
凌晨 2 点 25 分,作者顶着熊猫眼,把智谱最新开源的 GLM-4.5V 大模型狠狠测了一遍,结论是——这 106B 参数的多模态“怪兽”不仅看得懂、算得快,还干得漂亮。保姆级教程、安装包、API 白嫖指南全打包,5 分钟让你的电脑也长出 AI 眼睛和大脑。

我真是有点服,智谱又又又发布了新模型。

然后又给开源了。生产队的驴都不带这么卷的,我都怀疑智谱是不是嗑药了。
7 月初开源 GLM-4.1V-Thinking,上周开源 GLM-4.5 和 GLM-4.5-Air,今天又开源了个 GLM-4.5 V。
晚上我听了他们的直播发布会,几个青涩的年轻人给介绍了这次发布的模型,时间很短,但却不简单。
我想第二天一定会有超级多的人来测,来玩,导致卡的无法使用。基于前车之鉴,我还是打算今晚就给测完,痛快的体验下它的能力,
现在是凌晨 2 点 25,终于测完了,还好,这次没到五点,说明有进步,不然明天去上海怕是顶不住。
先说我测试下来的结论吧:GLM-4.5V 模型在多模态能力上表现很好,特别是在图像/视频理解、视觉定位上表现优异。
现在同样可以在 z.ai 体验,但作为开发者,我更倾向于用 API 方式来验证一些东西。
恰好他们开源了个桌面助手 vlm-helper,于是以下我所有的测评都基于该桌面助手。
我也会在文章后面给出该桌面助手的安装包以及教程。
当然,按照惯例,在放真实测评前,还是要放一放模型的跑分情况(虽然大家都看麻了)
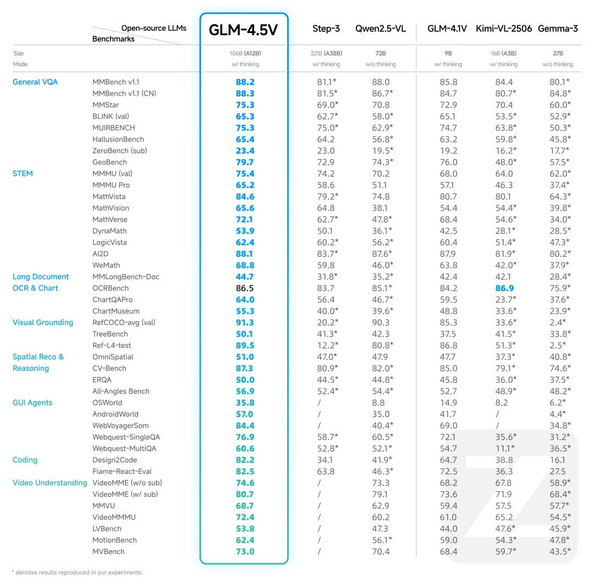
可以看出在 42 个公开视觉多模态榜单中综合效果达到同级别开源模型 SOTA 性能,涵盖图像、视频、文档理解及 GUI 任务等常见任务。
据官方介绍,GLM-4.5V 是基于智谱新一代旗舰文本基座模型 GLM-4.5-Air,延续 GLM-4.1V-Thinking 技术路线,是一个拥有106B总参数,12B激活的视觉推理模型。
但口说无凭,真实体验如何,还得实际测试。下面开整。
前端复刻
官方直播的视频放出了复刻带有交互的知乎网站。而且是通过录屏的方式,看着挺厉害的。
但像这类公开的网站早就不知道被大模型训练了多少次了,参考意义不大。
于是,我灵机一动,何不复刻下我的开源项目 PmHub?这够小众吧。
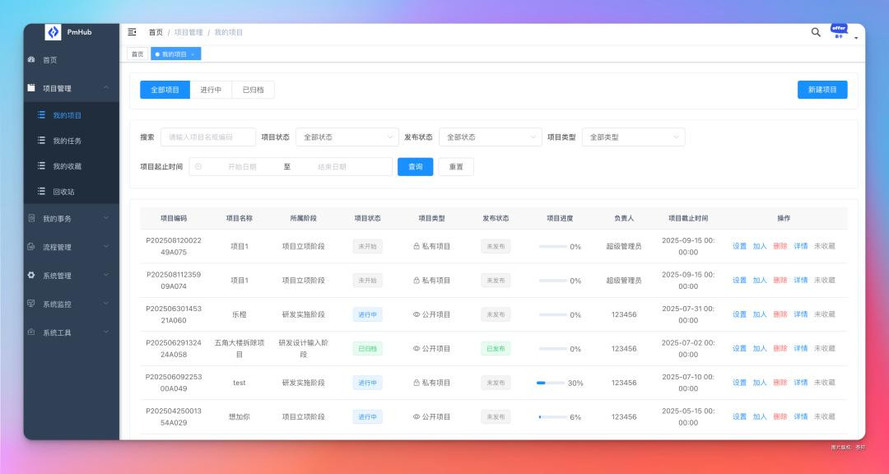
于是,我也对着 PmHub 录了个屏,也就是正常点击页面的功能。然后吧视频丢给 vlm-helper,GLM-4.5 V 识别理解视频内容和操作,然后按照要求输出代码。
我的提示词是这个:
请根据提供的多张网页 UI 截图,复刻出完整的交互式网页,实现整个网页的点击、跳转、交互等功能,请注意,每一张UI截图都会对应某个操作,请务必实现点击、跳转等交互操作,不要在thinking过程中思考html code怎么写。最终返回一个完整html code。
我把前端效果做了个对比:
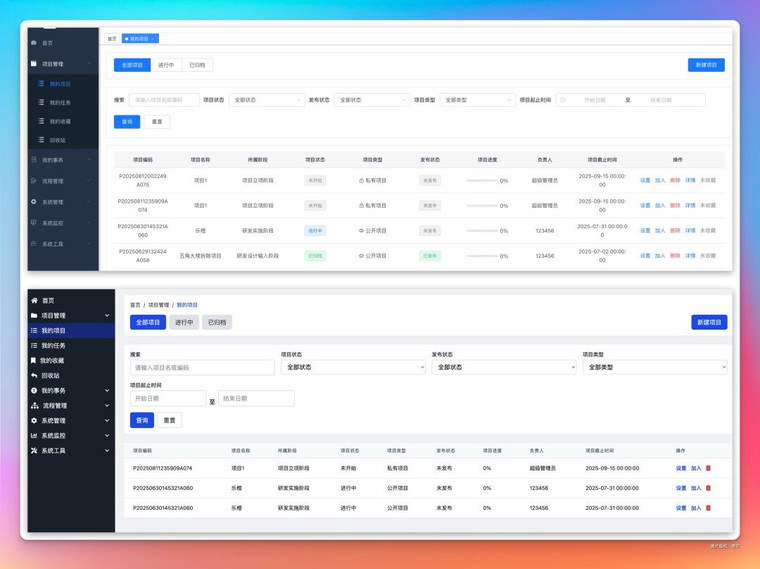
就单单从前端复刻能力上,没啥意思,因为像 Weavefox 和same.new 这样的工具做的细节会更到位。
但就从视频理解整个页面交互,这个就很吊了。这种感觉就好像 GLM-4.5 V 长了个眼镜,又带了个大脑,能看能理解,最后还能咔咔一顿编码输出。
图像理解
下面是对多模态能力进行测试,但因为是 AI 桌面助手,我觉得在我们的测评中还是要以实际的工作学习场景展开。
所以以下 case,均模拟真实需求场景。
1、找出性价比最高的商品
最近在厦门抽了中了个手机,一直想着买个手机壳,但一搜,就蹦出一堆出来,容易让人挑花了眼。
我其实就一个需求,选个性价比高的,就够了。
于是我一截图,输入需求然后一回车,GLM-4.5 V 就给我推了个最具性价比的手机壳。
这里考察的是模型对图片的理解能力,以及逻辑计算能力。GLM-4.5 V 表现不错。
2、微信回复
我每天对着电脑要花费非常多的时间在微信上,有时候是工作,有时候是摸鱼吹水。
就比如在吹水群,好朋友 kk 碰到奇葩的抱怨,作为钢铁直男,我一时不知道该怎么回复好。
于是我让桌面助手捕捉我的屏幕中微信聊天记录,它就给了我一个没那么尴尬的回复。
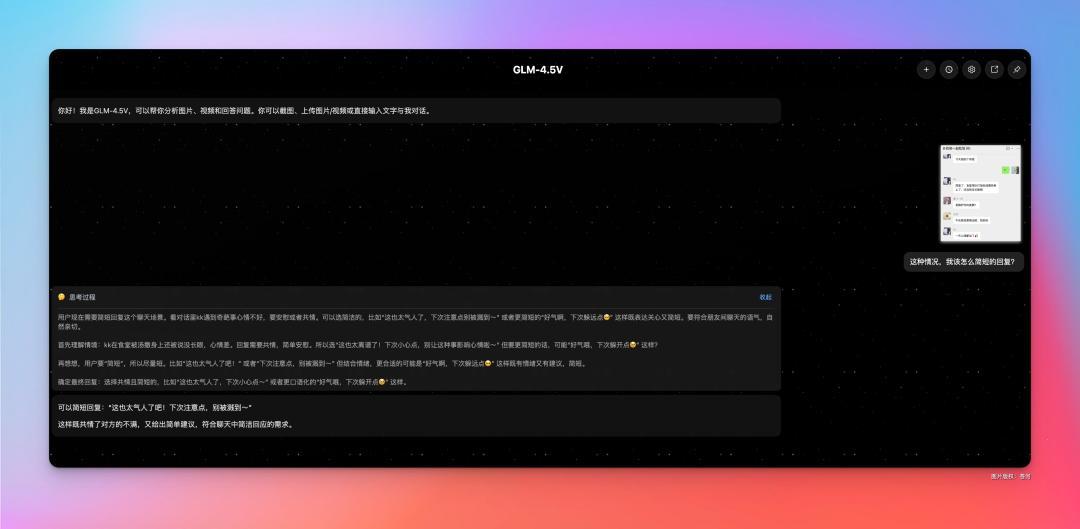
讲真,如果我要回,我估计是先破口大骂帮问候一下这奇葩,但 GLM-4.5 V 理解到了,此时,kk 或许更需要的是共情以及安慰。
虽然它还没法直接帮我发消息,但这个情商是比大多数直男都高的(包括老苍何)
3、朋友圈旅游照定位
朋友圈经常会看到旅游照,有时候除了羡慕之外,也特别想知道这是去的哪儿耍呀,但又不好意思评论区或者私信直接问。
生怕暴露了自己穷屌丝的本质,现在,我将朋友圈共享给 GLM-4.5 V,然后问它:这是哪儿。
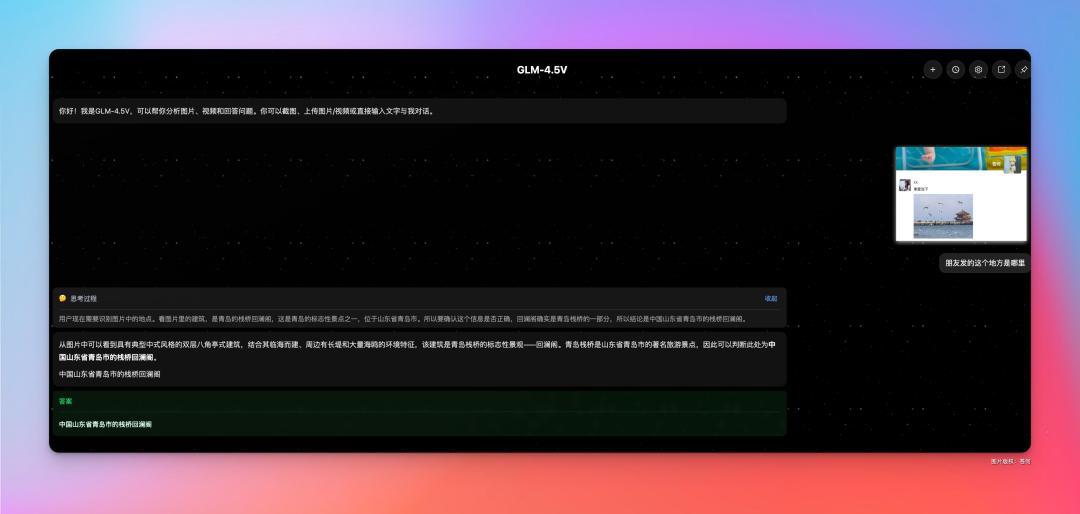
GLM-4.5 V 凭借对图片特征的提取,能给出是哪里。
不瞒你说,就 kk 发的这个图,我一时还真没想到会是在青岛,虽然,我在青岛呆了 4 年。。。
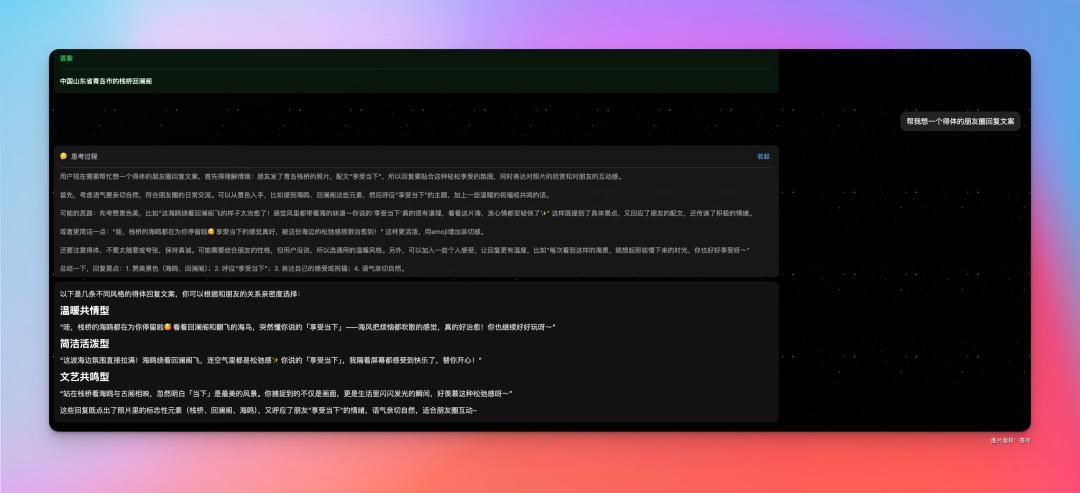
顺带,让懂事的 GLM-4.5 V 给 kk 来个回复评论吧,真好,有了 AI,倒是省去了很多我不必要的思考。
4、验证码任务完成
虽然我是做软件的,我能理解很多网站为了安全加固,会喜欢搞比较麻烦的验证,来证明自己是个人。
就比如智谱他们自家的这个登录验证:
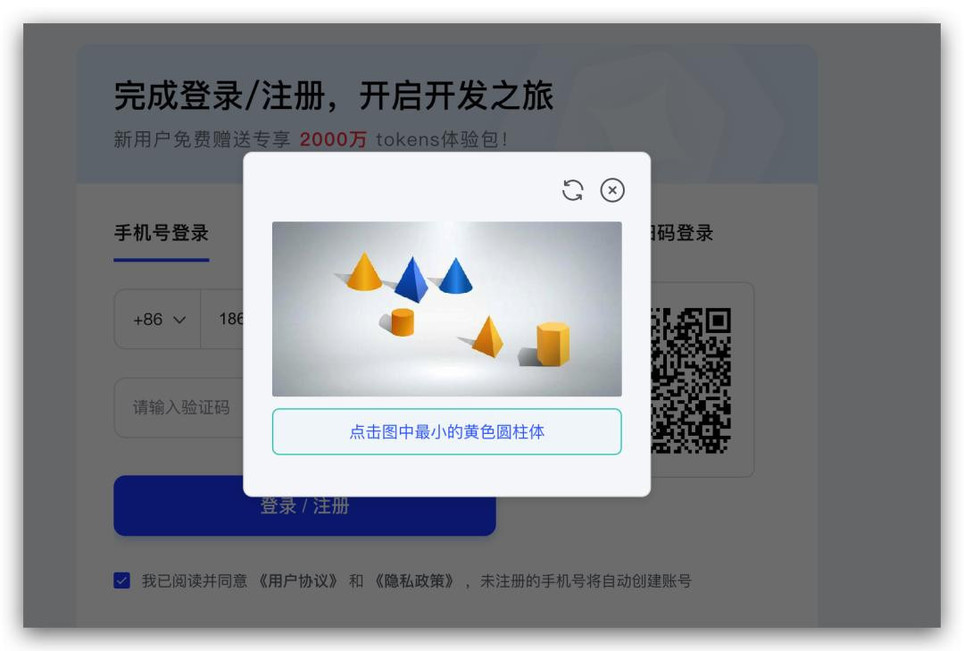
对于我这眼神不好的来说,每次还是挺费劲的。
现在好了,把这个丢给 GLM-4.5 V,它直接把答案给你标注出来,这家伙,配合上 Agent,不是全自动化绕过验证?
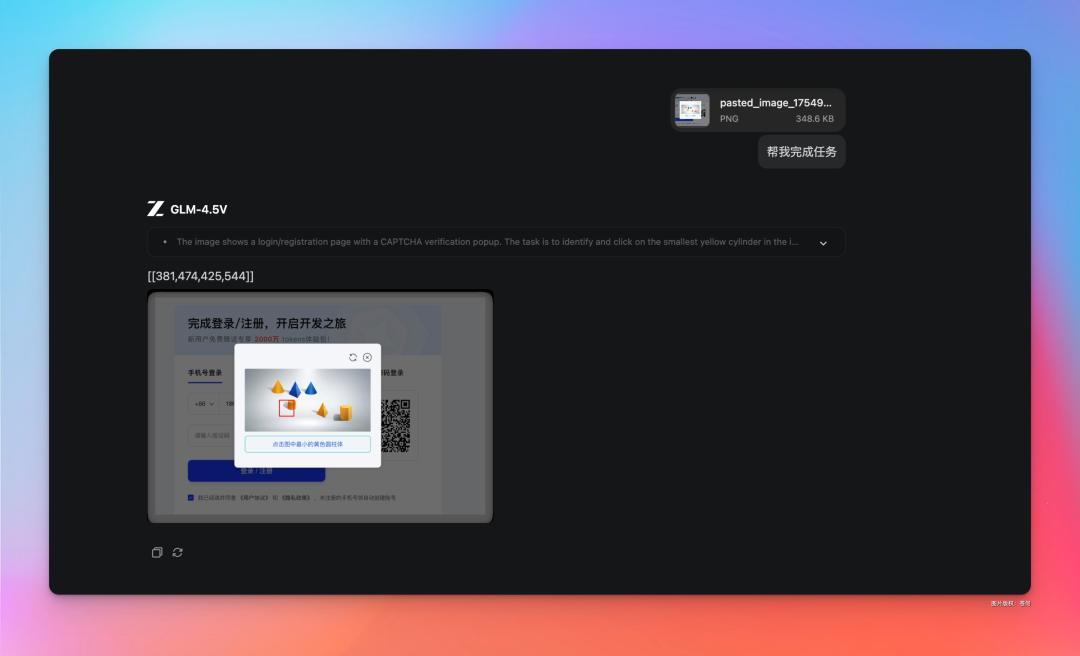
你感受一下:
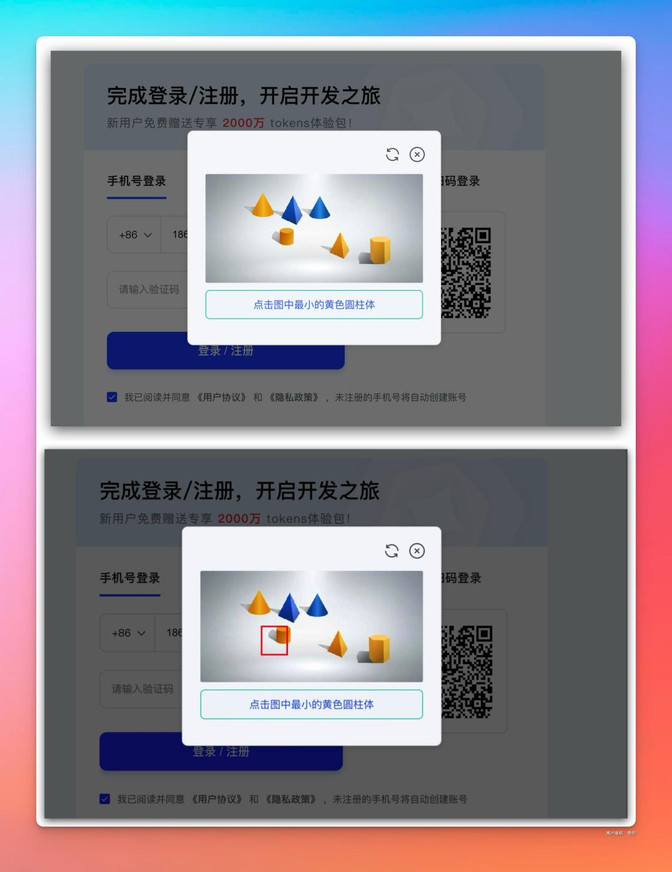
真实道高一尺魔高一丈,估计智谱法务得好好加班研究研究应对之策了,不然像 12306 这种最痛苦的验证方式,不也能分分钟破解?
你还别说,基于此,我还真就做了个小工具,让你绕过所有的强制性验证。
视频理解
除了图片理解,我觉得更难的是视频的理解能力,而最为重要的也是视频理解的能力。
因为我们的物理世界是三维的,而非二维的,对视频的理解,是通过 AGI 的重要手段。
下面看几个比较有用的 case:
1、视频课程学习
上传一个 7 分多钟,大小 19.7 M 的 java 学习视频,来拷打一下:
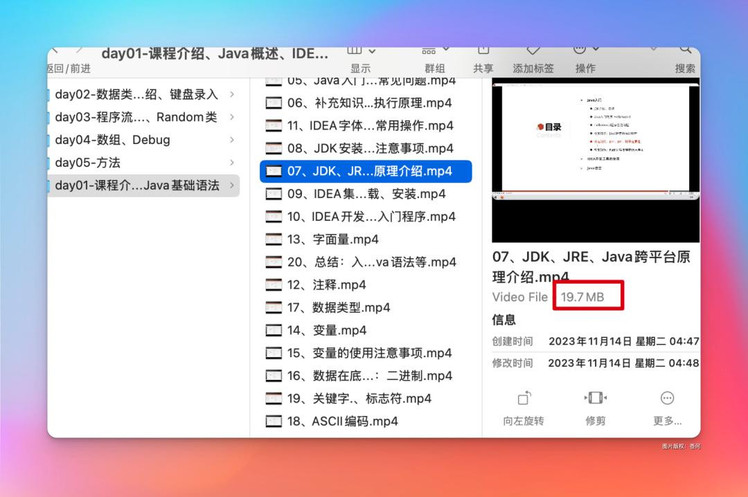
让它帮我梳理总结下这个课程的内容:
总结的不错,可惜我当年学习 Java,没这方便。这个场景在学习办公下都非常有用。
我们可以总结会议内容,电视剧剧情,电影经典场面等。
3、GitHub 项目学习
我经常会逛 GitHub 充电学习,但很多的开源项目都是英文的,看起来不顺畅,就比如 GLM-4.5 V 这个开源项目,默认也是英文。
现在,我让桌面助手中的 GLM-4.5 V 直接帮我介绍这个项目,非常实用。
翻译
当然还有个场景就是翻译,对于非网页类的场景,翻译起来还真不容易,需要先截图,然后 OCR 识别,最后再找翻译工具。
这个过程一度很痛苦,现在不用,直接让桌面助手来处理,分分钟翻译好了。
表格/图表转换
我觉得还比较实用的场景是做表格/图表转换。
基于 GLM-4.5 V 的图像理解能力,能准确识别表格和图表信息,然后按照指定格式输出。
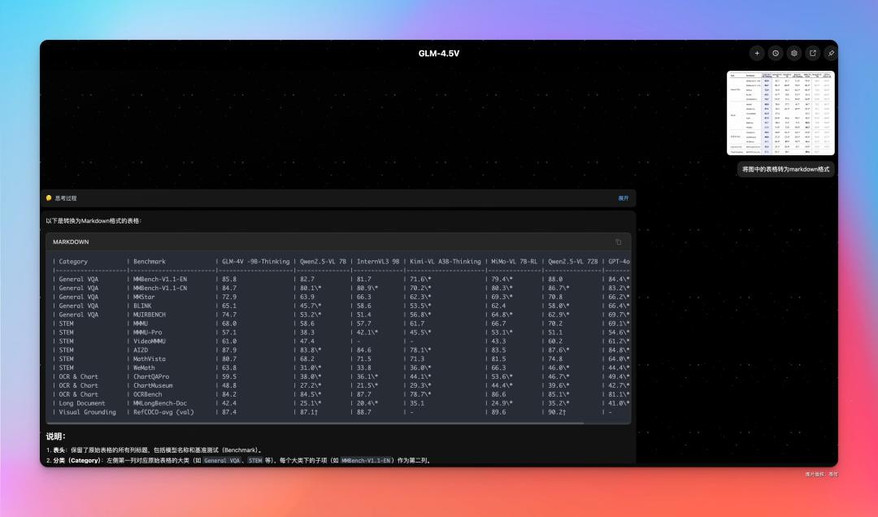
非常方便,而且不用工具切来切去,就用桌面助手就 OK。
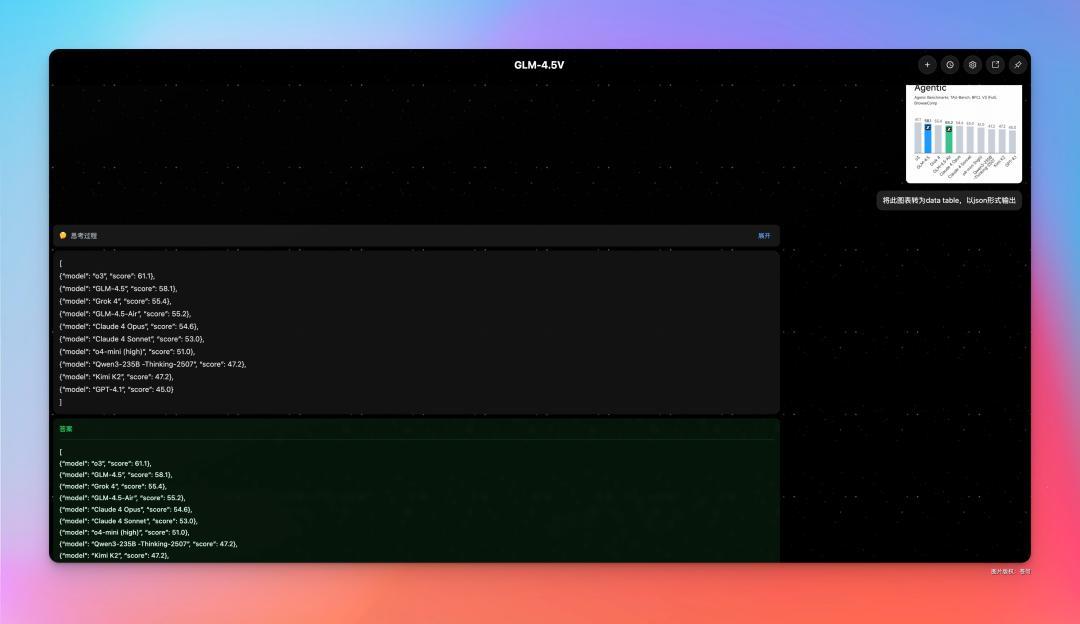
视觉定位
GLM-4.5 V 的视觉定位能力很强,而且这个的应用场景会非常多。
比如我要在众多复杂的场景中,精确找到符合的人物:找到桥下的一条船,船上有两个人

反正这,我要找,确实得找半天。
再比如,在人多的商场,找到背着双肩包穿灰色短袖的年轻男子。
感觉 GLM-4.5 V 接入安防监控,会是非常好的场景啊。
我想 GLM-4.5 V 开源后,一堆的硬件落地产品又会出来了。
而且为了考考 GLM-4.5V 看图猜位置的能力,智谱让 GLM-4.5V 参加了图寻游戏的全球积分赛,和国内最顶尖的两万多名人类玩家真实对战。
GLM-4.5V 就击败了 99% 的玩家。
GUI Agent
这个能力感觉是为了之后的 AutoGLM 铺垫的,也就是能通过看到的 GUI,配合 Agent,完胜指定的操作。
我录了个官方的视频介绍,不得不说,期待性直接拉满。
好啦,测评就结束了,你可以看到,这次 GLM-4.5 V 的更新,也同样的有点超出预期了。
下面,是如何部署 AI 桌面助手的教程,主打一个有手就行。
部署教程
打开安装包直接安装。
安装包可以后台留言下载:vlm-helper
打第一次开会报这个错:
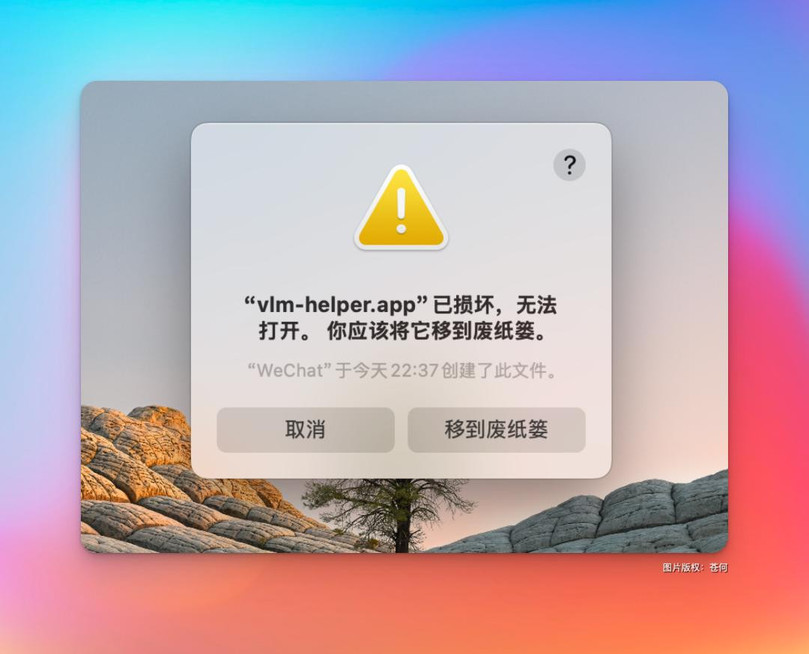
没关系,终端中输入以下命令执⾏安全限制解除命令,然后重启应用就好。xattr -rd com.apple.quarantine
/Applications/vlm-helper.app
接下来,配置一下 API,点击右上角的设置,选择模型设置。(这里有个小 tips,一定要开启「智谱 Mass 模式」,当然默认就是开启的,不要手滑关掉就好啦)
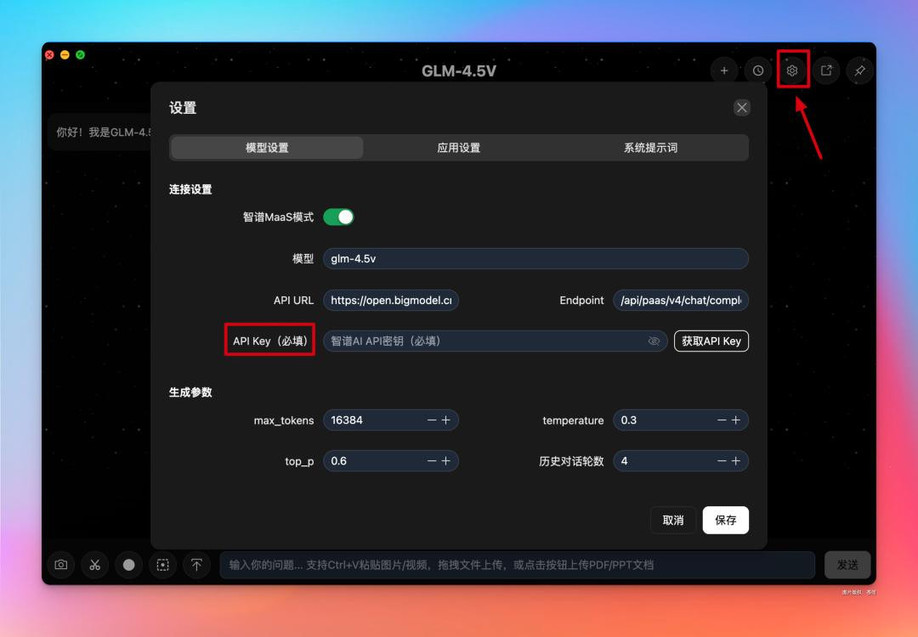
点击右侧的获取 API Key,就会跳转到智谱的 BigModel 平台。
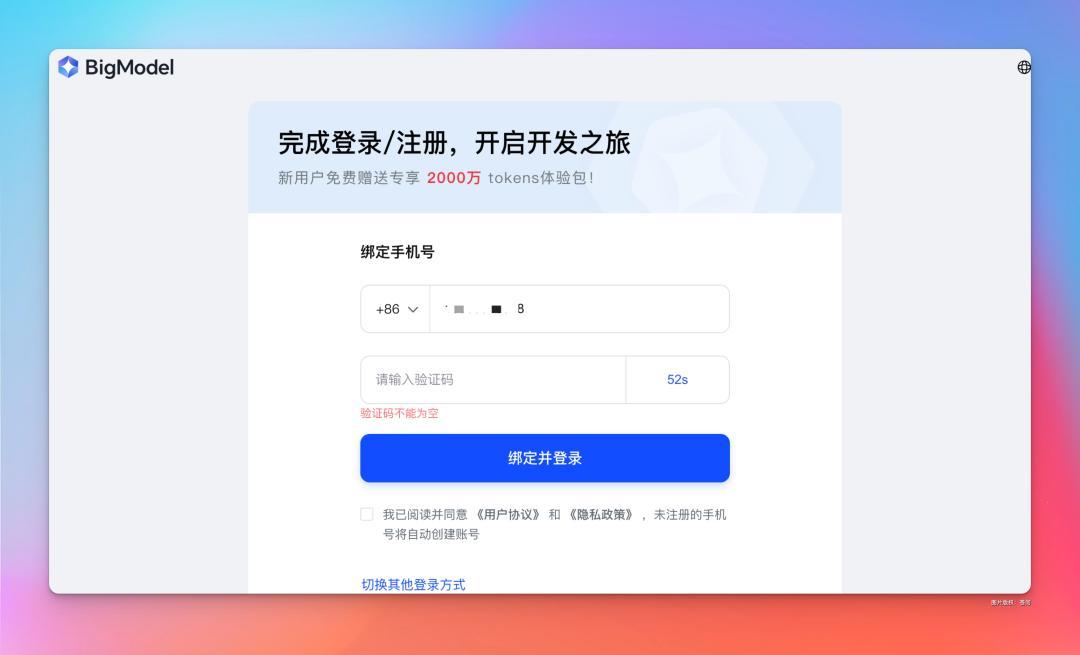
现在新用户可以免费领取 2000 万 tokens 体验包,够玩一阵了。
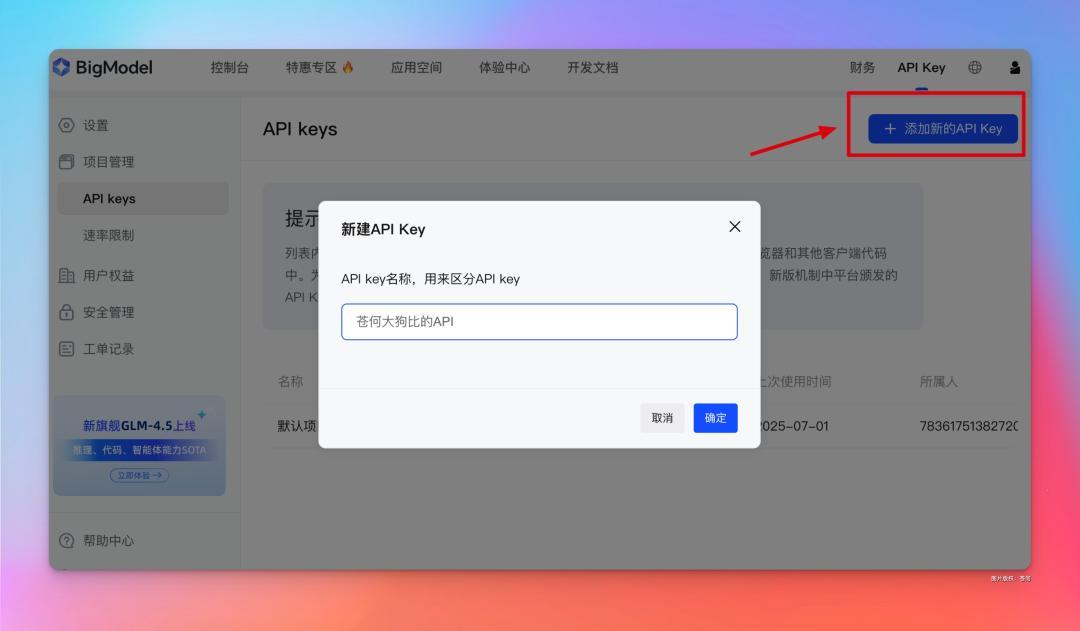
把新建的 API Key 复制到 Vlm-helper 客户端, 点击保存就算完成。
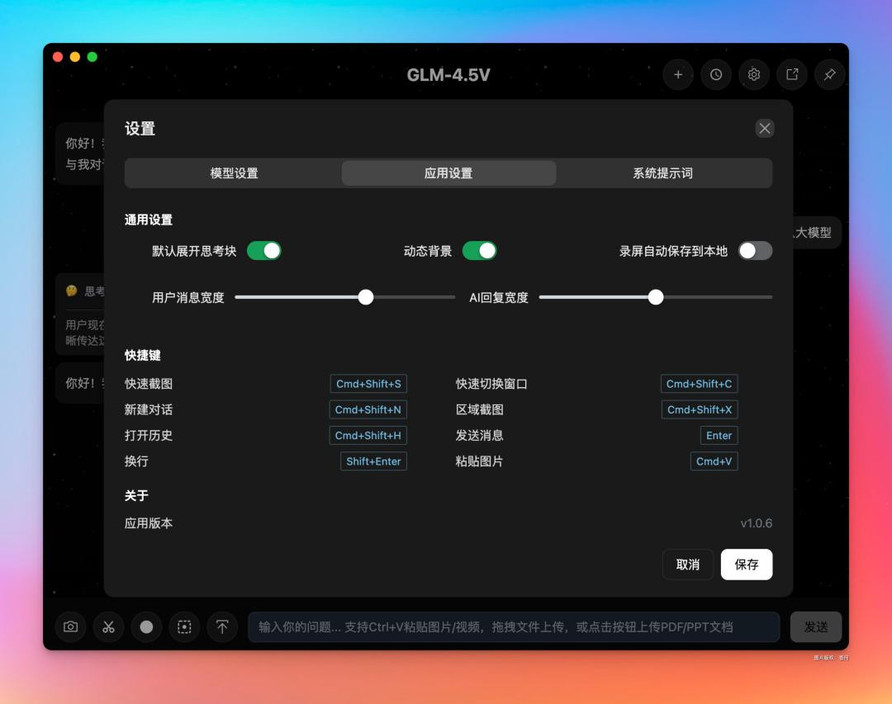
除此还可以进行应用设置和系统提示词设置。有不少快捷键还是很有帮助的。
先试试是否生效:
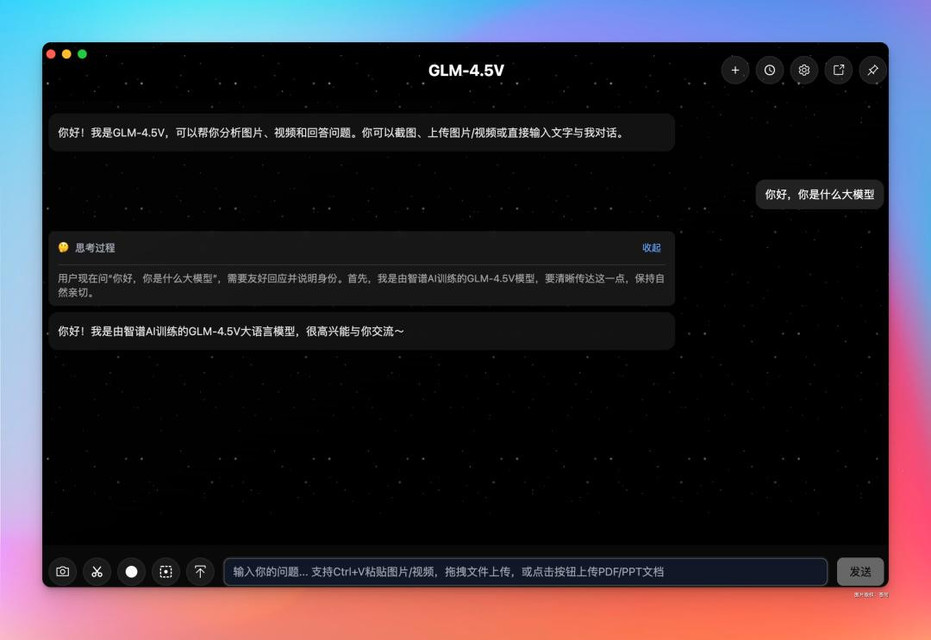
该说不说,回复真的好快。
这样就生效啦。
在 AI 的路上,有些人,用力的冲了。
但因为没短期获得他们想要的,他们又撤了。
但有另外一群人,他们从一开始就在冲。
不管外面的风雨如何变化,
他们始终相信 AGI 会到来,并为之不断努力。
我觉得智谱这帮人就是这样一群人。
当然,我也希望屏幕前的你和我同样也是这类人。
我们始终相信:AGI 一定会到来的。
本文由人人都是产品经理作者【汪仔6818】,微信公众号:【苍何】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







