8月4日,小米公司正式宣布开源其自研的声音理解大模型 MiDashengLM-7B。

该模型在22个公开评测集上刷新了多模态大模型的最好成绩(SOTA),并在推理效率上实现了显著突破,标志着小米在音频多模态AI领域取得重要进展。
功能亮点
音频描述:将音频内容(包括语音、环境声、音乐等)转化为自然语言描述,帮助用户快速理解音频信息。
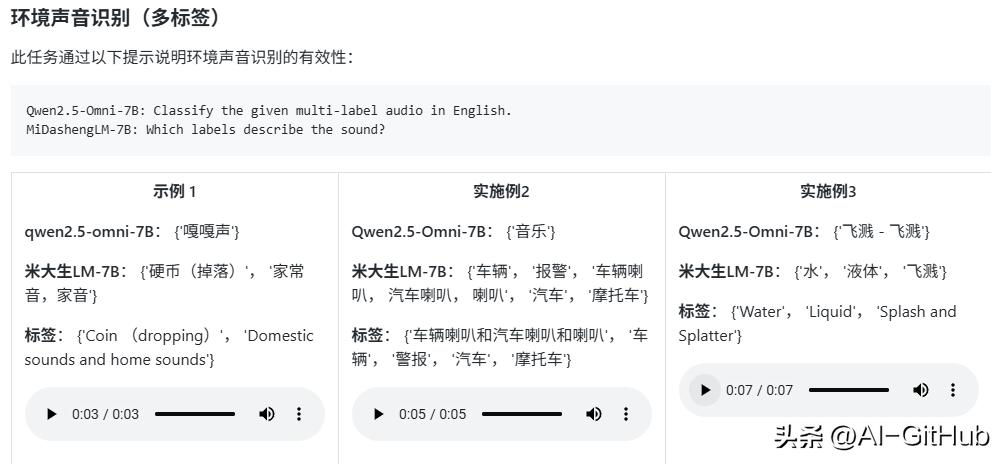
音频分类:识别音频中的特定类别(如语音、环境声、音乐等),用在环境声音识别、音乐分类等场景。
语音识别:将语音转换为文本,支持多种语言,广泛应用在语音助手、智能座舱等场景。

音频问答:根据输入的音频内容回答相关问题,适用智能座舱中的环境声音问答、音乐问答等。
多模态交互:结合音频和其他模态(如文本、图像)进行综合理解,提升智能设备的交互体验。
音频理解与推理能力
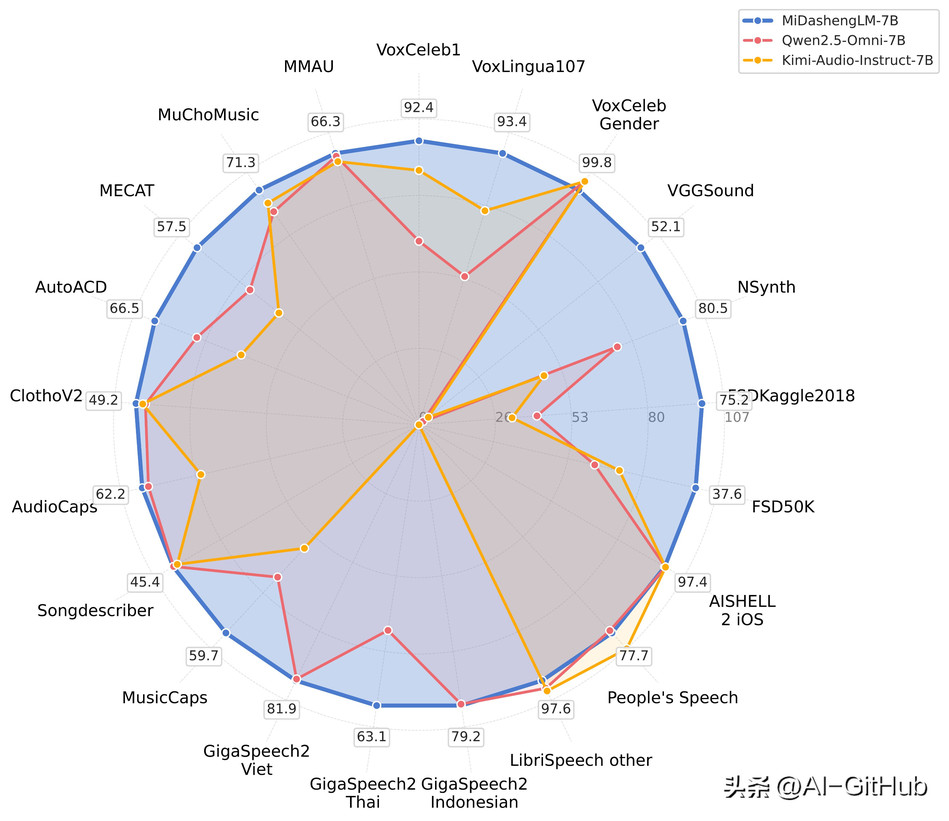
音频理解性能领先
MiDashengLM在音频描述、声音理解、音频问答任务中有比较明显的优势:
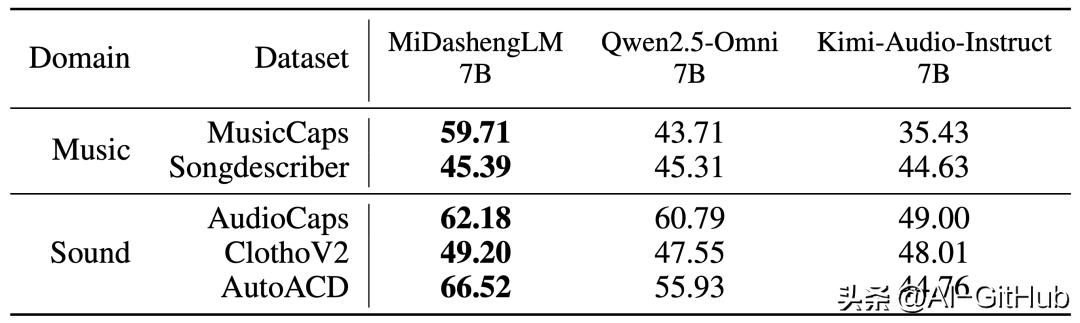
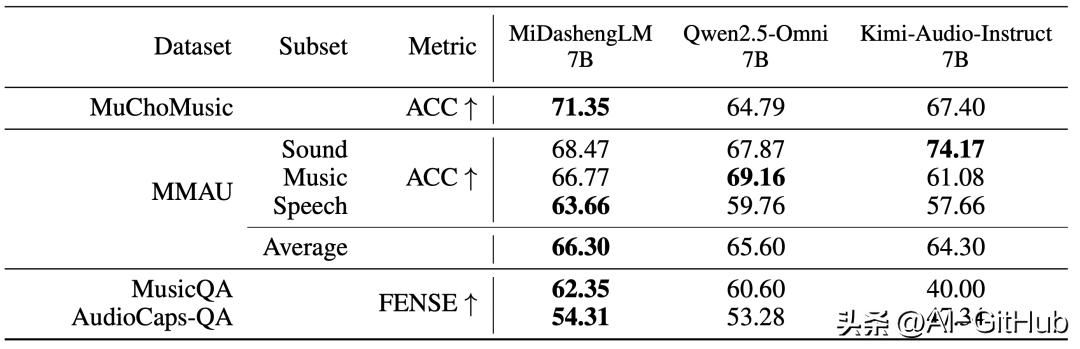
在音频描述任务中,MiDashengLM-7B比Qwen、Kimi同类7B模型性能更强。
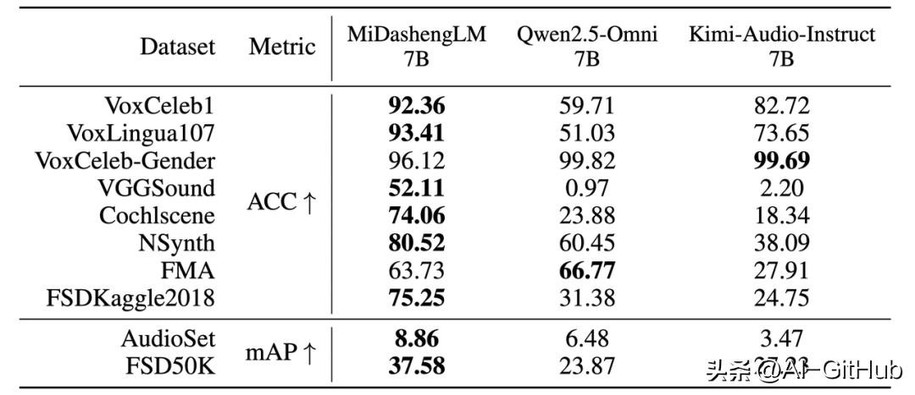
在声音理解任务中,MiDashengLM-7B与FMA、VoxCeleb-Gender项目均领先于Qwen的7B模型,与Kimi的7B模型相比,仅有VoxCeleb-Gender项目略微落后。
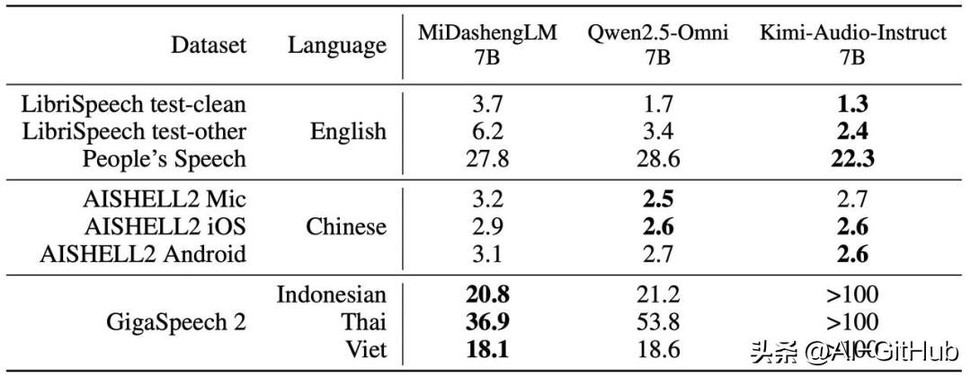
在语音识别任务中,MiDashengLM-7B的主要优势在于GigaSpeech 2,在其他两组测试中Qwen和Kimi有一定优势。
推理高效
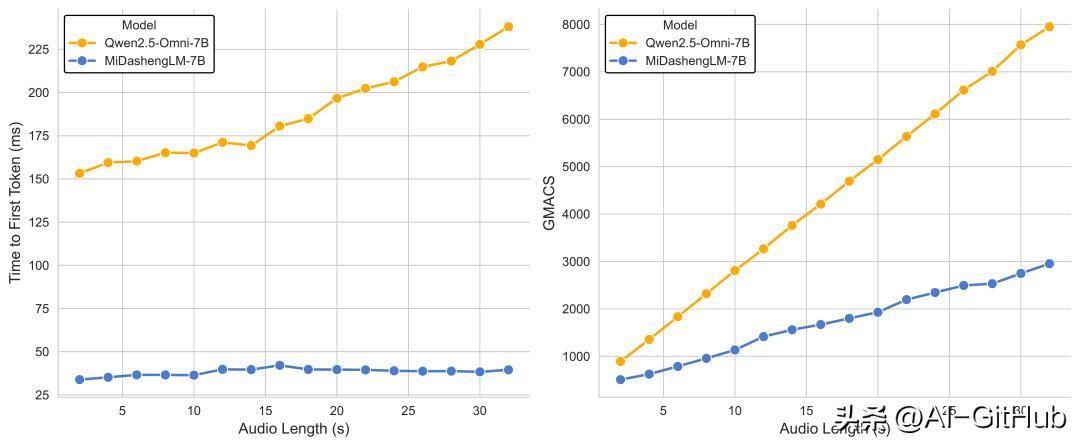
首Token延迟低: 在单样本推理(batch size=1)场景下,其首个Token预测时间(TTFT)仅为业界先进模型(如 Qwen2.5-Omni-7B)的 1/4。
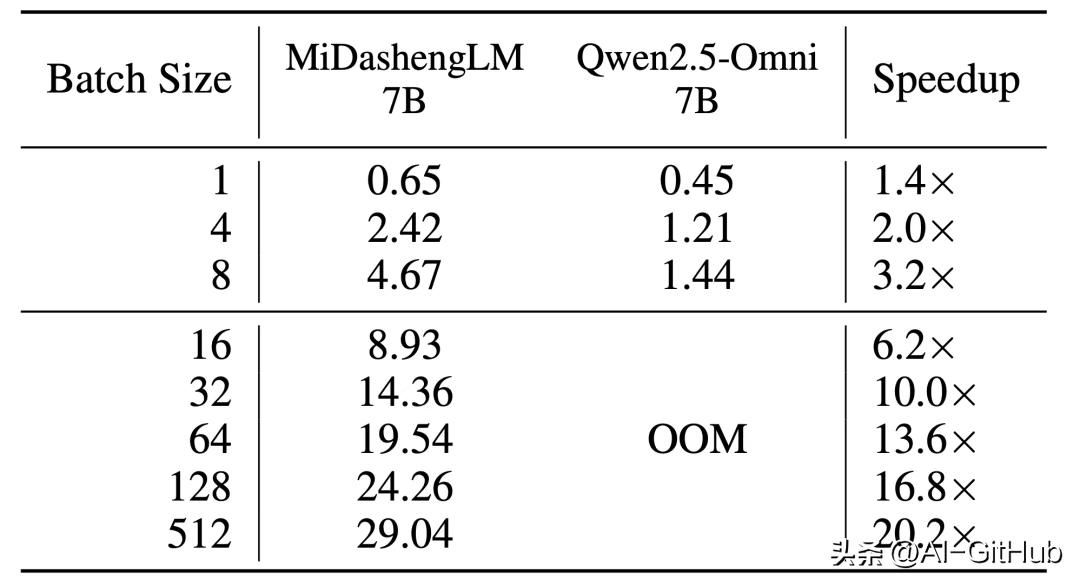
并发能力极强: 在80GB GPU显存环境下处理30秒音频并生成100个Token的测试中,MiDashengLM-7B 可支持高达 512 的batch size,而对比模型在batch size为16时即出现显存溢出(OOM)。其每秒可处理的30秒音频数量远超同类模型。
MiDashengLM-7B 的开源是小米在AI多模态领域,特别是音频理解方向上的重要落子。其在性能、效率上的突破,以及创新的训练范式和全栈开源策略,为学术界和产业界提供了强大的新工具。
GitHub:https://github.com/xiaomi-research/dasheng-lm
#AI开源项目推荐##AI技术##github##小米开源##AI语音理解模型#TTS模型







