随着生成式 AI 技术的以惊人的速度迅猛发展,AI 已逐渐渗透到大家日常工作或生活中的各个领域。作为一名互联网程序员,除了会使用 AI 技术提效外,更是得“折腾折腾”,学习下 AI 背后的技术原理。
在去年 11 月,由 Anthropic 团队提出的 MCP(Model Context Protocol)相信大家肯定不陌生,MCP 如同 USB-C 接口般通过统一协议实现 LLM 与外部能力的高效互联。对 MCP 的概念在此就不过多介绍了,搜索引擎随便一搜就有大把 MCP 科普文章。而本文想讲点不一样的干货:
MCP 如何让大模型与外部系统互联的?
如何实现 MCP Server?
MCP Gateway 实践
MCP 代码原理剖析
大语言模型(LLM)的回答通常会受限于训练数据,它们缺乏对实时数据的认知,例如让大模型查询今天天气、股票价格等是不可能的。让我们举个 OpenAI 官网的栗子,咨询一下 gpt-4o-mini:“今天北京的天气怎么样?”。此时,LLM 会因为预训练数据中没有相关答案,而无法回答这个问题。如图所示:
 <!---->
<!---->Tool Calls
Tool Calls 则为大模型提供了一种灵活的方式,使 LLM 能连接到外部数据和系统(本地代码、外部服务)。但 Tool calls 并不是 LLM 模型本身独立的能力,实际执行函数的环境不是在 LLM 内部,而是在外部系统中,这些外部系统可以是本地代码,也可以是独立运行的系统服务,LLM 模型可以通过自然语言输出的方式间接控制外部系统的执行,看起来就像 LLM 模型会以自己调用并执行 Function 一样。
以 OpenAI 官方的交互流程示例,LLM 与 Tool Calls 交互如下:
 <!---->
<!---->总结来说,在使用 Tool Calls 时,会产生两次大模型调用:第一次,让 LLM 决定调用哪个工具,按照协议返回工具入参。第二次,将工具执行结果放入上下文,大模型返回结果。
Talk is less, show code。下面将用实际代码来具象化描述执行过程:
a)首先,注册一个查天气的工具(tools)
本地写好 get_weather 方法,为了方便演示效果,该方法永远返回“22 度”。
将 get_weather 函数加入到的 tools 列表中(tools 是一个对象数组)。
为 get_weather 函数描述它的作用(description,description 的质量好坏能直接影响 LLM 是否能正常进行工具调用),描述它的入参规范(类型、参数名、参数含义、是否必传)。
 <!---->
<!---->这样,一个能根据经纬度获取天气温度的工具,就注册好了。
b)调用 LLM 时,将 tools 作为参数传入 LLM,由 LLM 决定是否调用工具
引入 openai SDK(python),将 tools 工具集作为参数传入到 completions-chat 中进行 client 初始化。此时,LLM 会根据用户问题,以及传入的 tools 工具集,来决定是否调用工具。
此例中,LLM 判断需要调用 get_weather 工具来获取北京的天气结果,所以,LLM 返回的结果中,message.content 为 None,message.tool_calls 中,返回了需要被调用的工具名称、入参。
需要注意的是,如果 LLM 判断不需要调用工具时,则会直接在 mesaage.content 返回答案。
 <!---->
<!----> <!---->
<!---->c) 执行 Tool 工具将工具执行结果放入上下文,并第二次调用 LLM
依据 LLM 返回的工具方法名称和入参,我们即可以在本地执行函数,拿到 get_weather 执行结果。
 <!---->
<!---->将 get_weather 的执行结果,以 tool 角色添加到 messages 中,同时发起第二次 LLM 调用。
模型返回结果 message.content => “今天北京的天气是 22 度。”
 <!---->
<!---->相信大部分开发者习惯用 Langchain 等优秀框架,在 LLM 中使用工具调用,感觉就一个 SDK API 调用就完事了。诚然,Langchain 为用户做了极其友好的,开箱即用的各种 API,方便开发者们快速构建 AI 应用,但是在提供各种开发便利的同时,Langchain 屏蔽了很多底层实现细节。希望本例中实际代码,能帮助大家更进一步了解 Tool calls 背后的实际工作原理。
读到这里,或许有人就会有疑问了,不是讲 MCP 吗?怎么就一直在讲 Tool calls?别慌,这就来。
MCP 协议详解
首先,在你的应用第一次向一个 LLM (比如 OpenAI 的 GPT、Google 的 Gemini 或 Anthropic 的 Claude)发送请求后,一旦 LLM 决定使用外部工具来回答你的问题时,不同 LLM 厂商返回的工具调用指令 的数据结构不同的,例如:
OpenAI (GPT):会在响应的 message 对象中包含一个 tool_calls 数组,数组中每个元素格式如下:
Anthropic (Claude):会在响应的 content 数组中包含一个 tool_use 代码块
Gemini(Google) 格式如下:
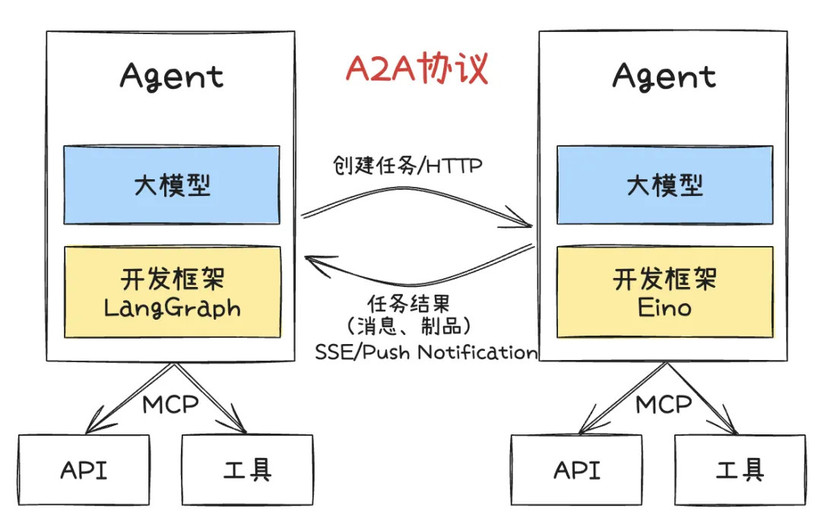
往往开发者需要针对不同的 LLM 厂商所返回的工具调用指令做不同的数据格式适配,接入的 LLM 越多,这个适配过程越痛苦。MCP,则是一个基于 JSON-RPC 2.0 的开源协议,创建一个标准化的中间层,像一个”通用适配器“一样,旨在统一 LLM 与外部工具调用的交互方式,解决了因不同 LLM 返回的工具调用指令格式不一所带来的适配工作量问题。
在没有 MCP 之前,我们可能需要这么做:
def process_llm_tool_call(response: dict, provider: str):"""接收来自不同 LLM 的响应,解析其独特的工具调用格式,然后执行本地工具。这是适配工作量集中的地方。"""tool_name = Nonetool_args = {}
可以看到,示例中存在大量”胶水“代码,增加开发者工作量,但有了 MCP 协议之后:
所有的 MCP Server 上的工具接受如下形式的请求结构:
所有的 MCP Server 返回数据结构(也即 MCP client 接收到的响应):
MCP Client 中将不同 LLM 返回的工具调用指令适配为 MCP 协议规定的请求体格式、发送到 MCP server 并解析结果,最终返回给用户。对开发者而言,只需要关注 MCP Server 的实现细节,MCP Client 会自动将各个大模型的输出转换为标准请求,开发者无需关心模型间的差异。
MCP 调用实践
讲完 MCP 协议,示例下如何用 langchain_mcp_adapters + langgraph 去调用 MCP Server:
找到提供服务的 MCP Server 地址
此例中,我们集成了 Doris MCP server,该 server 背后连接了贝壳商机平台中的 Doris 数据库。
初始化 LLM Client
Langgraph 是 Langchain 生态系统中的一部分,专门用于构建基于 LLM 的复杂工作流和 Agent 系统,示例中使用 Langgraph 中的 create_react_agent 来初始化 LLM Client。
create_react_agent 需要传入两个参数,一是大模型 model,二是外部工具列表,使用 client.get_tools 可以直接获取 MCP Server 上所有的工具列表。
该 MCP Server 背后提供 8 个 tools,功能分别如下:
 <!---->
<!---->写模型 prompt
在 prompt 中让 LLM 执行三个数据库操作:1) 获取所有 Doris 数据库名称,2)根据库名获取库下所有表名 3)执行一段 SQL 并返回结果。
可以看到,大模型最终返回的结果中如预期的分别执行了以上的数据库操作。在传统的工作流编排中,一般是需要实现「意图识别->参数提取-> API 调用->结果解析」 的,这一定程度上会抑制模型的智慧,而使用 MCP Server 则让 LLM 充分的自主决策是否选择调用外部工具,充分发挥大模型的智慧,并且随着以后大模型能力的快速迭代和提升,准召率也会自然而然随之提升。
本例中使用了 OpenAI 的模型,如想更换为 Google 的 gemini 模型或者 Anthropic claude 模型,直接替换 model 变量即可,无需更多代码适配的开发量。