尽管大型语言模型(LLM)拥有广泛的世界知识和强大的推理能力,被广泛视为优秀的少样本学习者,但在处理需要大量示例的上下文学习(ICL)时仍存在明显局限。
已有工作表明,即使提供多达上百甚至上千条示例,LLM 仍难以从中有效学习规律,其表现往往很快进入平台期,甚至对示例的顺序、标签偏差等较为敏感。在利用上下文学习解决新任务时,LLM 往往更依赖于自身的强先验以及示例的表面特征,而难以真正挖掘出示例中潜在的因果机制或统计依赖。
这项名为 MachineLearningLM 的新研究突破了这一瓶颈。该研究提出了一种轻量且可移植的「继续预训练」框架,无需下游微调即可直接通过上下文学习上千条示例,在金融、健康、生物信息、物理等等多个领域的二分类 / 多分类任务中的准确率显著超越基准模型(Qwen-2.5-7B-Instruct)以及最新发布的 GPT-5-mini。
相比于已有的用于表格数据的机器学习方法,MachineLearningLM 几乎完全保留了 LLM 通用能力,这意味着它可以无缝集成到更复杂的对话工作流中。


- 论文链接: https://arxiv.org/abs/2509.06806
- 模型和数据集:
- https://huggingface.co/MachineLearningLM
- 代码:
- https://github.com/HaoAreYuDong/MachineLearningLM
核心创新一:百万级合成任务「授人以渔」
研究团队旨在赋予 LLM 一种「举一反三」的元能力 —— 不依赖对真实任务数据的机械记忆,而是通过海量且多样化的合成任务,从根本上训练模型在大量上下文示例中挖掘规律并进行预测的能力。
传统的指令微调方法通常基于有限规模(约为千数量级)的真实任务数据,这在很大程度上限制了模型向新任务的泛化能力。与之相比,MachineLearningLM 构建了一个超过 300 万合成任务的大规模预训练语料库。
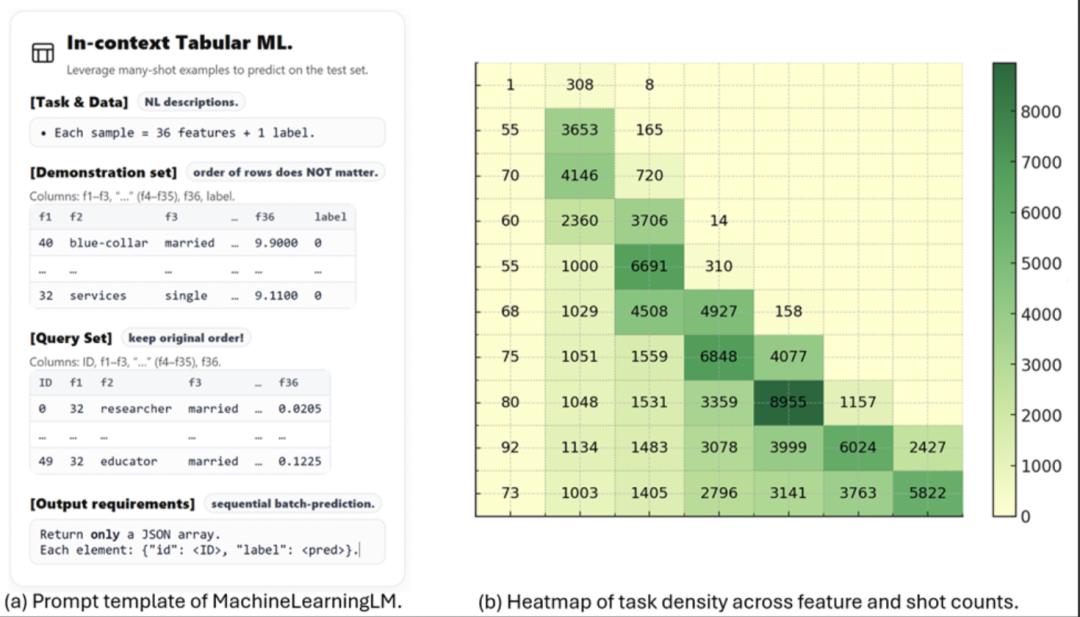
任务生成器基于结构因果模型(Structural Causal Model, SCM)来采样生成二分类及多分类任务。SCM 通过有向无环图(DAG)和结构方程(采用神经网络与树模型实现)明确定义变量间的因果关系,能够精确控制特征的边际分布、类型(如数值型或类别型)以及标签生成机制。
该方法确保预训练数据与下游真实评估集没有任何重叠,从而保证评估过程对模型泛化能力的检验具备充分公平性。同时,通过控制示例数量从数个到 1024 个不等,该机制能够专门训练模型处理「多示例」场景的推理能力。
核心创新二:随机森林模型「循循善诱」
在海量合成任务上直接训练大型语言模型(LLM)容易因任务质量不一致 —— 例如存在信号微弱或类别极度不平衡等情况 —— 而导致训练崩溃或陷入局部最优。为解决这一问题,本研究引入随机森林(Random Forest)模型,利用其强大且稳健的建模能力,设计了如下两级过滤机制:
- 样本级共识过滤(热身训练阶段):在热身训练中,为每个合成任务训练一个随机森林模型,并引导 LLM 学习模仿其预测行为。具体而言,仅保留随机森林预测结果与真实标签一致的那些样本用于 LLM 的训练。该方法通过提供清晰且高置信度的监督信号,使 LLM 初步建立起准确的上下文建模能力,尤其是数值建模能力,为后续过渡到自主上下文学习奠定基础。
- 任务级过滤(全程训练阶段):在整个训练过程中,除为每个任务构建随机森林模型外,还引入保守随机基线(如随机猜测或坍塌到多数类的预测方法),以剔除那些随机森林表现未显著优于基线的无效任务。评估指标包括机会校正一致性、失衡鲁棒准确率、宏平均准确率以及避免预测坍塌等指标。
为何选择随机森林?除了强大且稳健的建模能力,随机森林具有高度透明的决策过程,可分解为清晰的规则路径与特征重要性评估,这种可解释性与 LLM 的思维链(Chain-of-Thought, CoT)推理模式天然契合,有助于后续推进思维链预测及解释性预测任务。
同时,随机森林能够提供预测置信度,为进一步减少 LLM 幻觉问题引入置信度机制提供了可能。
核心创新三:高效上下文示例编码「多维扩容」
在大模型时代,如何高效地在上下文学习中处理海量表格数据,是一项重要挑战。传统的「自然语言描述」方式(例如:「收入是 29370,职业是博士,年增长率是 - 12.34% → 标签:1」),占用 token 多、计算开销大,严重限制了实际应用中可支持的示例数量;数值型特征经分词器处理时,一个小数可能被拆成多个 token,既浪费长度又可能导致数值比较错误,如模型容易误认为「1.11」(1|.|11)比「1.9」(1|.|9)大。
为此,作者提出了三项核心优化策略,显著提升了上下文学习的数据容纳能力与推理效率:
- 告别「小作文」,样本用表格来组织: SpreadsheetLLM 等研究已广泛证明,LLM 能很好地理解结构化表格,因此作者放弃相关工作将结构化数据展开成冗长自然语句的做法,转而采用紧凑的表格编码格式。

- 把数字「打包」成整数,告别 token 碎片化:先遵循机器学习工程的常见操作,将所有数值基于训练集数据分布逐列进行 z-score 标准化;然后将 z-norm 下 ±4.17(绝大多数情况)的浮点数区间整体线性映射到 [0, 999] 的整数区间。这样,每个数值在 GPT 和 LLaMA 3 的词表中仅需 1 个 token 表示(Qwen 分词器也仅需 1 到 3 个 token),既节省空间,还避免了小数点和正负号单独切词带来的数值理解错误。该流程只是改进了传统机器学习中的数值标准化,而没有改变 LLM 原生分词器,因此模型的数值推理能力可以全部继承。

- 推理也要「团购」:序列级批量预测——传统上下文学习一次只处理一个查询,在多样本学习时效率极低。作者将多个查询(如 50 条)拼成一条序列,统一前向推理,一次性输出所有预测结果。这不仅大幅提升推理速度,还能在训练阶段提高自回归稳定性。

惊艳效果:多项能力突破
MachineLearningLM 的继续预训练方案无需改变模型架构或分词器,只使用了 Qwen2.5-7B 基座模型和低秩适配(LoRA rank=8)这种轻量级配置,MachineLearningLM 展现出了前所未有的上下文样本利用能力:
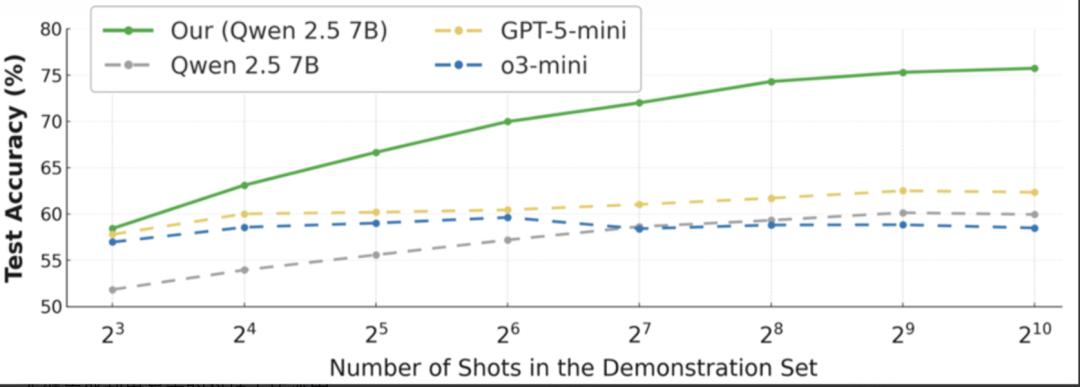
- 「千示例」上下文学习:模型性能随着提供的示例数量增加而持续稳定提升,从 8 条示例到 1024 条示例,准确率单调增长。这样的上下文样本效率是已有 LLM 都难以做到的。
- 远超 GPT-5-mini 等强大基准模型:在金融、生物信息、物理信号和医疗健康等领域的表格分类任务上,其纯上下文学习的准确率平均超越 GPT-5-mini 等强大基准模型约 13 到 16 个百分点。
- 在无需任何任务特定训练的情况下,其准确率已能达到与需要任务级参数更新的随机森林模型相差无几的水平(平均相对差距在 2% 以内),并显著优于 K 近邻(kNN)算法。
- 通用能力无损:最关键的是,注入 ML 能力后,模型原有的对话、知识和推理能力几乎完好无损。在 MMLU 基准测试中,其零样本准确率达 73.2%,50 样本设置下达 75.4%,与基准通用 LLM(Qwen-2.5-7B-Instruct)持平,甚至在特定领域(如统计和物理)有一定提升,这意味着它可以无缝集成到更复杂的对话工作流中。


- 实证研究表明,MachineLearningLM 能够同时处理数值特征与自然语言描述,无需像传统方法那样对文本进行分桶或转换为嵌入向量,实现了真正的异构(多模态)输入推理。然而,该模型仍存在一定局限,例如在面对非独立同分布的时间序列数据以及类别数量极其庞大的数据集时,性能尚有待提升,这也为后续研究指明了改进方向。
应用领域
基于大幅提升的多样本上下文学习和数值建模能力,MachineLearningLM 有望在金融、医疗健康与科学计算等广泛场景中扩展大型语言模型的实际应用边界。
未来展望
MachineLearningLM 为未来研究开辟了多个充满潜力的方向。以下是论文里列出的几个重点方向:
- 超越文本与数字:合成多模态分类任务,使 MachineLearningLM 能够直接在海量合成数据上练习处理异构信号的多模态上下文预测,这依然可以建立在表格预测的框架之上,例如利用 HTML 表格来嵌入图像。
- 通过系统优化突破上下文长度限制:例如采用张量 / 流水线并行、高效内存注意力与 KV 缓存等系统优化技术。
- 不确定性预测 (Uncertainty):预测的同时输出置信度(比如利用随机森林的置信度做热身训练),以减少模型 OpenAI 近期提出的由于缺乏承认不确定性(Honesty about uncertainty)引发的幻觉(Hallucination)。
- 提升可解释性 (Interpretability):叙事蒸馏与推理增强学习,既可以利用底层的 SCM(变量、关系与机制)作为预测任务的辅助目标,也可以从集成模型中蒸馏规则,形成紧凑、人类可读的推理链条。
- 集成检索增强方法(RAG):为 MachineLearningLM 集成一个检索模块,使其能在预训练和推理时动态注入最相关的示例。
- 赋能智能体(Agent):与 Agent 记忆机制(Memory)深度融合,提升其在复杂环境中利用多样本的上下文学习,赋予智能体强大的从大量经验记忆中挖掘和学习的能力。
作者介绍
本文作者:董浩宇(中国科学院大学)、张鹏昆(华南理工大学)、陆明哲(中国科学院大学)、沈言祯(斯坦福大学)、柯国霖(个人贡献者)

董浩宇:中国科学院大学在读博士(预计 2025 年底毕业)。研究方向涵盖表格与半结构化数据理解与推理、LLM 后训练与强化学习、数据集与评测基准等。曾提出 SpreadsheetLLM 并获得 Hugging Face Paper of the Day、联合发起并持续共同组织 NeurIPS 2022–2024 表格表征学习(TRL)系列研讨会,推动表格智能社区发展。