
3D生成的行业新标杆,这一次由国产玩家树立。
万万没想到,这样一个堪比游戏全景视角的场景,竟然只由一张图片生成?!
在360°自由环视下,由亭子一隅延伸出的画面始终保持内容一致:

面对更考验几何、色彩能力的场景,也能生成比较真实自然的3D世界。
仔细看,画面所呈现的几何关系(如位置、大小、形状)和遮挡关系基本挑不出毛病,不同区域的颜色也没有突兀的地方。

更神奇的是,我们还能随心所欲控制运动轨迹。
比如先让图片来个直行:

然后立马再来个蛇形走位,拐一个S弯:

甚至,对比李飞飞World Labs团队所采用的方法,新模型还支持更大范围的移动。
原图是酱婶儿的:

李飞飞World Labs团队让这张图的视角逐渐推进,最终生成结果如下:

而Matrix-3D新模型生成的场景明显更为丰富,全景视角下空间感也更为强烈。

不卖关子了,Matrix-3D正是国产玩家昆仑万维最新推出的3D世界生成框架。
作为一个融合全景视频生成与3D重建的统一框架,它从单图像出发,能够生成高质量、轨迹一致的全景视频,并直接还原可漫游的3D空间。
官方测评显示,Matrix-3D在多个主流评估指标上优于360DVD、Imagine360和GenEx,取得全景视频生成任务的SOTA成绩。同时,在相机轨迹引导下的生成任务中,Matrix-3D也在视觉质量和相机可控性方面超越现有方法。
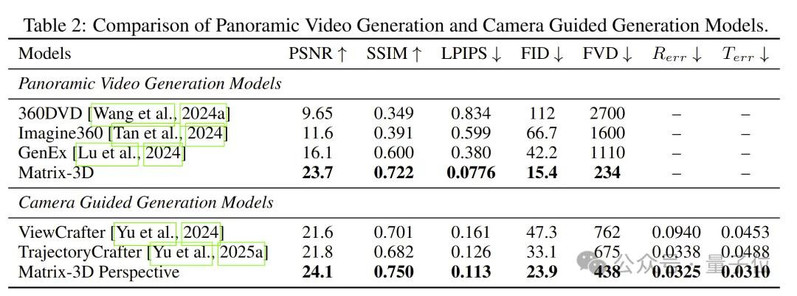

那么,Matrix-3D是如何从一众竞争对手中脱颖而出的呢?
树立3D世界生成新标杆
事实上,Matrix-3D并非昆仑万维第一次在世界模型领域大秀肌肉~
早在今年2月,这家公司就推出全新自研的世界模型——Matrix系列,成为中国第一家同时推出3D场景生成、可交互视频生成模型的探索空间智能的企业。
今年5月13日,昆仑万维也正式开源了(17B+)Matrix-Game大模型,即Matrix-Zero世界模型中的可交互视频生成大模型。Matrix-Game是Matrix系列在交互式世界生成方向的正式落地,也是工业界首个开源的10B+空间智能大模型,它是一个面向游戏世界建模的交互式世界基础模型,专为开放式环境中的高质量生成与精确控制而设计。
如今几个月过去,Matrix-3D算是昆仑万维在确立领先优势后持续投入、不断优化的阶段性成果。
并且这一次,从效果和技术突破两方面来看,Matrix-3D的优势还在扩大。
从比较直观的生成效果来看,Matrix-3D目前具备以下核心优势:
- 场景全局一致:支持360°自由视角浏览,几何结构准确、遮挡关系自然,纹理风格统一。
- 生成场景范围大:与现有场景生成方法相比,支持更大范围的、可360°自由探索的场景生成。
- 生成高度可控:同时支持文本和图像输入,结果与输入高度匹配,支持自定义范围与无限扩展。
- 泛化能力强:基于自研3D数据与视频模型先验,可生成丰富多样的高质量场景。
- 生成速度快:首个Feed-Forward(前馈神经网络)全景3D场景生成模型,生成速度更快。

话不多说,直接来看更多玩法~
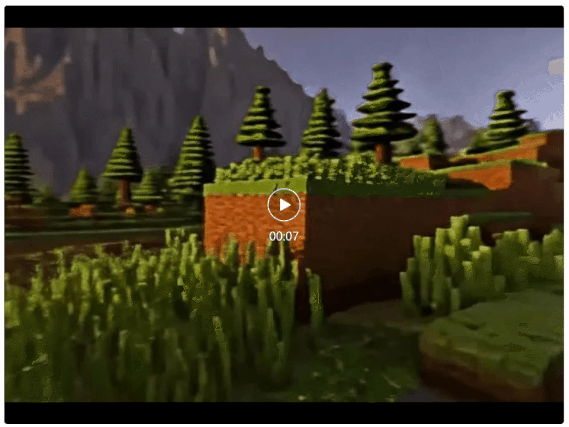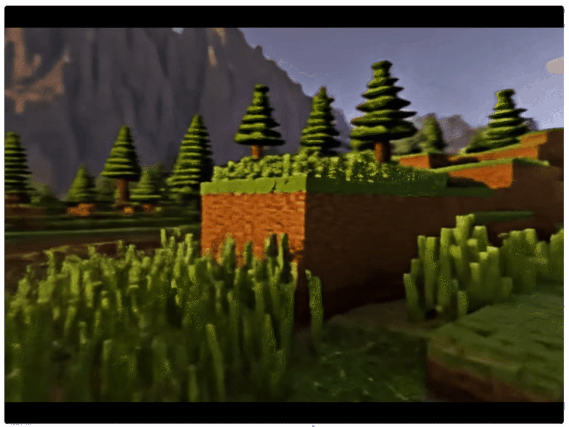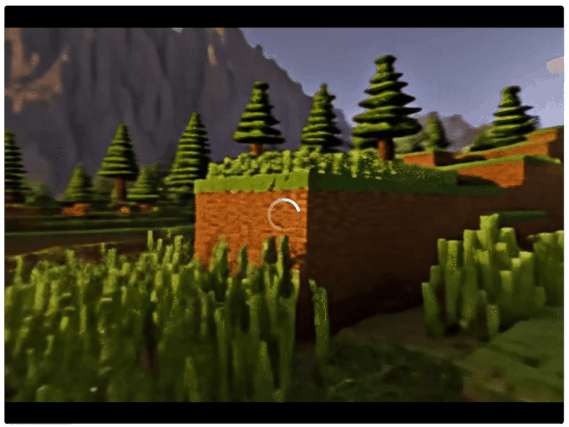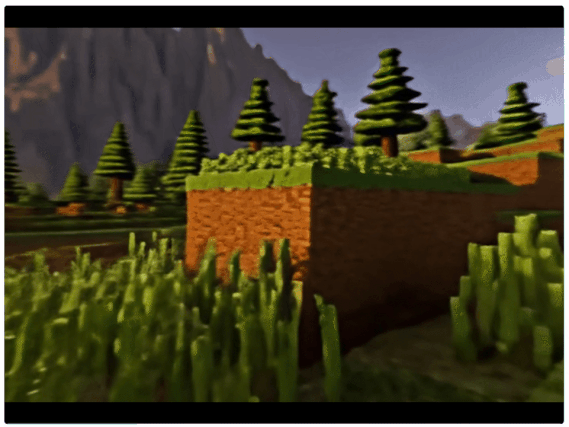
首先,Matrix-3D最极简的玩法是,开局只给它一张参考图(然后还你整片森林bushi。

咔咔一顿输出后,不仅能看到镜头环绕石堆的全景效果(补全了河流、白云等周围环境),而且连每一块石头的物理光影也能随之正确变换。

给图片加上提示词,沉浸式体验游戏的feel立马出来了。
一个方块像素化的景观,包含山脉、树木、水体、天空、云朵,类似《我的世界》风格,高分辨率,色彩鲜艳,纹理细节丰富,氛围宁静。

虽然只提供了某一帧画面,但它也能轻松还原整个场景,形成了一个可供玩家自由探索的游戏世界。
是不是很有《我的世界》内味儿了~
与此同时,正如开头提到的,Matrix-3D还支持玩家自由控制运动轨迹。
仅“看一眼”某个山坡的局部图,再结合用户提供的轨迹图,就能从各种方位开启第一视角爬山之旅。

而且不止S弯和直行,切换成其他轨迹也是OK的。(比如右前方前进)

值得一提的是,Matrix-3D还支持将全景视频转化为3D世界。
如此一来,我们就能直接对图片展开自由探索:

最后更关键的是,Matrix-3D还支持无限续写。
就是说,当用户生成一段场景后,还可以在此基础上对场景进行扩写。
跳过参考图和提示词,第一段be like:

基于第一段,镜头继续来到旁边的另一座研究基地。
可以看到,整个基地的面貌更完整了,而且没有丢失第一段中的关键素材(如第一座基地中分散在各角落的人)。

如此“俄罗斯套娃”后,最终用户将得到一个贴近提示词的科幻大片场景:
一座建在冰川上的未来研究基地,配有发光穹顶和先进机械,四周环绕着冰封景观,具有科幻美学风格,画面极为细致精美。

顺带一提,Matrix-3D提供两种场景重建方案——基于前馈神经网络的方案10s即可完成场景重建,而基于3DGS优化的方案可重建出更精细逼真的场景。

小结一下,Matrix-3D能树立行业新标杆,正是因为它在生成质量上实现了多项关键进步。
而且不止模型能力变强,从技术方面看,背后还蕴藏着团队对多项行业技术难题的成功突破。
包括但不限于下面这些:
- 相比基于透视图训练的主流思路,全景图可以突破视觉范围限制;
- 相比主流的点云渲染策略,网格渲染能有效提升几何一致性和色彩一致性;
- 基于前馈式网络的3DGS优化策略,能加速3D生成;
- 利用合成数据,3D场景数据稀缺的问题能够得到解决;
- ……
凭借产品+技术的双重优势,Matrix-3D再次刷新3D世界生成的行业标杆。
下面我们继续深入扒一扒Matrix-3D背后的技术细节。
背后技术细节
整体而言,Matrix-3D主要通过引入全景表示、条件视频生成与3D重建模块,突破了现有方法在视角范围、几何一致性和视觉质量上的限制。
其核心模块及大致作用如下:
1、轨迹引导的全景视频生成模块:根据用户输入的图片/文字,生成符合给定相机轨迹的全景视频。
2、双路径可选择的全景3D重建模块:提供分别主打精细和生成速度的两种方案,来将全景视频变成一个可自由探索的3D场景。
3、Matrix-Pano数据集:一个大规模高质量合成数据集,包含116K条带有相机轨迹、深度图和文本注释的静态全景视频序列。
对于上述组件,接下来我们按照以下思路进行详细拆解:
1)为什么要这样设计?
2)怎样实现这个设计?
3)如何训练这个模型?

为什么选用全景图而非透视图?
一上来,团队就从全局考虑了3D场景生成的泛化性问题。
受限于3D场景数据的稀缺性,目前的主流思路是利用图像或视频生成模型作为先验来实现强泛化。
简单说,前者通过捕捉2D图像中的纹理或细节等特征来辅助构建3D世界,后者则通过学习相机环视时的视角变化(由视频模型生成),来模拟空间结构和生成3D场景。
然而这类方法都是在透视图上进行训练,仅能覆盖小范围的场景,一旦用户超出该范围查看场景时,就会有明显的场景边界,影响用户的沉浸体验以及VR/AR等下游应用。(下图左半部分)
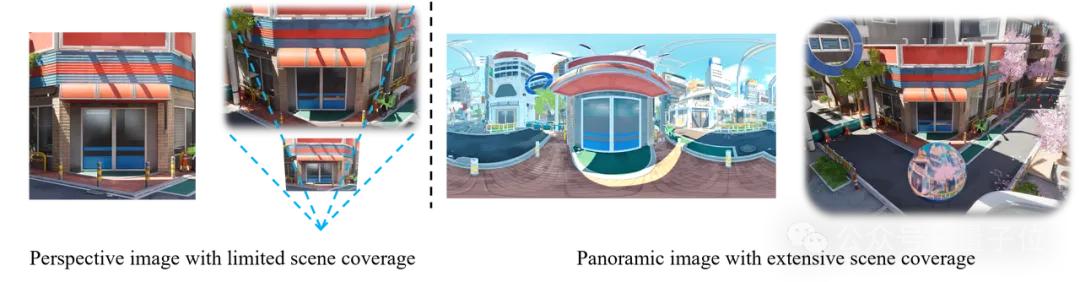
因此,为了保证生成的场景支持任意地点、任意角度查看,团队选用了全景数据作为场景生成的中间表达。
一般而言,全景图可以覆盖360°的水平视角和180°的垂直视角,支持用户在任意角度查看。一旦将多个位置的全景图拼接在一起构成全景视频,就能包含3D世界生成所需的所有信息。(上图右半部分)
三个核心模块实现单图/文本→3D世界生成
借助全景视频中间表达,Matrix-3D具体则通过三个核心模块实现从单图/文本到3D世界的生成:
- 全景图生成模块:从用户输入的文本或透视图生成全景图;
- 可控全景视频生成模块:根据用户指定的探索轨迹和范围精准生成全景图视频;
- 3D场景生成模块:从全景图视频中解码出3D场景,支持用户自由探索。
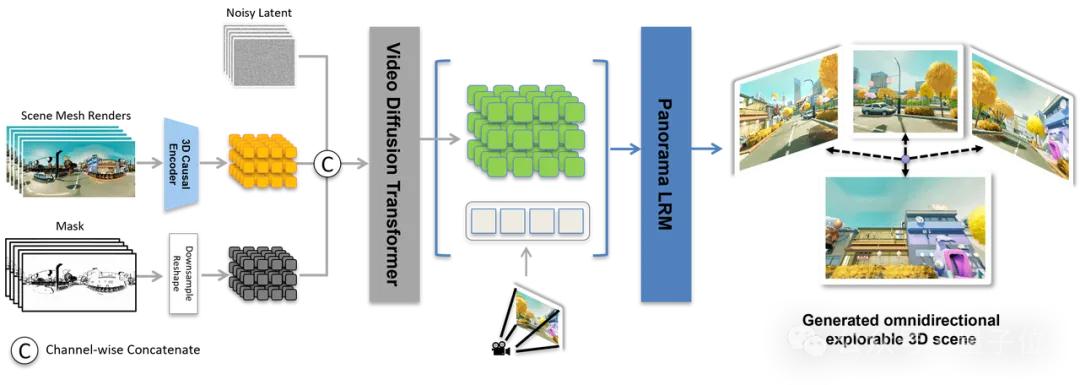
训练阶段的优化设计
训练开始前,团队将重点放在为视频扩散模型提供更精准的参考条件上。
其中,全景图的生成通过LoRA微调生图模型实现。
为了生成可控的全景视频,团队基于首帧的全景图和深度信息搭建了一个初始的3D网格,然后沿着用户设定的路径对这个网格进行渲染,作为后续视频生成的参考。
相较于当前主流的点云渲染策略,通过网格渲染得到的信号能包含准确的前后景遮挡关系,且不会出现噪声条纹。
因此有效提升了生成结果的几何一致性和色彩一致性。

然后就是根据这些精准的条件信号进行训练。
在训练视频生成模型时,团队首先对场景网格渲染结果进行编码,并将其对应的Mask(遮罩图)下采样,再将这两者和噪声隐向量在通道维度(channel dimension)拼接,一起作为模型的输入。
团队称这一设计简单有效,保证了生成结果与输入条件信号高度相符,提升了模型的控制精度。
同时,团队在模型的DiT模块中引入了Cross Attention机制,用于融合残缺视频序列和完整视频序列对应的隐向量。
这一设计进一步增强了模型输出与输入条件的匹配度,提高了全景视频生成的精度和泛化能力。
此外,为了加速训练过程,团队在视频基模上进行LoRA微调,而非全量参数训练。
当视频生成完成后,最终还需要将其转化为可交互的3D场景。对此,团队设计了两种不同的重建方式:
- 基于深度估计+透视图3DGS优化,可以生成精细的高质量场景;
- 基于前馈式网络(Feed-Forward Network)的3DGS优化,主打快速生成。
后者用Transformer网络直接从视频隐空间预测全景3DGS的各个属性,且为了加速网络收敛,提出了先训练深度、再训练其他参数的分步训练策略。

Matrix-Pano数据集
当然,以上训练也离不开一个高质量的数据集——Matrix-Pano。
现有的3D场景数据集通常存在质量和成本方面的问题。不仅普遍规模较小、质量参差不齐,且缺乏精确的相机和几何标注;同时,真实世界3D场景数据的采集成本也非常高昂。
而Matrix-Pano则完全基于Unreal Engine(虚拟引擎)构建,具备高仿真的物理和视觉效果,包含116K全景视频,共22M全景帧,涵盖室内室外504个高质量3D场景及多样的天气与光照条件。
此外,所有视频均配有精确的相机与轨迹标注。

为了支撑如此大规模、高质量的视频数据采集,团队还专门设计了一整套自动化轨迹生成与采集系统。
概括而言,这套系统主要通过三步实现高质量的视频采集:
- 轨迹生成:提出了一种高效的轨迹采样算法以生成合理且视觉连贯的相机路径,最终仅保留长度超过18米的轨迹,以保证视频序列的动态性。
- 高仿真精确碰撞检测:采用边界框代理进行路径仿真,实时剔除发生几何剪切或物体穿透的轨迹,保证全景视频运动过程的物理合理性。
- 工业级相机控制:结合控制理论对相机的位置和角度进行平滑处理,保证生成的视频具有工业级的物理平滑效果。

通过上述多步骤的数据生成与筛选流程,团队最终保留了116k个高质量全景静态视频序列,每个序列均附带对应的3D探索路径。
昆仑万维:瞄准空间智能
以上不难看出,昆仑万维确实在3D世界生成领域投入了大量心血。
而这一切背后,实则蕴藏着他们对“空间智能”这一前沿技术领域的更大野心。
何谓空间智能?简单来说,就是让机器突破传统二维视觉的限制,能够像人类一样感知、理解并作用于三维空间。
根据量子位智库发布的报告,目前它实际上分为两个层面:物理的三维世界和数字的三维世界。
在数字世界里,空间智能的代表应用即为3D场景生成,以李飞飞World Labs、腾讯HunyunWorld-1.0为代表(当然也包括Matrix-3D),这些应用通过生成高质量的3D内容,为VR虚拟现实、游戏开发和影视制作等领域提供强大的技术支持。
而在物理世界,空间智能的应用主要体现在自动驾驶、具身智能领域。这些场景在强调感知与理解的同时,更加注重“行动”能力,对交互性的要求也更高。
例如,自动驾驶汽车需要实时感知周围环境并做出决策,具身智能机器人需要在复杂环境中进行物理交互。
而最终,其目标是构建世界模型,即通过数字化的方式模拟和预测物理世界的运行规律,实现完美“人机交互”。
总而言之,对各行各业来说,空间智能普遍被视为“实现AGI的关键一步”,属于那种“有条件要上,没有条件创造条件也要上”的核心技术。

具体到昆仑万维,实际上Matrix-3D的出现并非偶然,而是其长期战略布局与技术积淀的自然成果。
昆仑万维Matrix系列世界模型正是其在AGI路径上的关键动作,包括5月正式开源的「可交互视频生成Matrix-Game大模型」,以及今天同样开源的「Matrix-3D大模型」——通过3D世界的自动生成,赋能AI对空间的识别与理解能力,这代表着其在“空间智能”方向上的重要探索。
这也符合昆仑万维一直以来的“All in AGI与AIGC”战略规划。
过去三年,他们在视觉多模态、深度学习、强化学习等核心技术领域持续投入,先后推出了多项重磅产品与平台。
包括天工超级智能体(Skywork Super Agents)、AI音乐创作平台Mureka、AI短剧平台SkyReels、AI社交产品Linky等,形成了“AI前沿基础研究——基座模型——AI矩阵产品/应用”的全栈式AI产业链。
其中,空间智能作为多模态发展的延伸方向,已成为不可或缺的一环。
Matrix-3D的出现,正是这一战略体系向“空间理解”能力进一步延伸的体现。它不仅整合了公司在多模态模型方面的技术积累,也进一步提升了昆仑万维在世界模型与空间智能赛道上的竞争优势。
当然,理念落到实处也离不开切切实实的人力、物力支持。
自2023年宣布“All in AGI和AIGC”以来,昆仑万维在AI研发上投入了大量资金和技术人员。
公开财报显示,2024年公司的研发费用飙升至15.4亿元,同比增幅达59.5%,占总营收比重的27%以上;进入2025年第一季度,这一增长趋势仍在延续,研发费用达到4.3亿元,同比增长23.4%,约占营收的26%。
光投钱还不够,去年其研发团队达到1554人,占总人数的73.41%,在国内AI企业中跻身前列。
所以说,Matrix-3D能够取得这一阶段的技术领先,实属“水到渠成”。
Anyway,尽管空间智能仍处于发展的早期阶段,但不可否认,拥有资金、技术与人才三重优势的昆仑万维,或许早已在这条通往未来的赛道上占据了先发位置。
1.GitHub:https://github.com/SkyworkAI/Matrix-3D
2.HuggingFace:https://huggingface.co/Skywork/Matrix-3D
3.Technical report:https://github.com/SkyworkAI/Matrix-3D/blob/main/asset/report.pdf
4.Homepage:https://matrix-3d.github.io/
— 完 —
量子位 QbitAI
关注我们,第一时间获知前沿科技动态







