机器之心发布
机器之心编辑部
近日,全球网络通信顶会 ACM SIGCOMM 2025 在葡萄牙落幕,共 3 篇论文获奖,华为网络技术实验室与香港科技大学 iSING Lab 合作的 DCP 研究成果,获本届大会 Best Student Paper Award (Honorable Mention),成为亚洲地域唯一获奖的论文。
上周,第 39 届 ACM SIGCOMM 大会近日在葡萄牙落下帷幕,来自世界各地的技术大牛分享了计算机网络领域最前沿的技术,为本领域的从业者贡献了一场顶级的技术盛宴。ACM SIGCOMM 是网络领域最顶级的学术会议,对论文的质量要求极高,不仅有很强的学术性,也与产业界联系紧密,吸引全世界各大 OTT 和网络设备厂商等热情参与。

本届 SIGCOMM 投稿共 463 篇,录用 75 篇,接收率仅 16.2%,全球仅 3 篇论文获奖。华为网络技术实验室与香港科技大学 iSING Lab 合作的新型 RDMA 传输架构 DCP,获本届大会 Best Student Paper Award (Honorable Mention),成为亚洲地域唯一的获奖论文。该论文提出的数控分离传输架构 DCP,解决大规模 AI 集群网络可扩展性难题,帮助构建大规模、高性能、高可靠的网络底座,充分释放 AI 算力。
该论文体现出华为公司在网络领域的深厚积累。除此奖项之外,华为网络技术实验室近几年曾在多个国际顶级会议获奖,包括 Hot Interconnects 2024 最佳学术论文奖、FSE 2024 杰出论文奖等。UB-Mesh 超节点网络架构近期在 Hot Chips 2025 发表,在业界引起广泛关注。

论文标题:Revisiting RDMA Reliability for Lossy Fabrics
论文地址:https://dl.acm.org/doi/pdf/10.1145/3718958.3750480
一、背景:算力激增驱动智算网络规模不断增大,现有传输技术面临挑战
AI 大模型快速发展,算力需求急速攀升,驱动集群网络组网规模不断扩大,通信距离也不断拉远。单一集群需要园区内多栋楼部署,同时受到部署策略、走线等物理因素限制,最大通信距离可达到 2km-10km;如果要规划更高的算力规模,供电、散热等能源问题会成为瓶颈,需要多集群联合训练,跨 AZ 场景最大通信距离可达到百公里。
当前智算网络大多沿用已有数据中心技术,主要的技术路线是基于 PFC 流控的无损 RDMA 网络。但随着组网规模的进一步增大,PFC 带来的头阻、死锁、运维等问题会更凸显,严重影响网络性能。另外,在交换机交换容量增大、交换芯片 Buffer 增长速度滞后等趋势下,该路线将会面临 Buffer 不足的问题。与此同时,业界也一直在探索高效的有损 RDMA 路线,例如在 RDMA 网卡 (RNIC) 中实现选择性重传机制。然而这条路线仍然面临 ECMP 冲突、RTO 超时等问题,并且对多路径、逐包均衡等技术兼容性不好。
针对上述问题,文章提出了 DCP(Data Control Partitioning)数控分离技术,重构了高速有损网络的 RDMA 可靠性设计,推动智算网络向容损、逐包均衡等方向演进。该方案对控制信息和数据信息采用不同传输策略,对数据信息允许有损传输,对控制信息采用无损传输,可以大大降低对 Buffer 的依赖,彻底消除 PFC 带来的头阻、死锁等问题,同时兼容多路径传输、逐包均衡等技术,支持百万卡规模、百公里等大规模、长距离、高性能网络传输的需求。
二、DCP 设计思路
DCP 是一种联合设计交换机和 RNIC 的传输架构,包含 DCP-Switch 和 DCP-RNIC。DCP 概念上定义了数据平面(DP)用于有效载荷传输和控制平面(CP)用于报文头部传输。与无损 RDMA 网络通过 PFC 同时保证 DP 和 CP 的无损性不同,DCP-Switch 引入 Packet Trimming 功能,每当网络出现丢包时,会把丢失报文的头部封装成 Header-Only(HO)报文传输给接收端;DCP-Switch 使用加权轮询(WRR)调度器来优先处理控制队列,从而确保控制平面(CP)传输的无损性,同时允许数据平面(DP)以有损方式运行。

同时,DCP-RNIC 利用无损控制平面的特性来增强 RNIC 的可靠性,实现了以下几项关键功能:
- Precise and Fast HO-based Retransmission:发送方根据 HO 包携带的 PSN 精确并高效地重传丢失的包;
- Order-tolerant Packet Reception:接收端 RNIC 可以直接将任何包(无论是有序还是乱序)写入其相应的应用程序内存地址,消除了对重排序缓冲区的需求;
- Bitmap-free Packet Tracking:DCP-RNIC 利用无损 CP 的 “Exactly Once” 特性,消除了包级别 bitmap 的需求,采用包计数来跟踪聚合的消息级信息,显著减少了内存开销和处理周期。
三、实验效果
文章针对 DCP 进行了全面的技术验证,主要包括两部分:1)原型样机测试(含 DCP-Swtich 和 DCP-RNIC);2)大规模仿真实验。
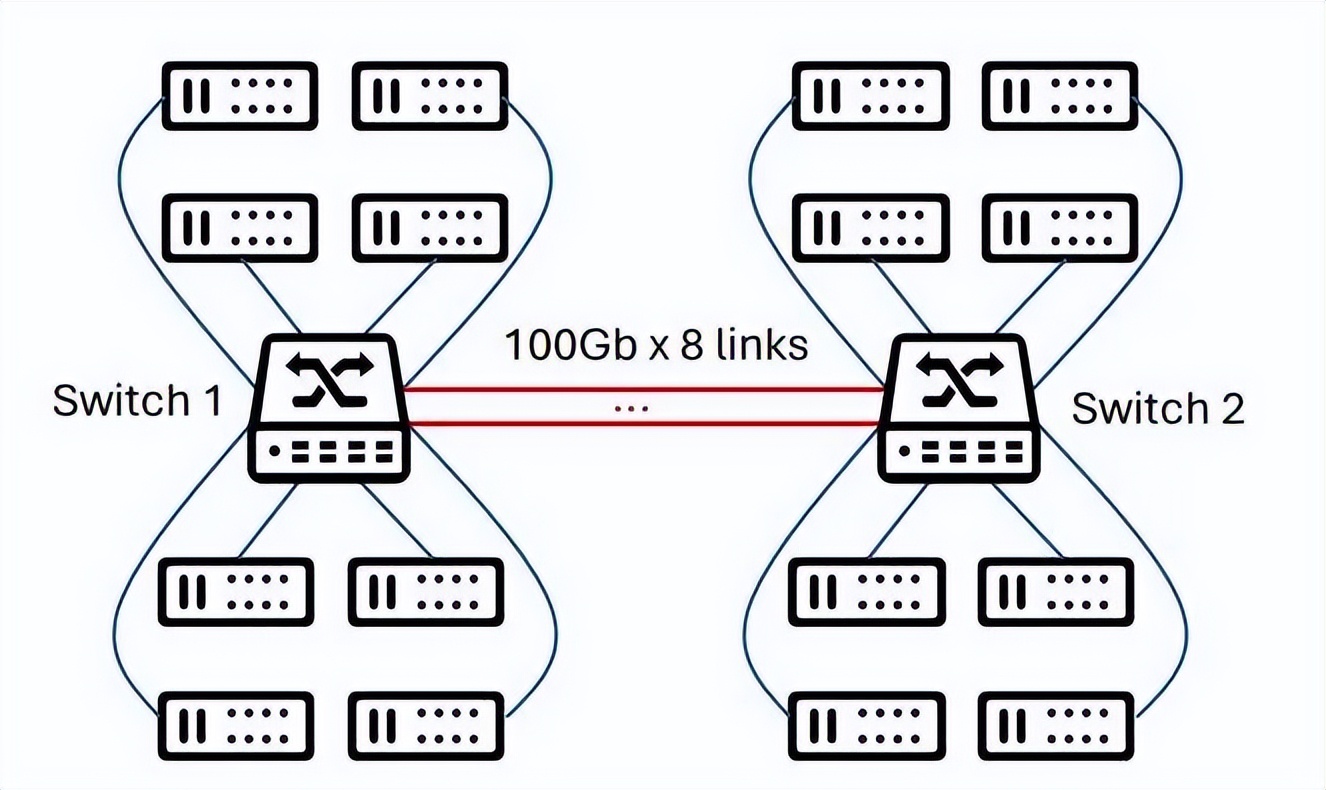
原型样机测试结果:组网拓扑如上图所示,DCP 传输技术与逐包负载均衡原生适配,相较于 Mellanox RNIC,DCP 在丢包恢复效率上提高了 1.6×∼72×,在 AI 工作负载的完成时间上降低了 42%;相较于 IRN 和 MP-RDMA,DCP 在通用负载测试上分别取得了 2.1× 和 1.6× 的性能提升。此外, DCP 在 10 公里长距测试下实现了接近理想的高吞吐,DCP 理论上可实现百公里高性能传输。

仿真实验结果:组网拓扑如上图所示,DCP 传输技术相较于 MP-RDMA 和 IRN(业界 SOTA 的 lossless 和 lossy 传输解决方案),在智算流量场景(如 AllReduce)下,平均降低了 38% 和 45% 的任务完成时间 JCT(如下图 a 所示);在通算流量场景下,分别降低了 16% 和 10% 的 P95 尾部流完成时间 FCT。此外,在 1000 公里长距大规模实验中,相较于 MP-RDMA 和 IRN 方案,DCP 分别降低了 95% 和 51% 的 P95 尾部完成时间(如下图 d 所示)。

四、总结
华为网络技术实验室提出的 DCP 技术,是一种面向有损网络的高性能 RDMA 传输架构,通过将轻量级无损控制平面与硬件高效的 RNIC 设计相结合,消除了对 PFC 的依赖,支持包级负载均衡,并避免了 RTO。原型和仿真表明,DCP 的性能显著优于现有的 RDMA 解决方案,有利于推进高性能 RDMA 传输技术在有损网络中的应用。
经了解,华为网络技术实验室在研究面向 AI 原生的传输技术 AI-Native Transport(ANT),通过逐包均衡 / 多路径、算效优先调度、容损传输等技术,为 AI 智算网络提供高吞吐、高算效、高可扩展的传输能力,本次 SIGCOMM 文章的 DCP 技术是 ANT 若干特性之一。







