
机器之心报道
编辑:杜伟、冷猫
计算机视觉领域的大部分下游任务都是从二维图像理解(特征提取)开始的。
在特征提取、语义理解、图像分割等 CV 基本任务中的模型三幻神分别是 SAM、CLIP 和 DINO,分别代表了全监督、弱监督和自监督三大数据训练范式。
在人工智能领域,自监督学习(SSL)代表了 AI 模型无需人工监督即可自主学习,它已成为现代机器学习中的主流范式。自监督学习推动了大语言模型的崛起,通过在海量文本语料上的预训练,获得了通用表示能力。
相比于需要标注数据的 SAM 模型和依赖图像 - 文本对进行训练的 CLIP 模型,基于自监督学习的 DINO 具备有直接从图像本身生成学习信号的优势,数据准备门槛更低,更容易实现更大规模的数据学习以达到更精细的图像特征,泛化性更强。
2021 年,Meta 发布 DINO,它基于 ViT 构建,在无需标注的情况下可以学习到语义分割、对象检测等任务中高可用的特征,填补了 SAM 模型在计算机视觉下游任务的空白。
2023 年,DINOv2 发布并开源,是 DINO 模型的改进版本。它采用了更大规模的数据,强调训练稳定性和通用性,支持线性分类、深度估计、图像检索等下游任务,效果逼近或超越弱监督方法。
DINOv2 不仅被 Meta 用作 ImageBind 等多模态模型的视觉表征基础,也在各类视觉相关研究工作中作为经典模型广泛使用。
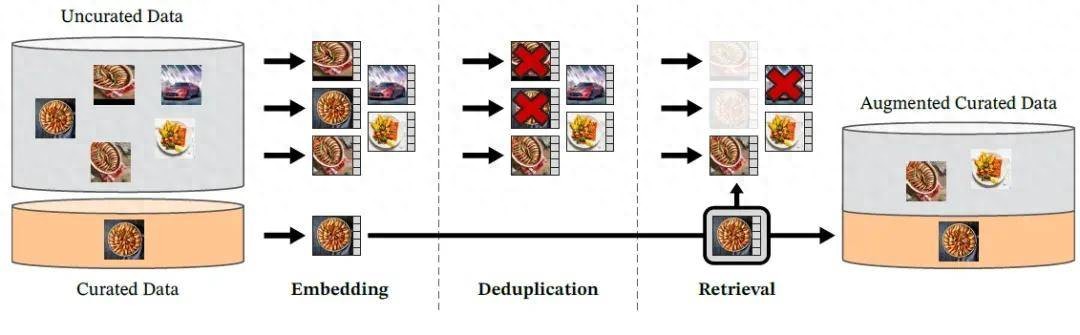
DINOv2 数据处理管线图
虽然 DINOv2 已经存在两年之久,它仍然是 CV 领域最优秀的前沿图像模型之一,具有完善可扩展的 ViT 结构,但遗憾就遗憾在训练数据量不够大,在高分辨率图像密集特征的任务中仍不够理想。
今天,DINOv2 的两大遗憾彻底被补足了。Meta 正式推出并开源了 DINOv3,一款通用的、SOTA 级的视觉基础模型,同样采用了自监督学习训练,能够生成更高质量的高分辨率视觉特征。
DINOv3 首次实现:一个单一的冻结视觉骨干网络在多个长期存在的密集预测任务(如目标检测和语义分割)中超越了专业解决方案。
DINOv3 取得突破性性能的核心在于其创新的自监督学习技术,这些技术彻底摆脱了对标注数据的依赖,大幅降低了训练所需的时间与资源,使得训练数据扩展至 17 亿张图像,模型参数规模扩展至 70 亿。这种无标签方法适用于标签稀缺、标注成本高昂甚至不可能获取标注的应用场景。

从 DINO、DINO v2 到 DINOv3。
Meta 表示,其正以商业许可方式开源 DINOv3 的一整套骨干网络,其中包括基于 MAXAR 卫星图像训练的卫星图像骨干网络。同时,Meta 还开放了部分下游任务的评估头(task head),以便社区复现其结果并在此基础上拓展研究。此外还提供了示例笔记本,帮助开发者快速上手,立即开始构建基于 DINOv3 的应用。
对于 Meta 此次的新模型,网友调侃道,「我还以为 Meta 已经不行了,终于又搞出了点新东西。」

自监督学习模型的全新里程碑
DINOv3 实现了一个新的里程碑:首次证明自监督学习(SSL)模型在广泛任务上能够超越弱监督模型。尽管前代 DINO 模型已在语义分割、单目深度估计等密集预测任务中取得显著领先,DINOv3 的表现更胜一筹。
DINOv3 在多个图像分类基准上达到了与最新强大模型(如 SigLIP 2 和 Perception Encoder)相当或更优的性能,同时在密集预测任务中显著扩大了性能差距。
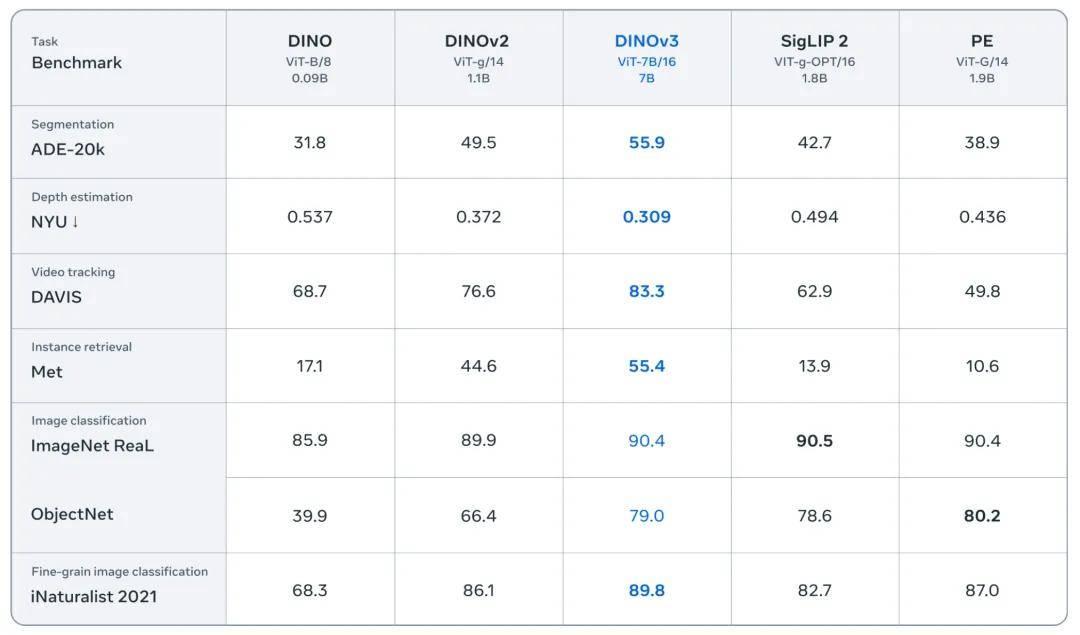
DINOv3 基于突破性的 DINO 算法构建而成,无需任何元数据输入,所需训练计算量仅为以往方法的一小部分,却依然能够产出表现卓越的视觉基础模型。
DINOv3 中引入的一系列新改进,包括全新的 Gram Anchoring 策略,有效缓解了密集特征的坍缩问题,相比 DINOv2 拥有更出色、更加干净的高分辨率密集特征图;引入了旋转位置编码 RoPE,避免了固定位置编码的限制,能够天然适应不同分辨率的输入等。
这些新的改进使其在多个高竞争性的下游任务中(如目标检测)取得了当前 SOTA 性能,即使在「冻结权重」这一严苛限制条件下也是如此。这意味着研究人员和开发者无需对模型进行针对性的微调,从而大大提高了模型在更广泛场景中的可用性和应用效率。
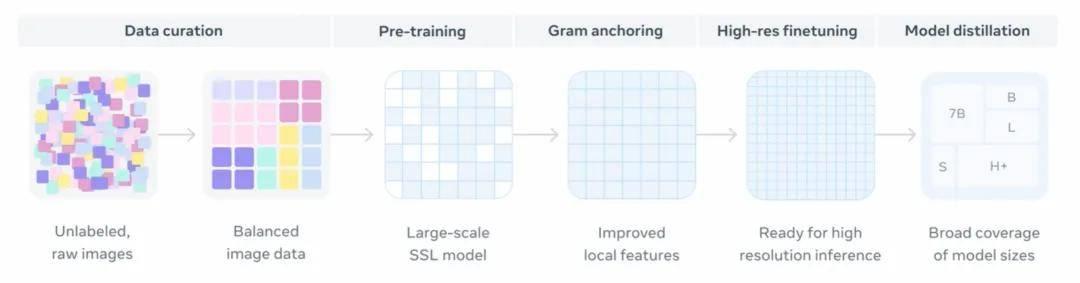
从数据整理(无标签原始图像、平衡的图像数据)、预训练(大规模自监督学习模型)、Gram Anchoring(改进的局部特征)、高分辨率微调(适用于高分辨率推理)和模型蒸馏(涵盖多种模型规模)。
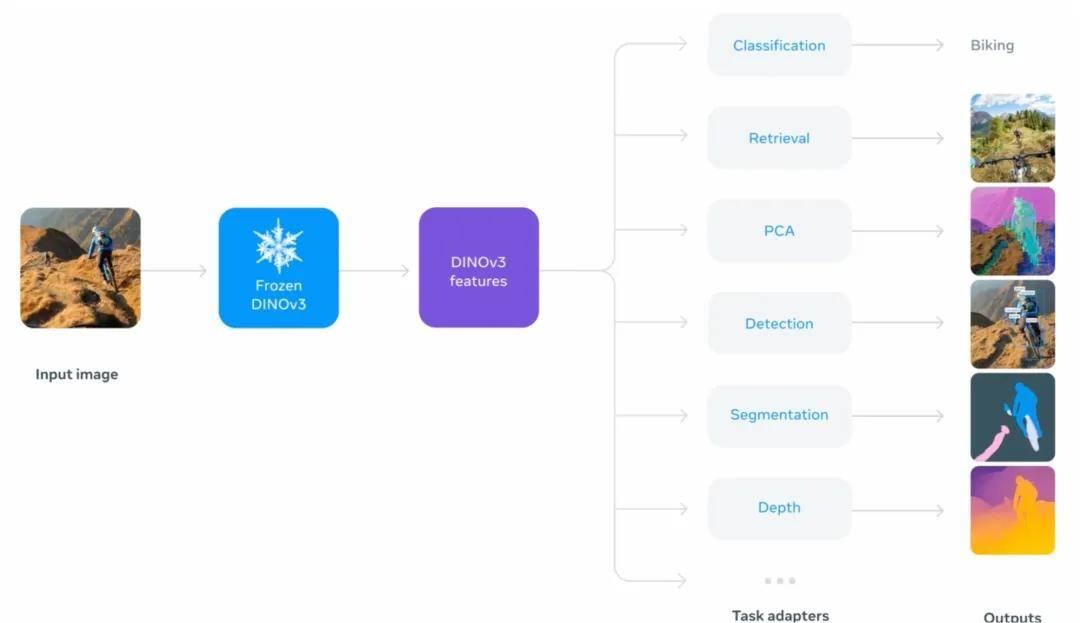
DINOv3 作为通用视觉特征提取器的工作流程,以及它在不同下游任务中的应用方式。
高分辨率、密集特征与高精度
DINOv3 的一大亮点,是相比于已有模型在高分辨率图像以及密集图像特征上的进步,显著改善了 DINOv2 时期的痛点。

比如说这张图,是一张分辨率为 4096×4096 的水果摊图像。要从这里找出某种特定的水果,就算是肉眼看都有点晕…
而 Meta 可视化了 DINOv3 输出特征所生成的 余弦相似度图,展示了图像中某个被红色叉标记的 patch 与所有其他 patch 之间的相似度关系。
放大看看,是不是还挺准确的?
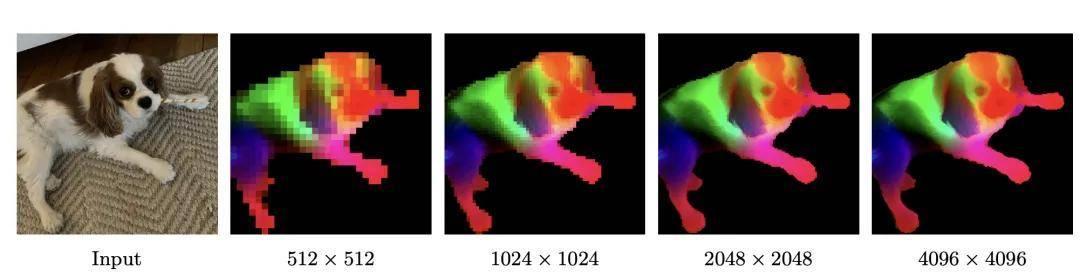
关于密集特征部分,Meta 通过以下方式可视化 DINOv3 的密集特征:对其特征空间执行主成分分析(PCA),然后将前三个主成分映射为 RGB 颜色通道。为使 PCA 聚焦于主体区域,Meta 对特征图进行了背景剔除处理。
随着图像分辨率的提升,DINOv3 能够生成清晰锐利且语义一致的特征图。
Meta 称,尽管自监督学习出现较晚,但其发展迅速,如今已追赶上近年来 ImageNet 上的精度上限。
可扩展、高效且无需微调
DINOv3 是在其前代 DINOv2 的基础上构建的,模型规模扩大了 7 倍,训练数据集扩大了 12 倍。为展现模型的通用性,Meta 在 15 个不同的视觉任务和超过 60 个基准测试上进行了评估。DINOv3 的视觉骨干模型在所有密集预测任务中表现尤为出色,展现出对场景布局与物理结构的深刻理解能力。
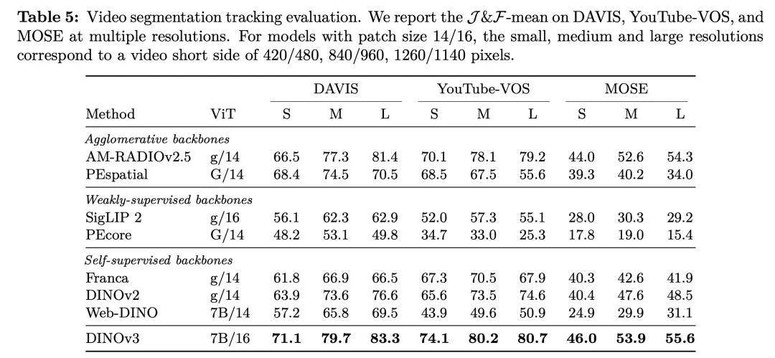
视频目标分割与跟踪评估结果

分割与跟踪示例
模型输出的丰富密集特征,能够捕捉图像中每一个像素的可量化属性或特征,并以浮点数向量的形式表示。这些特征能够将物体解析为更细粒度的组成部分,甚至能在不同实例和类别间进行泛化。
凭借这种强大的密集表示能力,Meta 可以在 DINOv3 上方仅用极少的标注训练轻量化的适配器 —— 只需少量标注和一个线性模型,就能获得稳健的密集预测结果。
进一步地,结合更复杂的解码器,Meta 展示了:无需对骨干网络进行微调,也能在长期存在的核心视觉任务上取得最先进的性能,包括目标检测、语义分割和相对深度估计。
由于在无需微调骨干网络的前提下也能实现 SOTA(最先进)性能,单次前向传播就可以同时服务多个任务,从而显著降低推理成本。这一点对边缘应用场景尤为关键,这些场景往往需要同时执行多项视觉预测任务。
易于部署的系列模型
将 DINOv3 扩展至 70 亿参数规模,展现了自监督学习(SSL)的全部潜力。然而,对于许多下游应用而言,70 亿参数的模型并不现实。基于社区反馈,Meta 构建了一个涵盖不同推理计算需求的模型家族,以便支持研究人员和开发者在各种使用场景中进行部署。
通过将 ViT-7B 模型进行蒸馏,Meta 得到了一系列更小但性能依旧出色的模型变体,如 ViT-B 和 ViT-L,使得 DINOv3 在多个评估任务中全面超越了同类的基于 CLIP 的模型。
此外,Meta 还推出了一系列蒸馏自 ViT-7B 的 ConvNeXt 架构模型(T、S、B、L 版本),它们能够满足不同的计算资源约束需求。与此同时,Meta 也将完整的蒸馏流程管线开源,以便社区在此基础上进一步开发与创新。
Meta「改变世界」的尝试
Meta 称,DINOv2 已经通过利用大量未标注数据,为组织在组织病理学、内窥镜检查和医学影像等领域的诊断和研究工作提供支持。
在卫星与航空影像领域,数据体量庞大且结构复杂,人工标注几乎不可行。借助 DINOv3,Meta 使这些高价值数据集能够用于训练统一的视觉骨干模型,进而可广泛应用于环境监测、城市规划和灾害响应等领域。
DINOv3 的通用性与高效性使其成为此类部署的理想选择 —— 正如 NASA 喷气推进实验室(JPL)所展示的那样,其已经在使用 DINOv2 构建火星探索机器人,实现多个视觉任务的轻量执行。
DINOv3 已经开始在现实世界中产生实际影响。世界资源研究所(WRI)正在使用 DINOv3 分析卫星图像,检测森林损失和土地利用变化。DINOv3 带来的精度提升使其能够自动化气候金融支付流程,通过更精确地验证修复成果来降低交易成本、加速资金发放,特别是支持小型本地组织。
例如,与 DINOv2 相比,DINOv3 在使用卫星与航空影像进行训练后,将肯尼亚某地区树冠高度测量的平均误差从 4.1 米降低至 1.2 米。这使得 WRI 能够更高效地扩大对数千名农户与自然保护项目的支持规模。
想要了解更多 DINOv3 细节的读者,请移步原论文。

- 论文地址:https://ai.meta.com/research/publications/dinov3/
- Hugging Face 地址:https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
- 博客地址:https://ai.meta.com/blog/dinov3-self-supervised-vision-model/






