时令 发自 凹非寺
量子位 | 公众号 QbitAI
AI通过自问自答就能提升推理能力?!
这正是卡内基梅隆大学团队提出的新框架SQLM——一种无需外部数据的自我提问模型。

该框架包含提问者(proposer)和解答者(solver)两个角色,提问者生成与给定主题相关的问题,解答者旨在解决问题。
网友们神评,“简直是带有RL的GAN”。
值得一提的是,此团队中又双叒叕现华人身影~
通过强化学习最大化期望奖励
当前大语言模型的训练很大程度上仍依赖人工整理数据集,堪称费时费力。
为了减轻这一负担,研究人员开发了用于强化学习的无监督奖励函数。然而,这些函数仍然依赖于预先提供的高质量输入提示。
因此,问题的难点从“生成答案”转移到了“生成高质量问题”。
这凸显出当前方法的一个关键不足:
缺乏一种可扩展且自我维持的流程,能够在无人干预的情况下自动生成有意义的问题和答案。
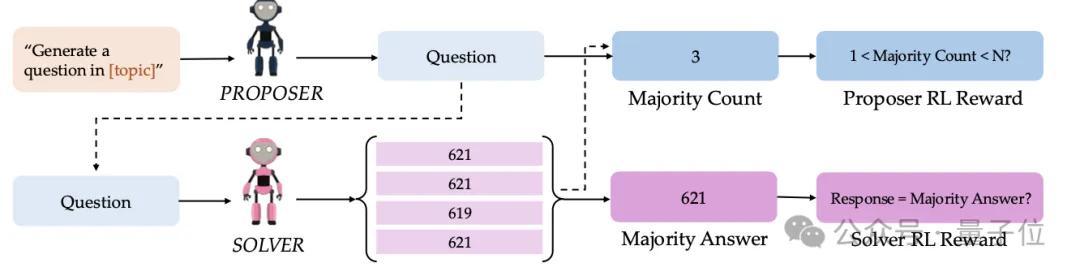
为此,研究者提出了SQLM框架
,一种非对称的自我博弈框架,其中提问者
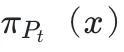
,解答者

回答该问题,两者均通过强化学习进行训练,以最大化期望奖励。
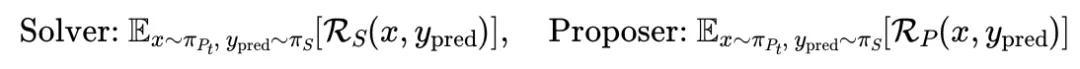
其中,提问者生成问题会对解答者形成条件影响,而解答者的表现又反过来为提问者提供奖励,从而不断优化提问者。
由于缺乏真实答案,研究者设计了基于“生成者–验证者差距”的自监督奖励函数。
若生成器-验证器差距小(例如算数问题),则采用多数投票作为代理奖励。
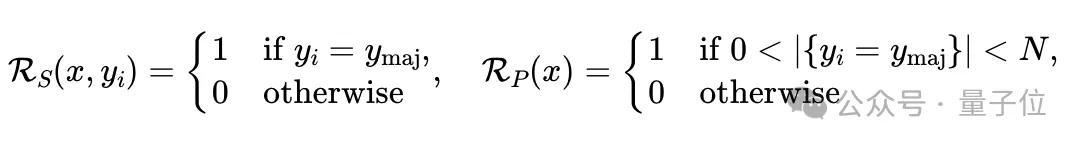
若生成器-验证器差距大(例如编程问题),先由提问者生成测试用例,奖励则基于通过测试的比例。
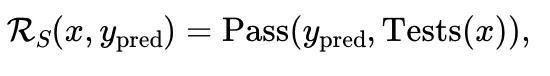
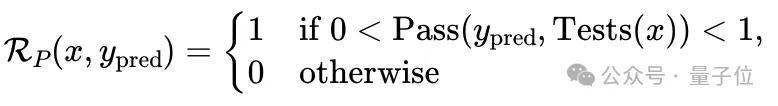
这种极小极大式的训练框架通过自博弈实现了稳定训练,并使奖励机制能够针对具体问题进行自适应调整。
为了评估模型的不同能力,研究者进行了三部分任务,并使用Qwen2.5-3B-Instruct运行实验。
算术任务
研究人员让提问者生成一个三位数的算数问题,并将其作为解答器的输入。他们按照TinyZero的设置,构建了一组包含4096个三位数乘法问题的测试集。
代数任务
研究者让模型生成最多包含两个变量的线性方程,并在OMEGA基准中的100道线性方程测试题上进行评估。
编程问题
他们让模型生成类似LeetCode中简单题的问题,输入为整数列表,输出为单个整数或另一个列表,并在Codeforces测试集的一个子集上进行评估。

实验结果显示,SQLM将Qwen2.5-3B-Instruct在算术任务上的准确率提高了14%,在代数任务上提高了16%;在编程任务上的准确率提高了7%。
此外,上表还显示出SQLM显著优于格式奖励基线(用于稳定训练和规范输出格式的参考值),表明推理能力的真正提升。
团队介绍

Lili Chen,本科毕业于加州大学伯克利分校,现博士就读于卡内基梅隆大学。

Katerina Fragkiadaki,卡内基梅隆大学机器学习系计算机科学副教授,博士毕业于宾夕法尼亚大,曾在加州大学伯克利分校担任博士后研究员,并于谷歌研究院工作。

Hao Liu,博士毕业于加州大学伯克利分校,曾任谷歌DeepMind研究员,即将出任卡内基梅隆大学机器学习系的助理教授。

Deepak Pathak,Skild AI创始人,本科就读于印度理工学院坎普尔分校,博士毕业于加州大学伯克利分校,曾在Meta担任了一年的研究员,现任卡内基梅隆大学计算机科学学院的助理教授。
参考链接:
[1]https://x.com/iScienceLuvr/status/1953052817012474353
[2]https://arxiv.org/abs/2508.03682
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态






