
本研究由新加坡国立大学 ShowLab 团队主导完成。 共一作者 Yanzhe Chen 陈彦哲(博士生)与 Kevin Qinghong Lin 林庆泓(博士生)均来自 ShowLab@NUS,分别聚焦于多模态理解以及智能体(Agent)研究。 项目负责人为新加坡国立大学校长青年助理教授 Mike Zheng Shou 寿政。
随着视频生成模型的发展,基于像素空间(Pixel-based)的文生视频方法(如 Sora2、Veo3 等扩散模型)在自然场景生成上表现出色,但在教育场景中仍存在以下不足:
- 文本模糊、公式失真、动画逻辑不连贯;
- 缺乏对知识点的精准把控和结构化呈现;
- 难以复现、难以编辑,无法满足教学需求。
图 1: Pixel-based Video Generation对比我们的Code-driven Video Generataion
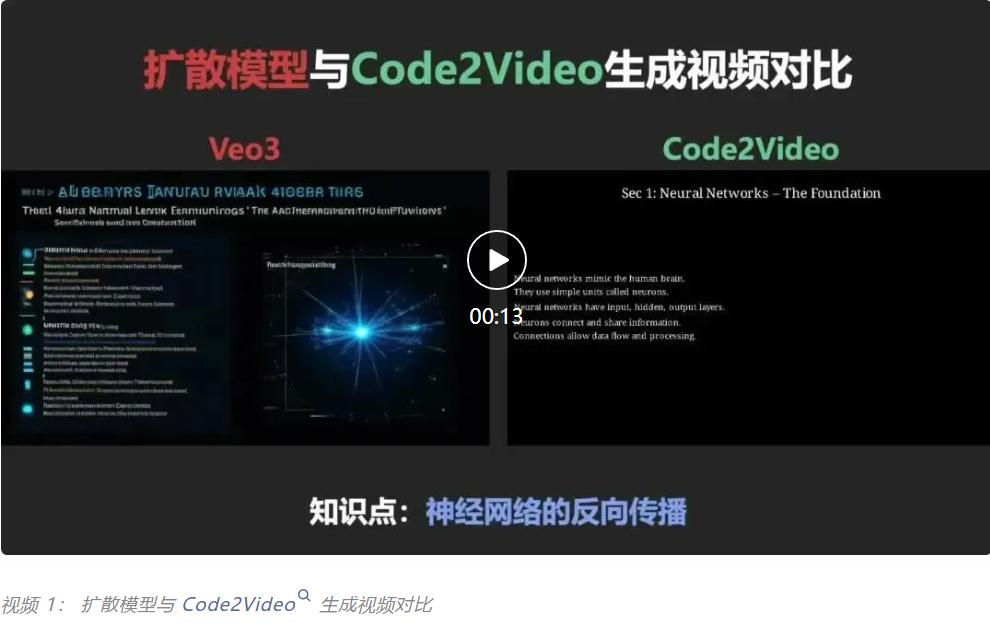
相比之下,教育视频强调的是清晰的知识传递、逻辑的演进、可控的时序与空间结构。为此,本文提出了 Code2Video——一种基于代码驱动的视频生成新范式。

- 标题:Code2Video: A Code-centric Paradigm for Educational Video Generation
- 作者:Yanzhe Chen*, Kevin Qinghong Lin*, Mike Zheng Shou
- 单位:新加坡国立大学 ShowLab
- 项目主页:https://showlab.github.io/Code2Video/
- 论文链接:https://arxiv.org/abs/2510.01174
- 开源代码:https://github.com/showlab/Code2Video
- 开源数据:https://huggingface.co/datasets/YanzheChen/MMMC
Code2Video 核心设计
Code2Video 的目标是:以可执行代码(Manim)作为统一媒介,将抽象的知识点转化为结构化、可复现的教学视频。以代码为媒介不仅保证了视频生成的可控性与可解释性,还保证了在教育视频中至关重要的逻辑流畅与视觉一致性。
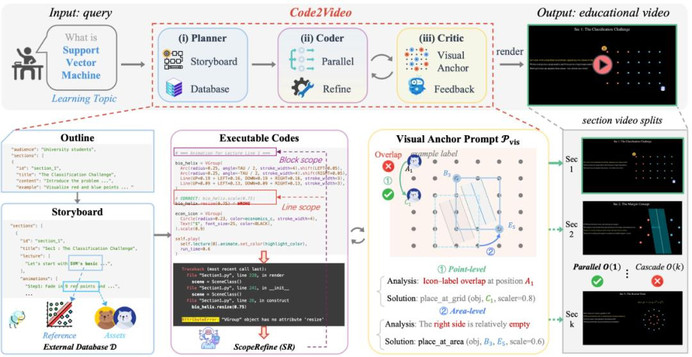
图 2: Code2Video 方法示意图
基于此,本文提出了三智能体(Tri-Agent)协同框架:
- 规划者(Planner)——从知识点出发,生成逻辑大纲与教学分镜,并通过外部数据库扩展参考图像和可视化素材,实现「宏观规划 + 细节支撑」。
- 程序员(Coder)——将教学分镜转化为可执行的 Manim 代码,支持并行生成,提出代码局部优化机制(ScopeRefine),通过类似编辑器的断点 debug 设计,大幅降低错误率和 Token 消耗。
- 鉴赏家(Critic)——利用多模态模型(VLM)反馈与视觉锚点提示(Visual Anchor Prompt)对生成的教学视频进行修正,避免元素遮挡、位置错乱,保证画面层次清晰、讲解可读。
- 为解决自动生成中常见的元素遮挡、位置错乱等空间布局问题,文本提出视觉锚点提示(Visual Anchor Prompt),为关键视觉元素(如公式、图表、文本框)在画面中的相对位置和层次提供了结构化的指导。在生成代码时,自动维护锚点提示表,记录放置对象以及对应锚点坐标;在检查到视频中布局不当时,Critic 会查表并生成具体的新锚点、以及可执行的反馈(如 move to B2)给 Coder 进行迭代修正。
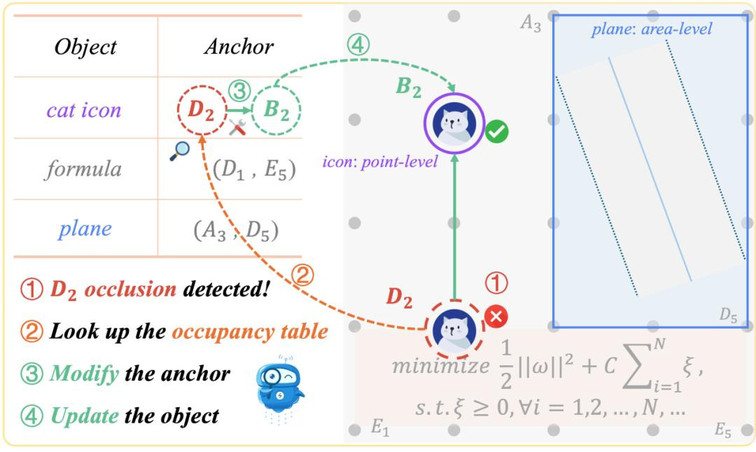
图 3: 视觉锚点提示(Visual Anchor Prompt)示意图
这种多方位的流水线协作设计,使得 Code2Video 能在以下方面发挥优势:
- 时间维度:保证讲解的时序合理与逻辑连贯;
- 空间维度:确保视觉元素的排布规范、层次分明;
- 交互维度:通过 Critic 的反馈闭环,实现自适应的优化与迭代。
Code2Video 将复杂的知识点转化为逻辑清晰、视觉精美、可扩展的教学视频,兼顾了视频质量与生成效率。
评测基准 MMMC
为系统化评测,本文构建了 MMMC (Massive Multi-discipline Multimodal Coding) 评测集:
- 来源:3Blue1Brown 官方课程(https://www.3blue1brown.com/#lessons),作为教育视频设计的参考标准(upper bound);
- 覆盖:13 个学科领域(如拓扑学、几何学、概率论、神经网络等),共计 117 个长视频;
- 切分:经作者提供的时间戳切分,得到 339 个子片段,共 456 个单元,平均长度约 3.35 分钟;
- 映射:使用 LLM 进一步抽取知识点,建立“知识点 → 视频单元”的映射。

图 4: MMMC 数据集可视化
实验与评估
本文从三个维度对 Code2Video 进行系统性评测:
- 美学维度(Aesthetics, AES):采用 VLM-as-a-Judge 的评测原则,对布局、吸引力、逻辑流、风格一致性、内容准确性五个维度进行评分;
- 效率维度(Efficiency, EFF):统计平均代码生成时长和 Token 消耗,验证方法的可扩展性与部署可行性;
- 知识传递维度(TeachQuiz):如何定量地衡量一个教学视频真正的「教学质量」?传统的视频生成指标(如美学评分)并不足以评估视频的核心目标——知识的有效传递。为此,本文提出了 TeachQuiz,一个旨在直接评测教学效果的全新范式。其核心挑战在于,作为评测者 VLM 模型通常对评测的知识点拥有「先验知识」,这使得衡量「学习增量」变得困难。为解决此问题,我们引入了一种「选择性遗忘(Unlearning 机制)+ 看视频再学习」的评测方法:
- 知识遗忘:首先通过特定方法引导 VLM「遗忘」掉目标知识点,制造出一个「知识缺口」;
- 视频再学习:其次,VLM 会观看生成的教学视频以「重新学习」目标知识点;
- 效果评估:最后,VLM 在观看视频后回答相关问题的表现,量化了该视频实际传递的知识量。

图 5: TeachQuiz 评测指标流程示意图
实验结论
- 像素方法不佳:基于像素空间的文生视频方法在 AES 与 TeachQuiz 上均得分偏低,尤其在逻辑流与文字清晰度方面存在明显不足;
- 代码范式有效:直接使用 Code LLM 生成 Manim 代码并渲染视频的新范式,相比基于像素空间的视频生成方法在 TeachQuiz 指标上平均提升约 30%;
- 性能稳健提升:本文所提出的 Code2Video 方法在美学和 TeachQuiz 指标上取得约 40% 的稳定增益;
- 专业差距仍存:在长教学视频中,专业人员制作的视频仍在叙事深度和细节把控上具备明显优势。
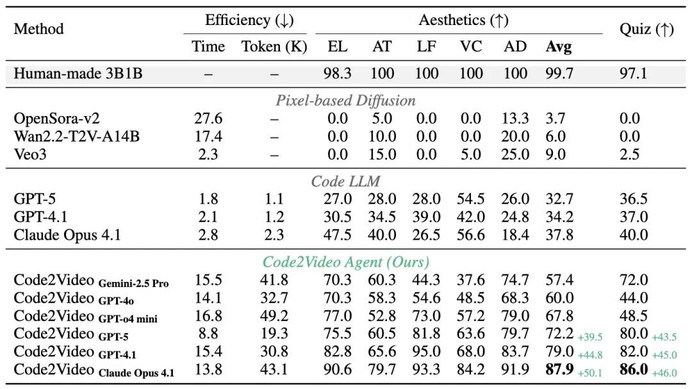
表 1: Code2Video 与各类方法对比结果
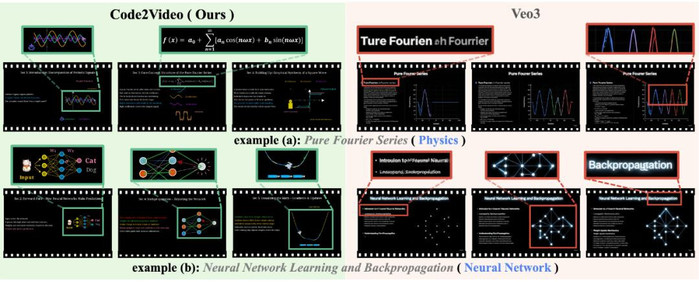
图 6: 可视化对比示例


消融实验
本文进一步对 Code2Video 的关键组件进行了消融分析,以考察各模块对视频质量与生成效率的贡献。
在视频质量方面:
- Planner 核心作用:移除 Planner 模块后,美学(AES)与知识传递指标(TeachQuiz)均骤降约 40 分,这表明高层次的讲解规划与时序建模是教学视频生成的基础。
- 敏感性差异:与美学分数相比,TeachQuiz 指标更能揭示教学视频的「知识传递能力」,即便视频在视觉表现上尚可接受,却无法支持学生对知识点有效学习。
- 模块互补性:外部数据库有助于保证概念可视化的正确性;视觉锚点能够保证元素布局稳定;Critic 模块对初步生成的视频提供进一步的迭代修正。
在效率分析方面:
- 并行执行:若移除并行设计,单个视频的平均生成时长由 15.4 分钟提升至 86.6 分钟;
- 局部优化:相较于重新生成或全局调试,代码局部优化(ScopeRefine)能够以更低的代价完成错误修复,避免不必要的重复开销。
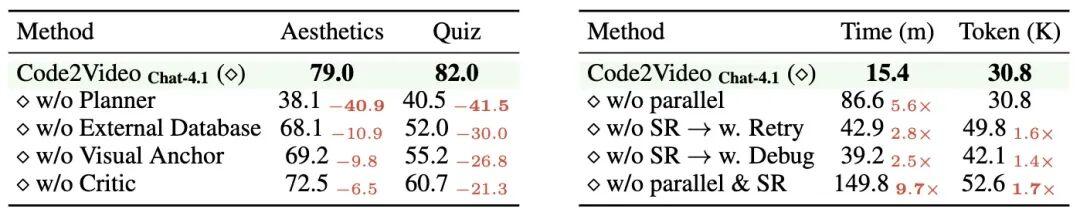
表 2: 关于视频质量(左表)及生成效率(右表)的消融分析
人类实验
本文开展了五组人类受试者实验(每组包含 6 名中学生 + 2 名本科生),每位受试者仅观看一种视频类型并完成 20 个知识点 × 5 道 TeachQuiz 测试题。结果显示:
- 一致性:受试者评分趋势与 VLM 评分一致,但分数区分度更大;
- 敏感性:对遮挡与布局错误极其敏感,即便短暂错误也会显著拉低评分;
- 注意力限制:专业制作的教学视频存在因时长过长,受试者常跳过片段,导致 TeachQuiz 得分降低的情况;而 Code2Video 生成的短视频更契合受试者注意力范围;
- 相关性:美学得分与 TeachQuiz 得分高度相关,这表明好的教学视频能吸引受试者积极参与,从而获得更优的学习成果。
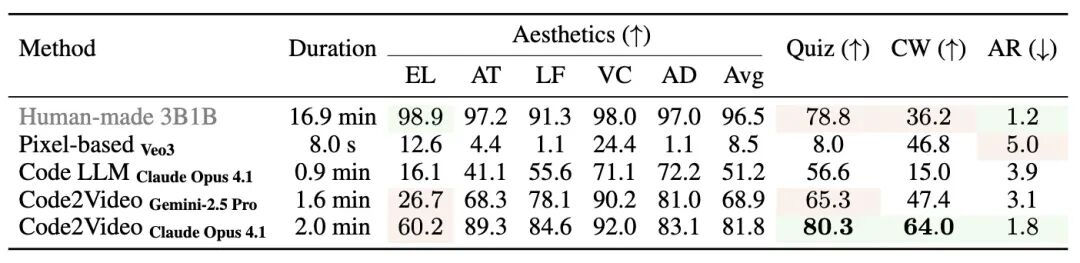
表 3: 受试者实验结果对比
结语
本文提出教育视频生成的新范式——以可执行代码为核心媒介,结合三智能体协同框架,实现高质量、可控、可解释的教学视频生成,为未来自动化教育内容创作与多模态智能系统的发展提供了坚实基础。







