阿里通义实验室今日重磅开源新一代视频生成模型通义万相Wan2.2。
首次将MoE架构引入视频生成领域,总参数量为27B,激活参数14B;

本次开源包括文生视频Wan2.2-T2V-A14B、图生视频Wan2.2-I2V-A14B和统一视频生成Wan2.2-IT2V-5B三款模型。
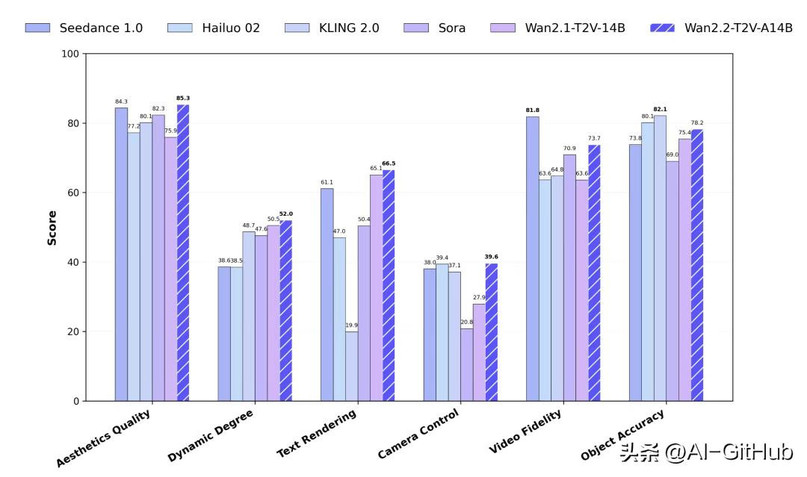
同时,首创电影美学控制系统,光影、色彩、构图、微表情等能力媲美专业电影水平。官方测试显示,通义万相Wan2.2在运动质量、画面质量等多项测试中超越了OpenAI Sora、快手Kling 2.0等领先的闭源商业模型。
功能特点:
文生视频(Text-to-Video):根据输入的文本描述生成相应的视频内容。
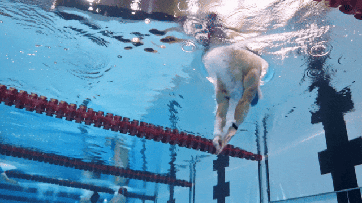
提示词:一名30岁出头的游泳运动员跃入水中,奋力比赛。镜头在水面和水下缓慢切换,捕捉着每一次划水时有节奏的水花。他穿着蓝色泳衣,戴着泳帽和护目镜,手臂有力地向前伸展,双腿快速踢动。水面波光粼粼,背景是其他选手和泳道线。镜头平稳跟随他的动作,展示他在水中流畅而有力的前进。
图生视频(Image-to-Video):根据输入的图片生成视频,模型根据图片内容生成动态场景,让图片“活”起来。并且在物理运动进行了优化:人物互动无穿模、沙发回弹等细节逼真!

统一视频生成(Text-Image-to-Video):结合文本和图片生成视频,同时用文本描述和图片信息,生成更精准的视频内容。

电影级美学控制:通过光影、色彩、构图、微表情等控制,生成具有专业电影质感的视频。用户通过输入相关关键词(如“暖色调”“中心构图”)定制视频的美学风格。

复杂运动生成:能生成复杂的运动场景和人物交互,提升视频的动态表现力和真实感。
技术原理:
混合专家(MoE)架构:引入MoE架构,将模型分为高噪声专家和低噪声专家。高噪声专家负责视频的整体布局,低噪声专家负责细节完善。在保持计算成本不变的情况下,大幅提升模型的参数量和生成质量。
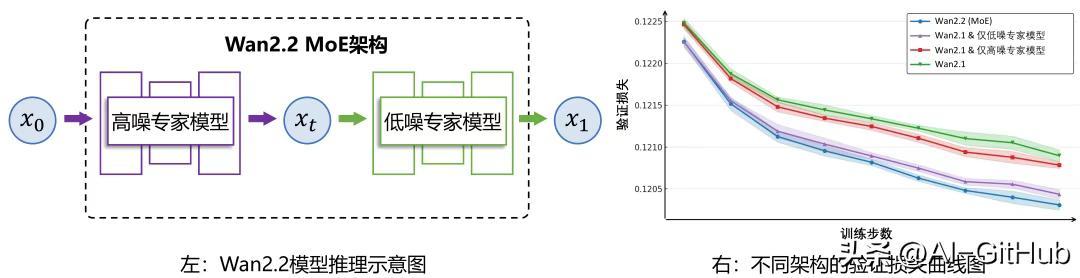
扩散模型(Diffusion Model):基于扩散模型作为基础架构,通过逐步去除噪声来生成高质量的视频内容。MoE架构与扩散模型结合,能进一步优化生成效果。

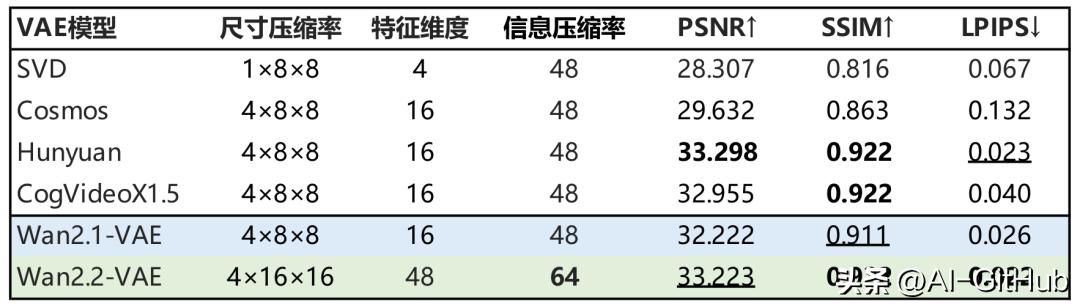
高压缩率3D VAE:为提高模型的效率,通义万相2.2基于高压缩率的3D变分自编码器(VAE)。架构实现了时间、空间的高压缩比,让模型能在消费级显卡上快速生成高清视频。
大规模数据训练:模型在大规模数据集上进行训练,包括更多的图像和视频数据,提升模型在多种场景下的泛化能力和生成质量。
该模型已在GitHub、魔搭社区开放下载,此次开源进一步巩固阿里通义生态优势,Qwen系列累计下载量突破4亿次,衍生模型达14万。
官网体验:https://wan.video/welcome
GitHub:https://github.com/Wan-Video/Wan2.2







