Anthropic重磅发布Claude Opus 4.1,引发技术圈震动。本篇文章将从模型能力、产品体验到行业影响,深度解析这场“核弹级”更新背后的技术逻辑与生态意义。

就在所有人的目光都聚焦在OpenAI何时发布GPT-5时,它的老对手Anthropic,悄无声息地投下了一颗“重磅炸弹”。
就在昨天,Anthropic毫无预兆地发布了其最新、最强的模型——Claude Opus 4.1。
这不是一次普通的更新,更像是一场精准的“外科手术式”打击。它没有追求大而全的功能,而是将所有火力都集中在了一个核心领域:高级编程与智能体(Agent)任务。
市场的反应很直接:Anthropic这是要抢在GPT-5发布前,提前锁定开发者和企业用户的心。那么,这个被誉为“程序员新宠”的Opus 4.1,究竟神在哪里?
Part 1 王牌指标:74.5% SWE-bench意味着什么?
抛开所有花哨的宣传,我们先看一张成绩单。
在衡量AI模型修复真实世界代码Bug能力的黄金标准——SWE-bench Verified测试中,Claude Opus 4.1取得了惊人的74.5%的得分,将包括GPT系列在内的所有对手甩在了身后。
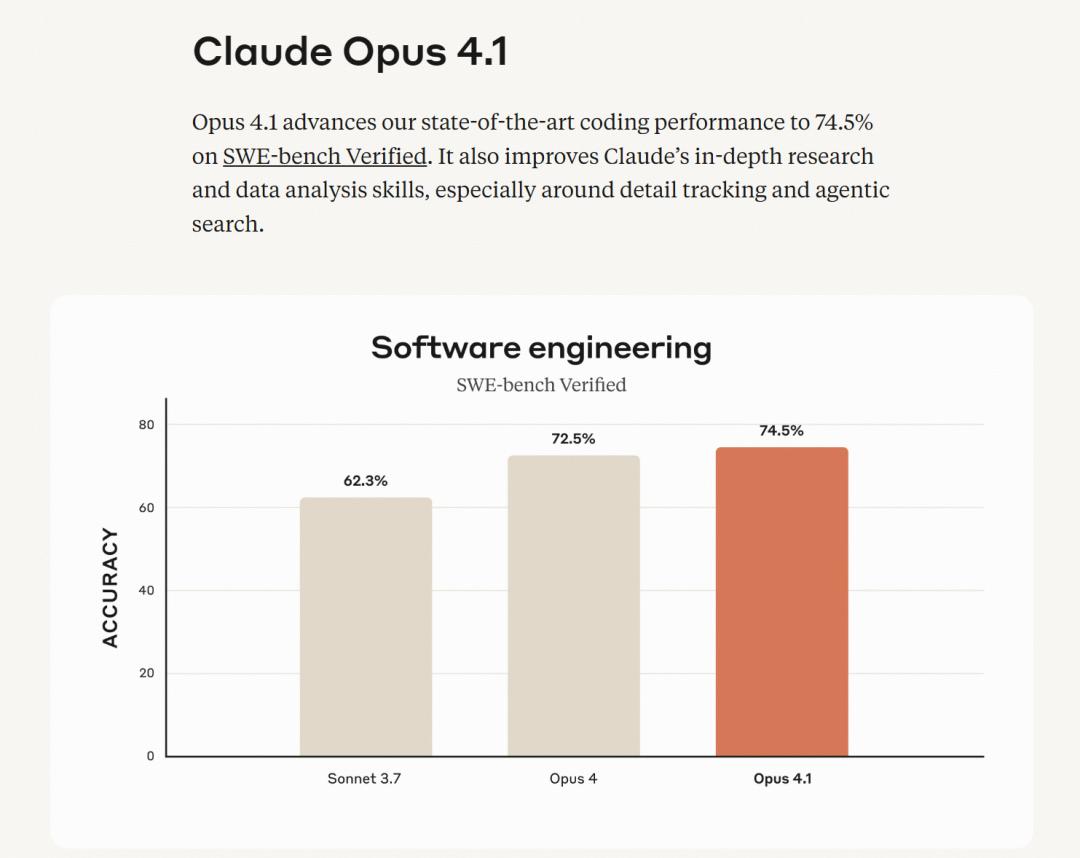
图注:Opus 4.1在SWE-bench上的得分,代表了它能成功解决74.5%从GitHub上真实拉取的编程问题。
这个74.5%到底有多恐怖?
简单来说,SWE-bench不是那种“纸上谈兵”的选择题,而是让AI直接下场,面对一个真实的、从开源社区(GitHub)拿来的、带有完整代码库的Bug,然后像一个真正的人类工程师一样去修复它。
这意味着Opus 4.1:
- 不仅仅是“写代码”,更能“读懂代码”,理解整个项目的上下文和工程师的意图。
- 犯错更少,在修复过程中,它能做出更少的非必要改动,直击问题核心。
- 更可靠,2%的绝对性能提升,在实际工程中意味着约7%的错误率降低,这是一个巨大的飞跃。
一句话总结:如果说以前的AI是“夸夸其谈”的理论学霸,Opus 4.1就是那个能直接下场解决问题的“金牌工程师”。
Part 2 揭秘黑科技:“扩展思考”与“虚拟协作者”
分数遥遥领先的背后,是Anthropic独特的技术路径。
1. 不只是编码,更是“思考”
这次更新最大的黑科技之一,叫做“扩展思考 (Extended Thinking)”。
当面对一个极其复杂的问题时(比如一个涉及多个步骤的高级数学题,或一个需要重构多个代码文件的庞大任务),Opus 4.1可以被指示调用一个高达64,000 Token的“草稿纸”或“思考空间”。它会先在这个空间里规划步骤、分析利弊、自我纠错,最后才给出那个精准、优雅的答案。
这让它在需要深度推理的GPQA(研究生水平物理问答)和AIME(美国数学邀请赛)等测试中也表现出色。
2. 你的“虚拟代码搭档”已上线
云服务巨头亚马逊AWS在其Bedrock平台上线Opus 4.1时,给出了一个极具吸引力的定位——“虚拟协作者 (Virtual Collaborator)”。
它能:
- 独立规划并执行端到端的复杂开发任务。
- 生成高质量的前端代码,并拥有“强大的视觉输出质量”。
- 在需要长时间、多步骤的“长时程任务”中保持稳定的推理能力。
来自开发者社区的一线反馈也证实了这一点。许多程序员在Reddit上表示,使用Anthropic自家的Claude Code工具调用Opus 4.1,体验远超通过GitHub Copilot等第三方工具。原因在于其出色的“上下文工程”,能更好地理解整个代码库,而不是孤立的文件。
Part 3 市场对决:价格、竞品与前景
那么,如此强大的模型,代价是什么?
1. “高端”的实力,“高昂”的价格
Opus 4.1的API定价与上一代持平:每百万输入Token为15美元,输出为75美元。这在当前市场上属于“相对高昂”的水平。
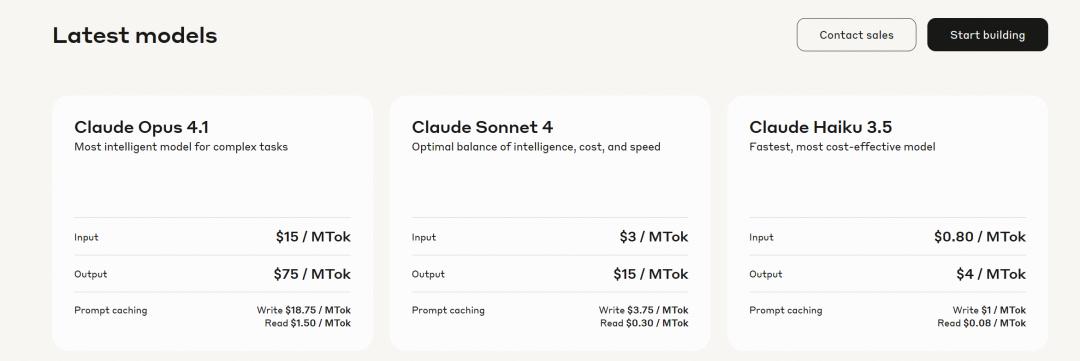
这清晰地表明了Anthropic的策略:Opus 4.1不是给所有人用的日常玩具,而是为专业开发者和企业打造的重型装备。
2. Anthropic的阳谋:GPT-5前的精准卡位
在GPT-5呼之欲出的当下,Opus 4.1的发布是一次教科书级的市场卡位。它用一个在特定领域(编程)的绝对优势,牢牢吸引住了最高价值的用户群体,建立了强大的护城河。
更吊人胃口的是,Anthropic在公告结尾处暗示:“未来几周,我们还将有更重大的模型改进。”这无疑是在告诉市场:好戏,才刚刚开始。
Part 4 谁最该用?以及如何上手?
如果你是以下几类人,Opus 4.1绝对值得你立刻尝试:
- 企业开发团队:需要AI深度参与代码审查、Bug修复和项目重构。
- AI工程师:正在构建需要自主规划和执行任务的复杂AI智能体(Agent)。
- 数据科学家:需要进行复杂的数据分析和可视化。
- 个人开发者:正在进行有挑战性的、复杂的个人项目。
如何上手?
- 官方API:直接通过Anthropic的API接入。
- 云平台:在AmazonBedrock和GoogleCloudVertexAI上已经全面可用。
- 第三方工具:在如GitHubCopilotEnterprise等工具中也可以选择使用。
结语:AI战争进入“专精”时代
Claude Opus 4.1的发布,标志着AI模型的竞争范式正在悄然改变。它不再是“谁的参数更多、更能聊天”的军备竞赛,而是“谁能在特定领域做得更专业、更可靠”的价值之战。
它或许不是一个能陪你吟诗作对的“全能网友”,但它绝对有可能成为你职业生涯中那个最可靠、最强大的“代码搭档”。
最后,留一个问题给大家:你认为Op-us 4.1能撼动GitHub Copilot的霸主地位吗?在专业编程领域,你更看好谁的未来?
欢迎在评论区留下你的真知灼见!
本文由 @像素呼吸 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Claude官网截图







