阿里通义大模型团队今日宣布全面开源千亿参数级别的多模态大模型Qwen3-VL-235B-A22B!
它拥有一双火眼金睛,识物能力堪称全能。无论是特色美食、奇珍动植物,还是各类汽车品牌、动漫角色都能轻松识别。你只需上传一张图片,它不仅能精准识别出图中的菜品名称,还能像专家一样用定位框给你圈出来!

功能特点
1.视觉Agent
Qwen3-VL 不仅能看懂图片,还能像人一样操作手机和电脑,自动完成许多日常任务。例如打开应用、点击按钮、填写信息等,实现智能化的交互与自动化操作。
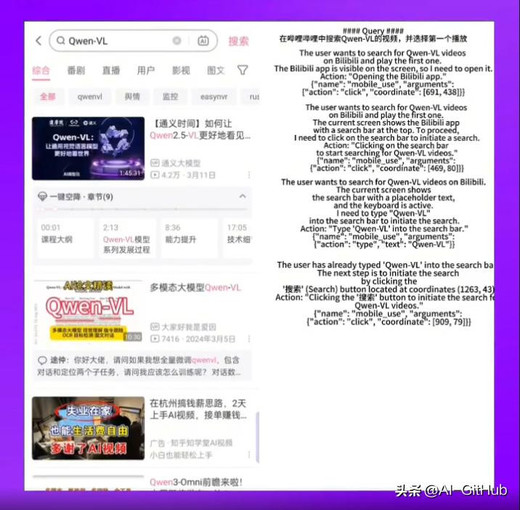
2.带图推理
Qwen3-VL 可以像人类一样仔细观察图像的局部细节,并结合工具进行复杂推理。比如通过路边的路牌判断具体位置,或根据人物照片搜索相关信息,完成细粒度识别和逻辑分析任务。
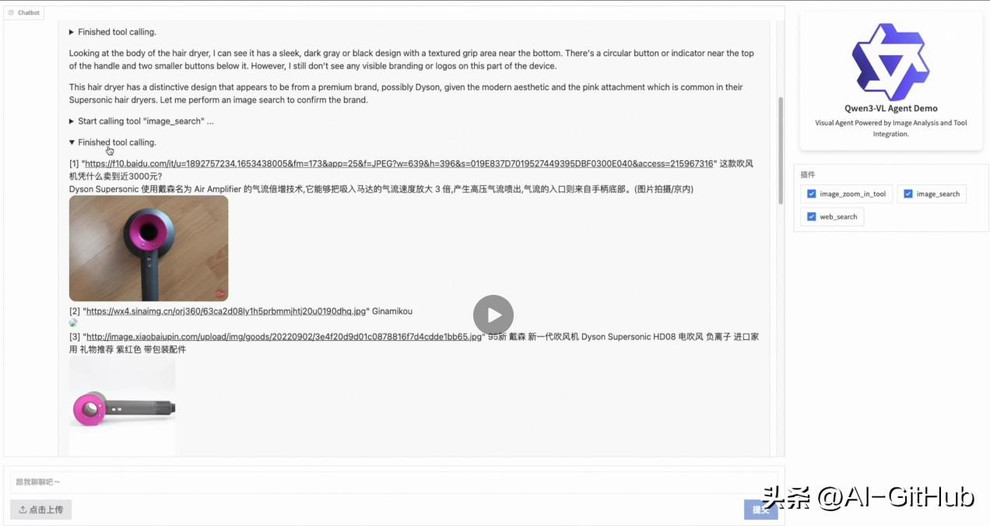
3.代码编程
结合视觉理解和代码生成能力,Qwen3-VL 在前端开发方面展现出强大潜力。例如,能把手绘草图转成网页代码,或帮助调试界面问题,提升开发效率。
4.空间理解
Qwen3-VL 能通过图像和视频理解空间关系,判断方向、动作状态,并做出合理规划。这种能力为机器人导航、自动驾驶等需要空间感知的应用打下基础。
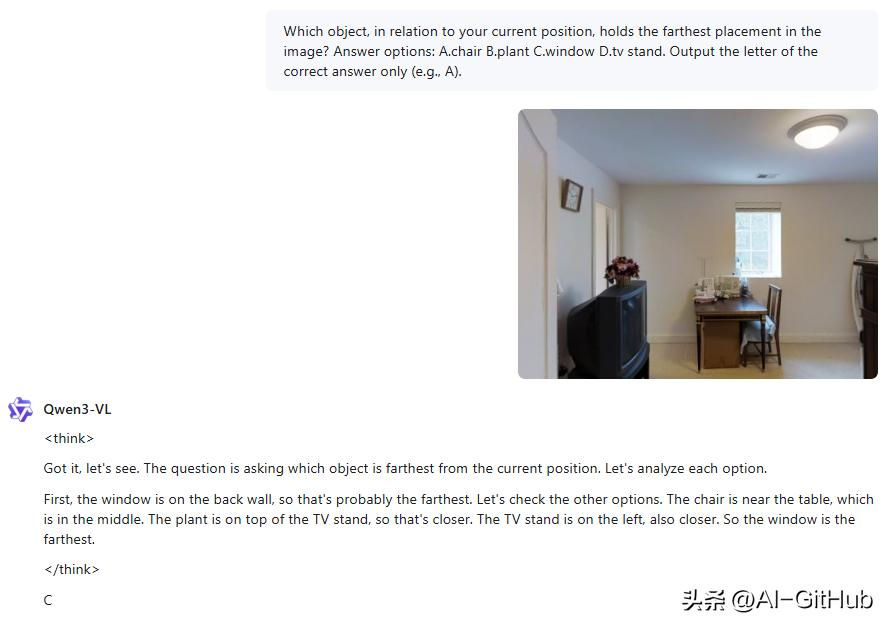
5.2D/3D 定位能力
在物体定位方面,Qwen3-VL 表现更强,能在包含多个物体的复杂场景中准确定位,最多可输出上百个检测框。2D grounding 的坐标表示从绝对坐标变为相对坐标。同时支持直接预测3D边界框,还原物体在真实世界中的位置和大小。


6.万物识别
丰富的视觉知识是理解现实世界的基础。Qwen3-VL 能够准确识别名人、美食、动植物、汽车品牌、动漫角色等,可在日常生活、社交分享、教育等多种场景中提供实用帮助。

7.创意写作
Qwen3-VL 的写作能力进一步提升,能根据图片或视频内容生成生动的文字描述,适用于故事创作、文案撰写、短视频脚本等创意场景。

8.STEM 多学科问题解答
Qwen3-VL 在数学、物理、化学等学科问题上的解题能力显著增强。它能理解题目含义,逐步推理并反复验证,有效解决各类学习和实际中的科学问题。


9.复杂指令遵循
Qwen3-VL 对复杂文本指令的理解能力更强,即使面对多步骤、条件判断或结构复杂的请求,也能准确理解并执行,确保任务顺利完成。
10.复杂文档理解与通用解析
Qwen3-VL 提升了对长文档和多页文件的理解能力,无论是超宽网页还是几十页的 PDF 图片都能清晰识别。此外,除了支持 HTML 格式解析外,还新增了 QwenVL Markdown 格式,用更少的数据量保留文字、公式、表格和插图的位置信息,提升处理效率。

11.多语言 OCR 与问答
Qwen3-VL支持的OCR语言从10种扩展到32种,涵盖希腊语、希伯来语、印地语、泰语、罗马尼亚语等多种语言,更好地满足不同国家和地区的需求。同时也支持多语言图文问答,方便跨语言交流。

12.多图对话与多轮对话
Qwen3-VL 增强了对多张图片的理解能力,能比较差异、发现关联。在多轮对话中也表现更好,能记住上下文,持续深入讨论多个图像的内容。

12.视频理解
Qwen3-VL 具备更强的视频理解能力,尤其在事件时间定位和长视频理解方面表现出色。它可以按时间点详细描述视频内容,即使是一个半小时的视频,也能准确回答问题。

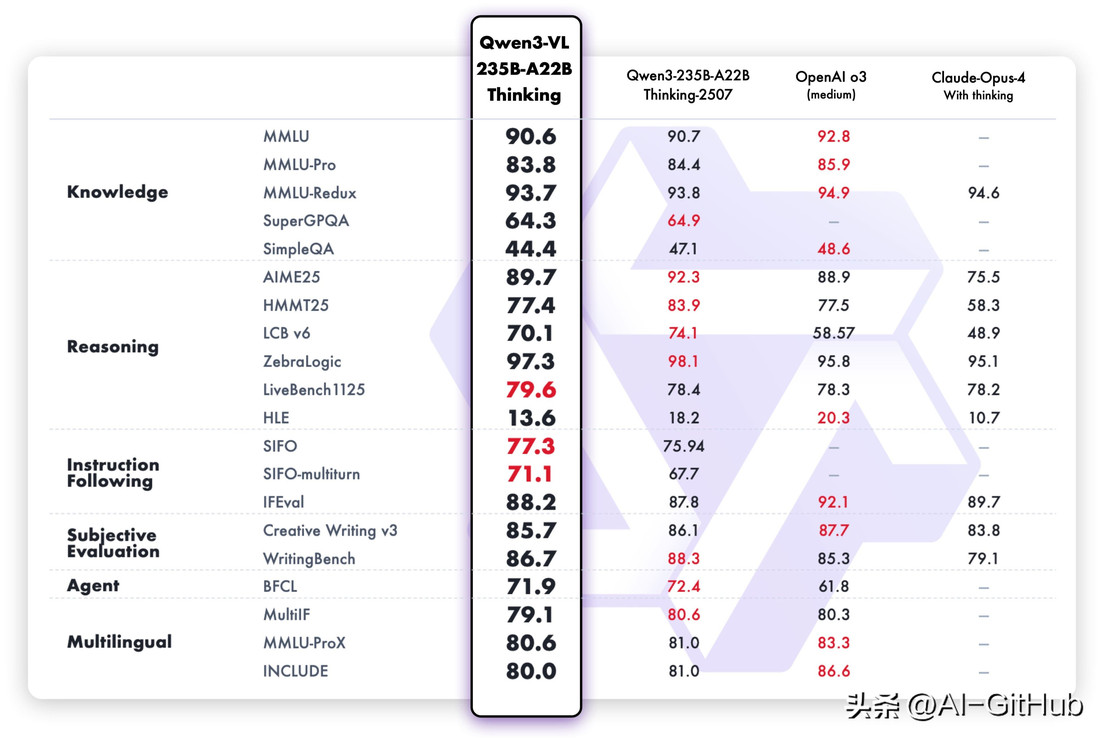
性能表现
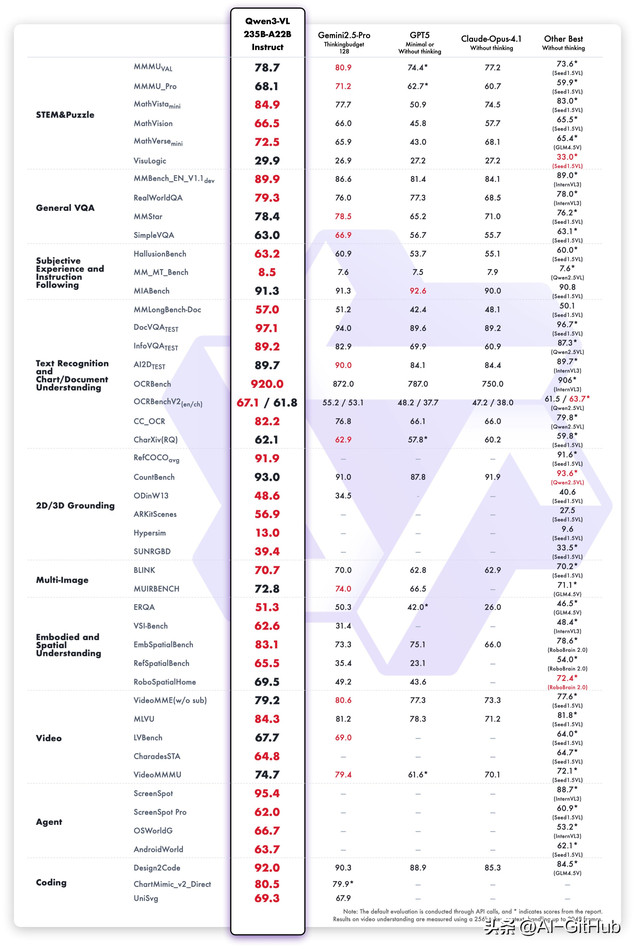
在十个维度的全面评估中,
Qwen3-VL-235B-A22B-Instruct在非推理类模型中的多数指标表现最优,超越了Gemini 2.5 Pro和GPT-5等闭源模型。
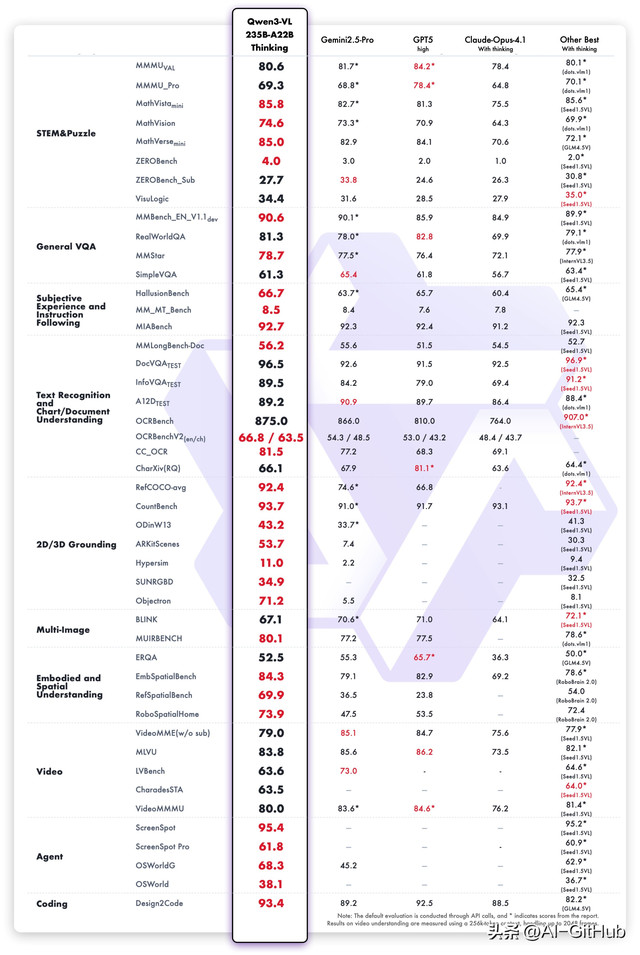
在推理模型方面,
Qwen3-VL-235B-A22B-Thinking 同样在多数指标上创下开源多模态模型的新高,与 Gemini 2.5 Pro 和 GPT-5 等闭源顶尖模型相比各有胜负。尤其在 Mathvision 这类复杂的多模态数学题目上,其表现甚至优于 Gemini 2.5 Pro。
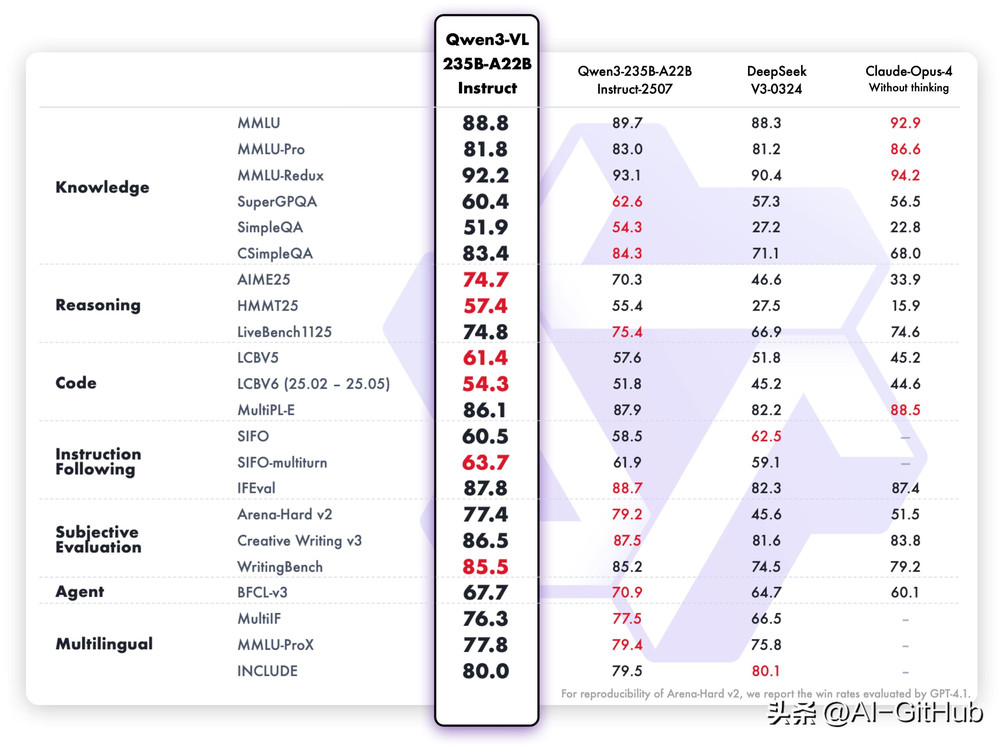
在纯文本任务上,无论是Qwen3-VL-235B-A22B的Instruct和Thinking都表现出强大的性能,与Qwen3-235B-A22B-2507的纯文本模型不相上下。
目前模型已在Github、Hugging Face、魔搭等平台开源,用户也可在Qwen Chat直接体验。
体验地址:https://chat.qwen.ai
Github开源地址
:https://github.com/QwenLM/Qwen3-VL







