今日,智谱AI正式推出并开源全球首个100B级开源视觉推理模型GLM-4.5V(总参数106B,激活参数12B)。
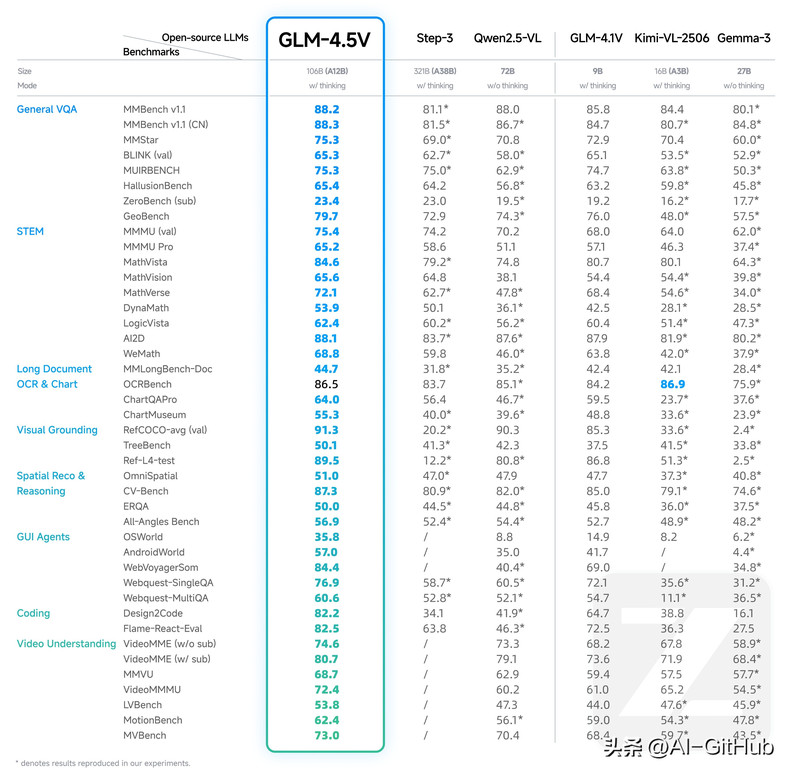
作为多模态通用人工智能(AGI)的核心突破,该模型在41个公开视觉多模态榜单中综合性能达到同级别开源模型SOTA,覆盖图像、视频、文档解析及GUI Agent等全场景任务,同步开源于魔搭社区、Hugging Face及GitHub。
全场景视觉推理
图像推理:场景理解、复杂多图分析、位置识别
视频理解:长视频分镜分析、事件识别

GUI 任务:屏幕读取、图标识别、桌面操作辅助
复杂图表与长文档解析:研报分析、信息提取
Grounding 能力:精准定位视觉元素
案例演示
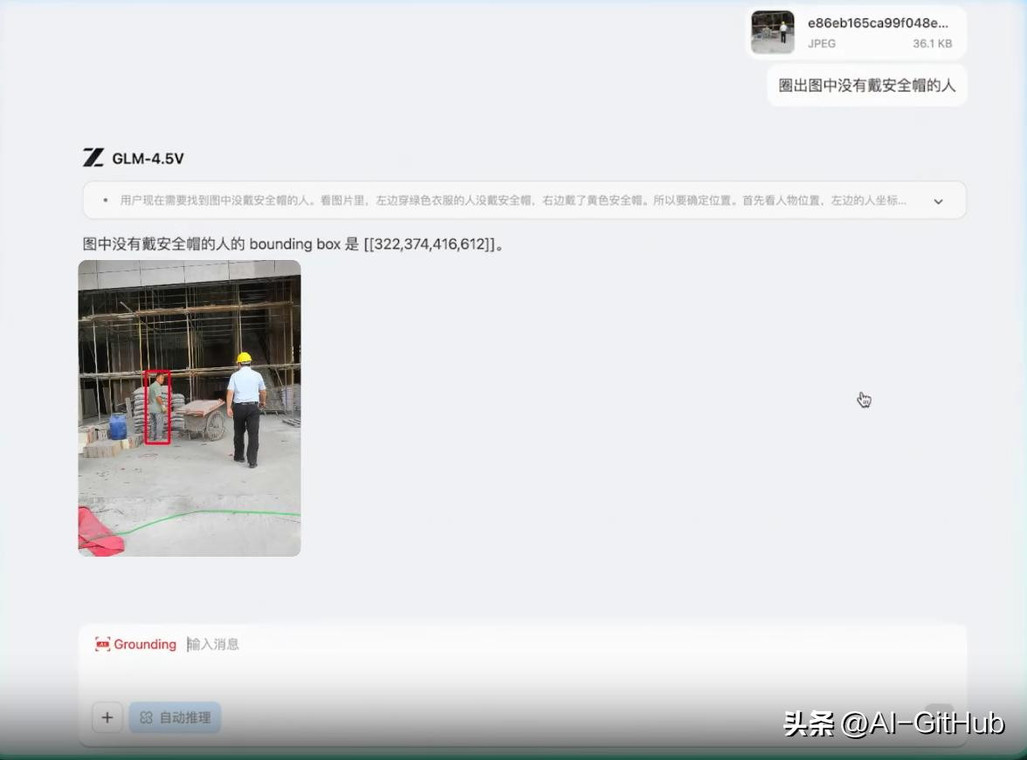
视觉定位:GLM-4.5V 能够根据用户提问,精准识别、分析、定位目标物体并输出其坐标框。该能力在现实世界拥有广阔的应用场景,例如安全与质量检查、高空遥感监测分析。
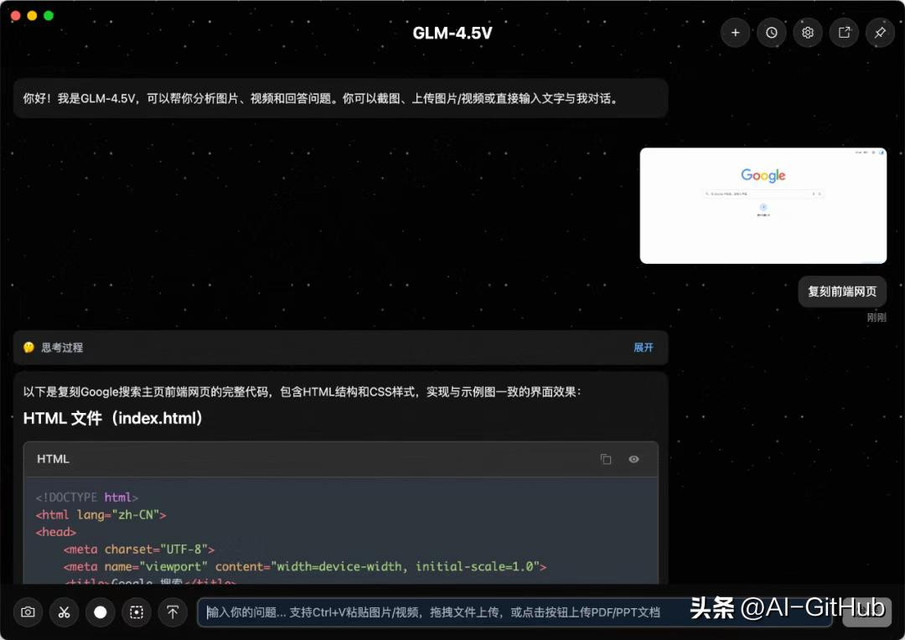
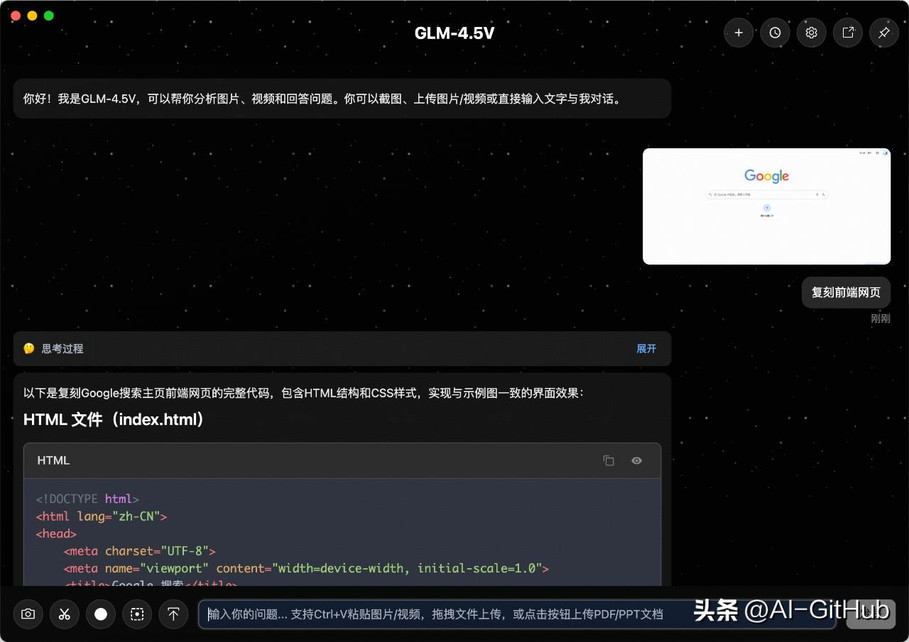
前端复刻:GLM-4.5V具备强大的推理与代码生成能力,能够对上传的网页截图进行分析,并将其转化为结构化的网页代码。
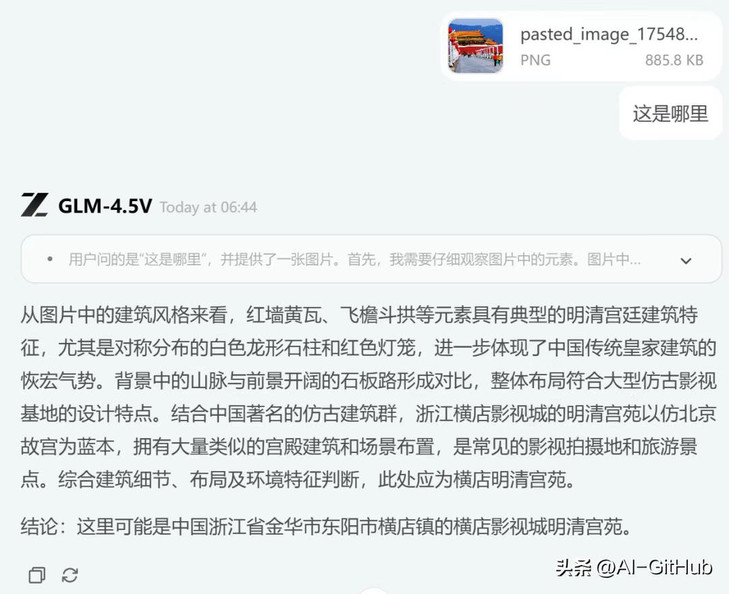
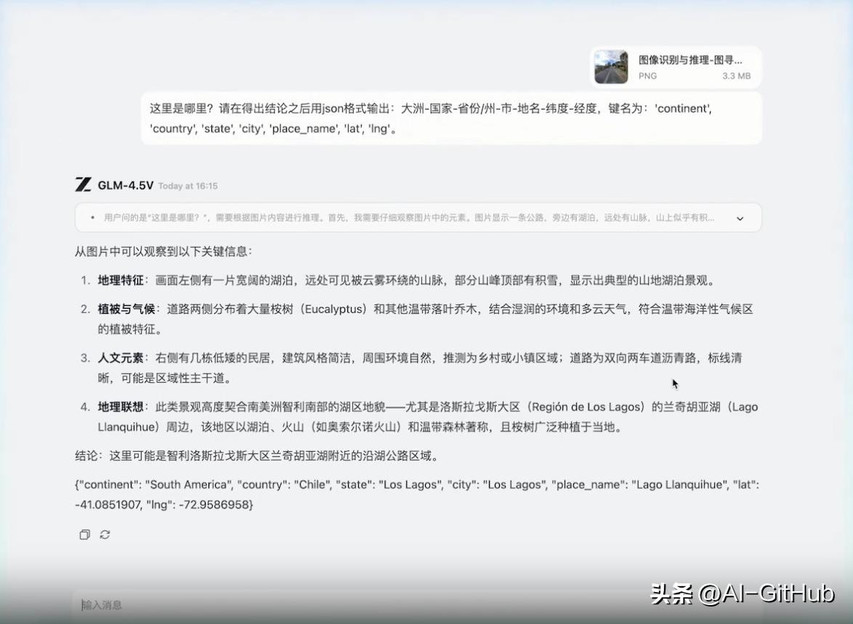
图像识别与推理:GLM-4.5V具备强大的感知与推理能力。一个典型应用是:在不依赖搜索工具的情况下,模型能通过图像中的细微线索推理出背景信息。
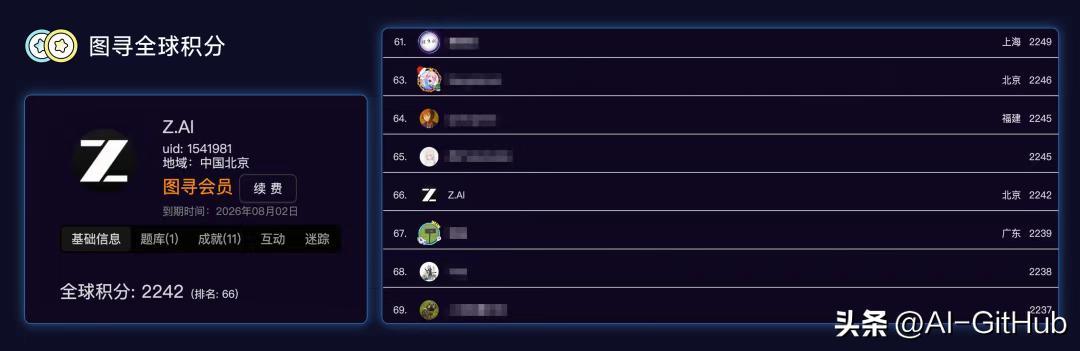
为验证视觉定位能力,GLM-4.5V参与全球图寻积分赛,与两万多名顶尖玩家同台竞技,通过分析街景图片在限定时间内推测拍摄地经纬度,最终以超越99%人类玩家的成绩登顶全球榜单。
参赛16小时:GLM-4.5V击败99%的人类玩家
参赛7天:模型攀升至全球第66名
这一结果充分证明了GLM-4.5V在复杂视觉推理任务中的卓越表现。
复杂文档深度解读:GLM-4.5V可以阅读长达数十页、含有大量图表的复杂长文本,能够对文本进行总结、翻译、图表提取等操作;此外,还能在给定信息的基础上输出自己的"观点"。

强大的 GUI Agent 能力:GLM-4.5V 能够识别和处理电子屏幕画面,在 GUI 环境中进行对话问答、图标定位等任务。
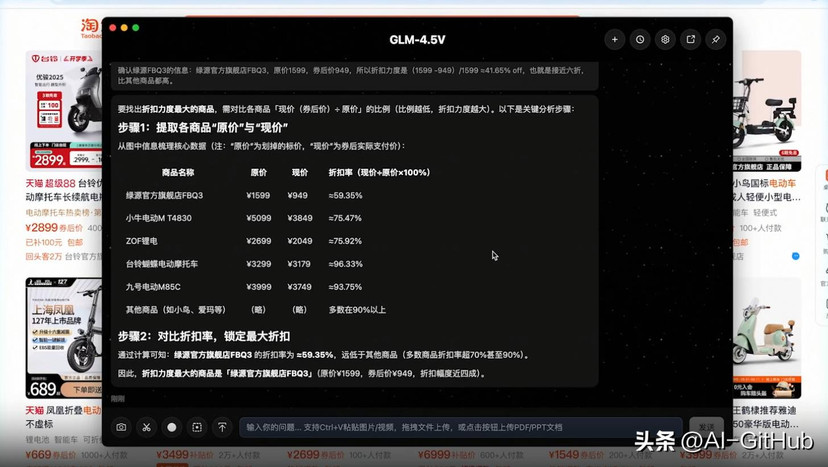
GLM-4.5V不仅展现出强悍性能,更以"快而有趣"为核心亮点,多项任务实现秒级响应。
通过上述案例已直观印证其完全跻身视觉推理领域的全球第一梯队。
在线体验:前往 z.ai,选择 GLM-4.5V 模型,上传图片或视频,即刻体验
Github :https://github.com/zai-org/GLM-V







