个新片段时,它不仅仅依赖于源视频的参考帧,还会利用上一段已生成视频的末尾帧作为下一段生成的 “动量信息”。这些上下文帧为新片段的生成提供了必要的 “时间上下文”,使其能够承接前一片段的运动趋势和动态,确保动作的连续性和流畅性。这一机制如同接力赛中的接力棒,将前一棒的冲刺动量无缝传递给下一棒,从而彻底解决了传统 FL2V 模型中因缺乏动量信息而导致的片段间突兀过渡问题。通过流式架构和上下文帧机制的结合,InfiniteTalk 成功地将 “片段生成” 任务提升为 “连续流生成”,这是其实现 “无限长度” 生成能力的技术基石。
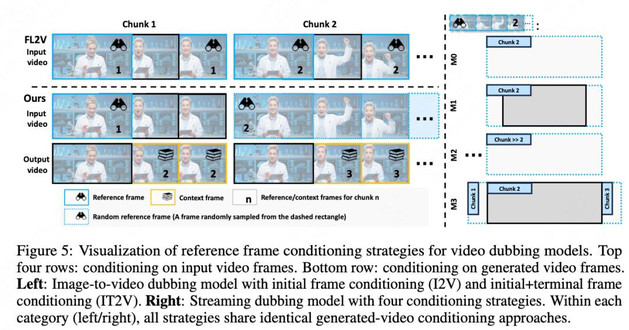
在 “稀疏帧 video dubbing” 范式下,一个关键的挑战是如何在 “自由表达” 与 “跟随参考” 之间找到微妙的平衡。过于严格地复制参考帧(如 M1 策略)会导致生成的动作僵硬,而如果控制过于松散(如 M2 策略),则又会面临身份和背景失真等问题。InfiniteTalk 的核心策略是采用一种 “软条件”(soft conditioning)控制机制 。该机制的核心发现是,模型的控制强度并非固定不变,而是由 “视频上下文和参考图像的相似度” 所决定 。基于这一发现,Infinitetalk 设计了一种独特的采样策略,通过 “细粒度的参考帧定位”(fine-grained reference frame positioning)来动态调整控制强度,从而在动作自然度与参考帧的保真度之间取得平衡。

如表 3 所示,M0 策略因随机采样而控制强度过高,导致模型不恰当地复制参考动作,削弱了同步性。M1 策略虽然在视觉质量上表现尚可,但在同步性上表现较差,因为它过于严格地复制了边界帧。M2 策略因参考帧与上下文帧的时间距离过远,导致模型对身份和背景的控制力不足,最终在视觉质量(FID、FVD)上表现最差。
最终被采纳的 M3 策略,通过在训练中从邻近分块(adjacent chunks)中采样参考帧,找到了一个 “最优平衡点”(optimal equilibrium)。这种策略既能确保模型在视觉上遵循源视频的风格,又能赋予模型根据音频动态生成全身动作的自由。
此外,该模型还能通过集成 SDEdit 或 Uni3C 等插件,实现对源视频中微妙的镜头运动(camera movement)的精确保留。这一点至关重要,因为它确保了生成的视频不仅人物动作自然,连画面的构图和运镜都与源视频保持一致,进一步提升了视频的真实感和连贯性。
三、实验数据与视觉实证
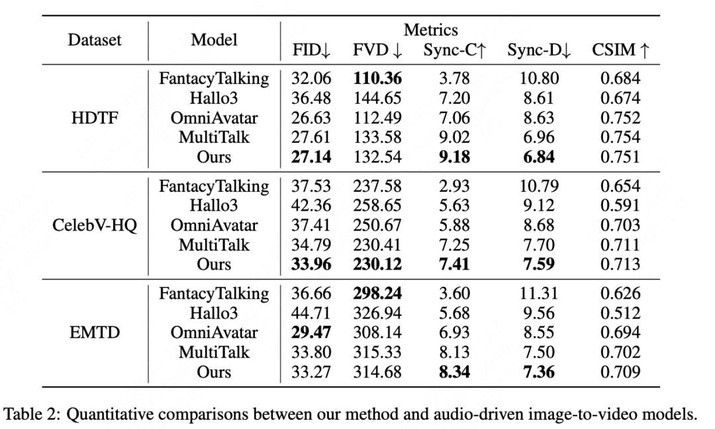
为了全面验证 InfiniteTalk 的性能,将其与多个方法进行了对比。

不同相机控制方法的对比:

四、结语与展望
InfiniteTalk 成功解决了 “僵硬” 与 “断裂” 两大痛点。其核心技术 —— 流式生成架构、软条件控制以及全方位同步能力,共同为高质量、长序列的视频内容生成提供了新的解决方案。在短视频创作、虚拟偶像、在线教育以及沉浸式体验等领域,这项技术可以为创作者提供强大的工具,以更低的成本、更高的效率生成富有表现力的动态内容,彻底打破现有制作流程的瓶颈。







