
在人工智能飞速发展的今天,AI 生图和视频生成技术正不断刷新我们的创作体验。商汤 Seko 平台近期的功能更新,更是让创作者们眼前一亮。从丰富的生图模型选择到多样的视频模型支持,从精准的对口型功能到新增的粤语和英语音色,Seko 正在成为视频创作者的得力助手。

趁着他们即梦4.0和Nano模型正在限时免费、VEO3 模型半价的时候再更新一篇,探索他们现阶段的整个视频Agent的工作流程。
目前发现最棒的几点优化:
1. 在生成图片阶段就可以选择指定生图模型;
2.可以选择指定视频模型,非常齐全,我们的爱用款都在里面了;
3.增加了大量对口型音色,增加了新的语言粤语和英语。
不过这里要注意,目前最好选择上传主体,这样才会出现生图模型的选择。
目录
1. 一致性生图模型超全
2. 多人场景一致效果
3. 动物与物品一致效果
4. 粤语对口型
5. VEO 3 有声版效果
6. 小结
1. 一致性生图模型超全
这个视频中我全程使用的是即梦4.0生成图片,可灵2.1首尾帧,一共有32张分镜图👇
提示词:
为@阿真制作一个 30 秒左右的冒险短片,主角为参考图中的蓝色头发、蓝色外套的可爱卡通女孩。影片需要 10 个分镜场景,每个分镜既有不同环境,又有不同景别,整体连贯,带有冒险故事氛围。
分镜要求
场景多样化:森林、雪山、沙漠、城堡、海底、未来都市、古代遗迹、天空之岛、火山口、星空草原。
景别变化:远景展示环境、全景交代人物、近景突出动作、特写强调表情。
动作线索:奔跑、探索、攀爬、惊讶、战斗、微笑、发现宝物。
画面风格:明亮、治愈、梦幻的动画渲染,柔和色彩,卡通Q版视觉。
首先我们在主页打开添加出演主体,添加后输入提示词。如果没有主体,可以直接点击【画风】选择指定画风。另外注意主体,最好选择正面、近距离、清晰且动作不会遮挡面部细节的图片。

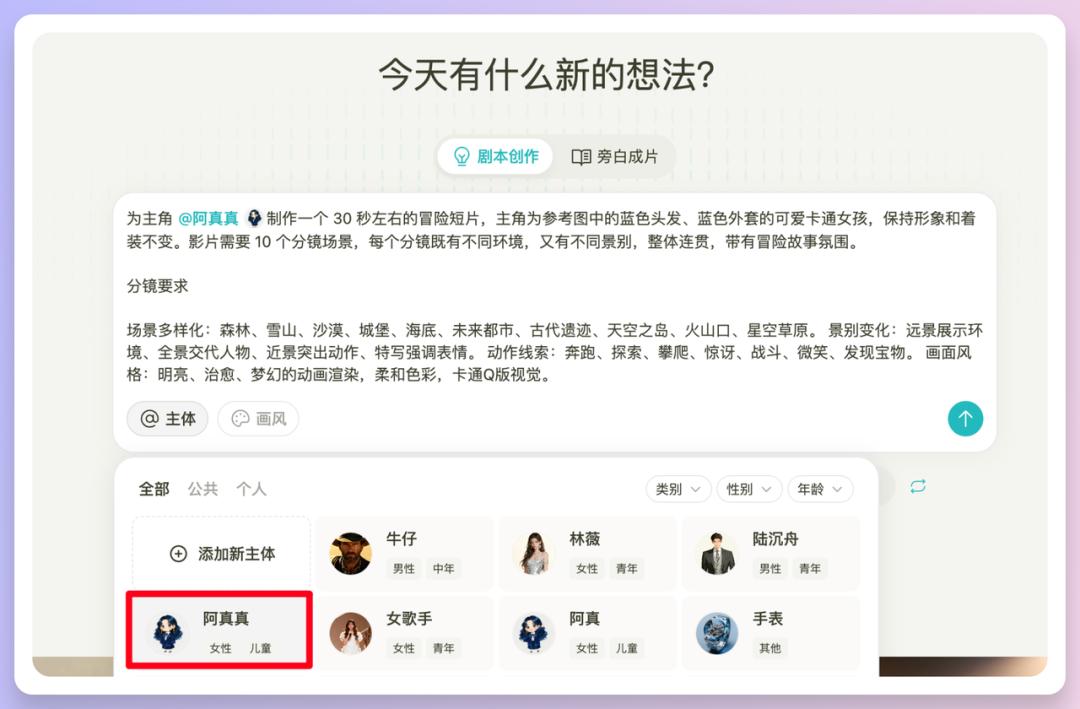
点击【添加新主体】,主体的图片可以自行上传,也可以直接输入提示词,点击AI生成。输入提示词的时候,可以要求场景或者分镜数量,另外景别、画面风格等都可以有。
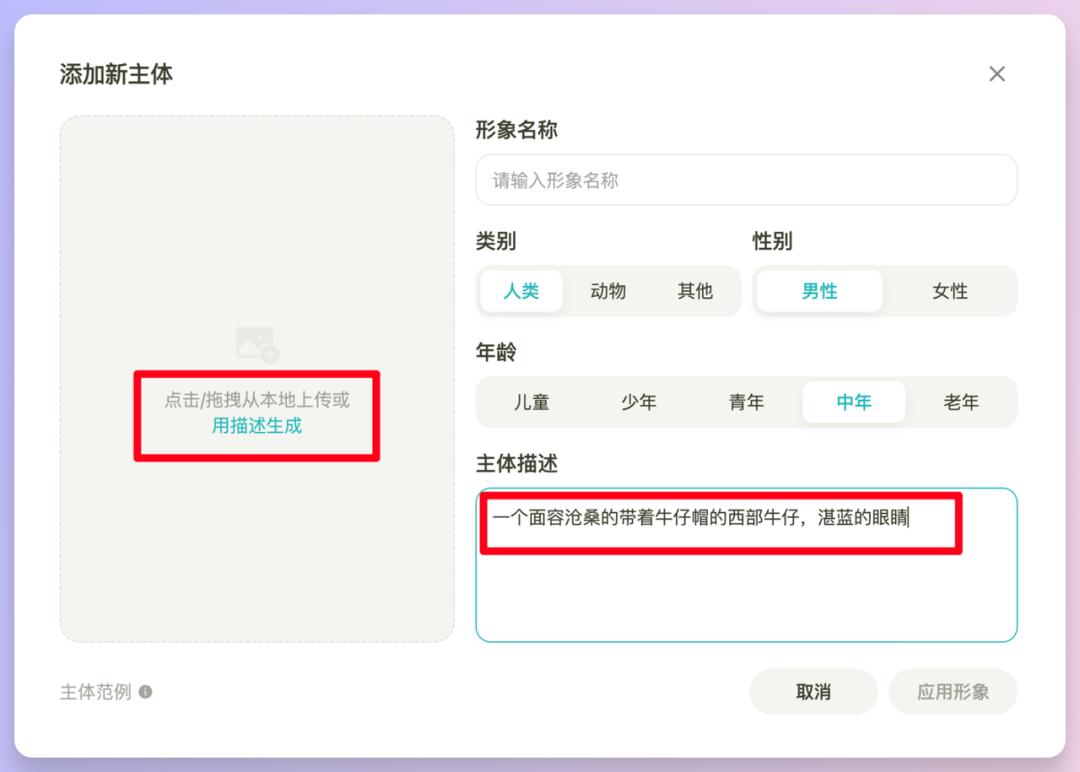
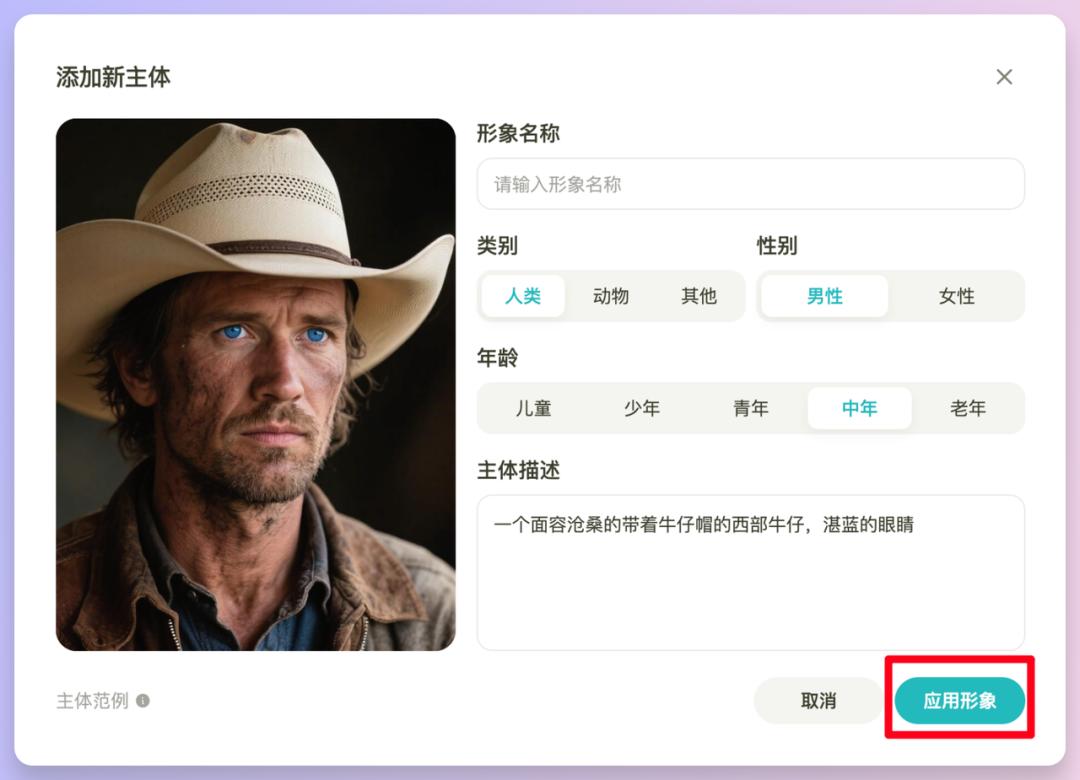
然后是绘图和整个策划部分。值得注意的是生成分镜图这里的生图模型可以选择了,有Seko IDX 、即梦4.0、Flux.1 Kontext Pro、Nano,现在最顶一致性最好的几个生图模型全都在了。


我这里选择了即梦4.0,首先是好用,其次是限时免费,看大家个人喜好,Nano也免费嘿嘿。【画面比例】也可以选择了,现在预设有4个常用比例,横竖屏都有。
注意一点,那就是Nano会根据上传的主体图片的比例生成图片啊啊啊一定要注意。
下方可以看到生成好的分镜图已经按照我们的要求出现在操作区了,这里它基本上是每个场景生成了3个不同景别的分镜图👇
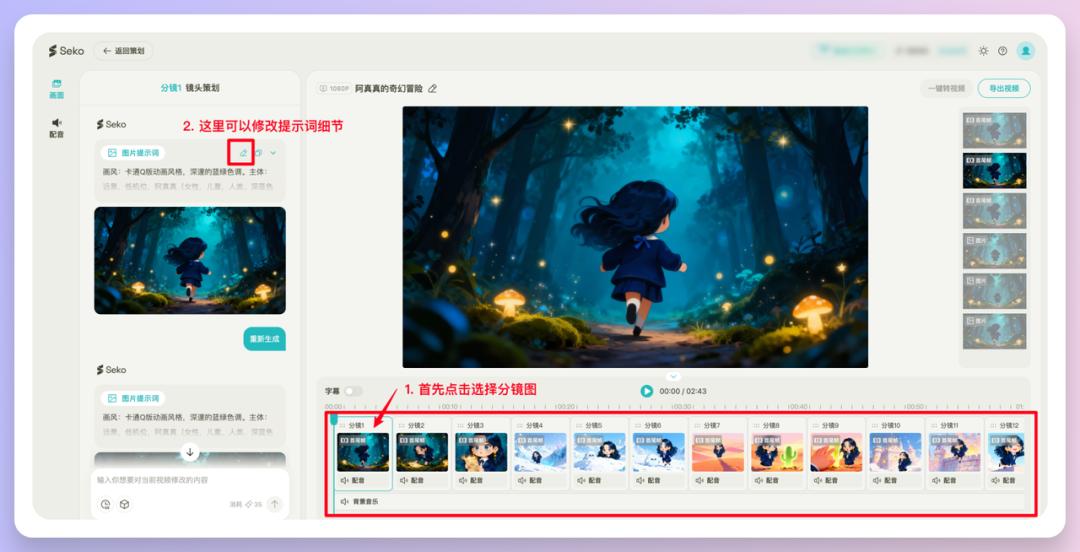
这个视频我在前一步的分镜图片生成那里选择的即梦4.0,我保存了几张分镜图,从生成视频效果可以看到一致性效果真的非常不错。
在生成视频之前,有觉得不合适的图也可以换掉。比如最开始这个场景,仙人掌感觉好像有点太扎了,选择【重新生成】

等图片都调整好了,就可以开始转视频了,转视频也有两种,一种是分镜生视频,相信大家也都比较熟悉了,这里的视频模型非常多和全。

下方是分镜生视频可以选的模型👇
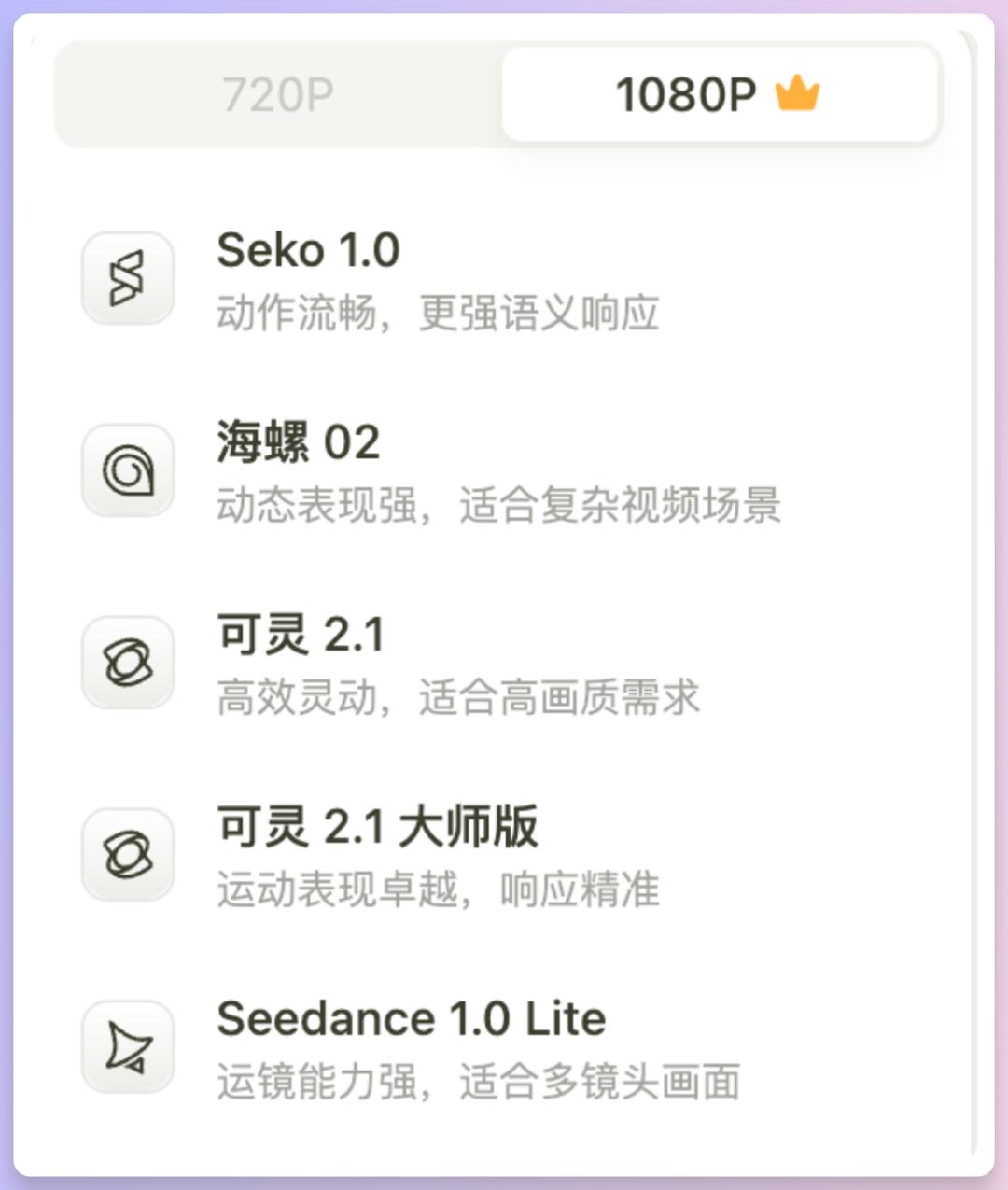

另外就是首尾帧视频支持的模型,我上面的视频很丝滑就是使用了首尾帧功能,使用方法是点击下方的【转视频】然后选择【使用下一分镜首帧图】。然后选择小正方体点选视频模型,这几个模型也都非常哇塞。

有一点要非常注意!那就是当我们在生成视频之前务必要考虑清楚使用什么分辨率,不要直接就点击生成。因为如果我选择的是720P,那么接下来的所有分辨率都只可以使用720了。因为为了效果,成片多个镜头渲染导出一定是统一分辨率的。模型可以使用多种不同的,根据需要使用就可以。
2. 多人场景一致效果
在前面我们已经看到了,一个主体效果挺好的,那么多个呢?
来啊,把男主角和女主角呈上来!(狗血小短剧看多了后遗症)
这个视频中我使用的是即梦4.0生成图片,海螺02分镜转视频,部分使用对口型视频👇
可以看看连续多分镜的情况下的角色效果。连续分镜功能真的很不错,可以一次性制作超过2分钟的视频内容,几十个镜头一次输出分镜图,而且角色形象保持一致效果很不错。对做较长视频的创作者来说很方便了。复杂的剧情表达、不同的拍摄角度、精准的位置关系,现在都可以好好尝试一下了👇
提示词如下(来自DeepSeek AI编剧大大的狗血剧情,如果有同名实在对不住啊):

这里我使用旁白成片,就选了2个主体,小角色就让Seko自己生成得了(主要是懒)。

在分镜转视频的时候,可以自己修改提示词👇

其他操作和前面还是一样的,最后我感觉有点安静,导出后加了一点环境音音效。
3. 动物与物品一致效果
然后我尝试了动物和物品融合后的一致性保持效果。下面是2个主体👇

提示词:
@猫教父 猫代言 @手机,无旁白无对话。
猫咪是直接让Seko在主体中生成的,因为Iphone 17我只上传了一张背部的图片,所以厚度它是不好判断的,但是背壳的一致性保持很不错,从图片到视频都比较稳定,个别图片不满意点击了重新生成。
这个视频中我使用的是即梦4.0生成图片,海螺02首尾帧视频👇
4. 粤语对口型
另外我还尝试了下粤语对口型效果。这里致敬一下经典电视剧,看过的朋友们估计他一开口就知道了。
这个视频中我使用的是对口型视频👇
提示词:
“什么?你连七万块都存不到?你吃也廉价,穿也廉价,全身都廉价,你哪有地方需要花钱的?你的理财能力也太差了吧?”只需要这一个镜头场景。
别骂了,别骂了哈哈哈🤦
来来,看看操作方式,非常简单,对口型效果也好。
这里如果我们想要的图片是我们原始的那张,可以点击分镜图位置,会出现一个小加号图标,可以在这里上传自己的图片👇

我直接上传了新的图片,去掉了旧的图片。然后左边选择配音-对口型,然后输入全部台词👇

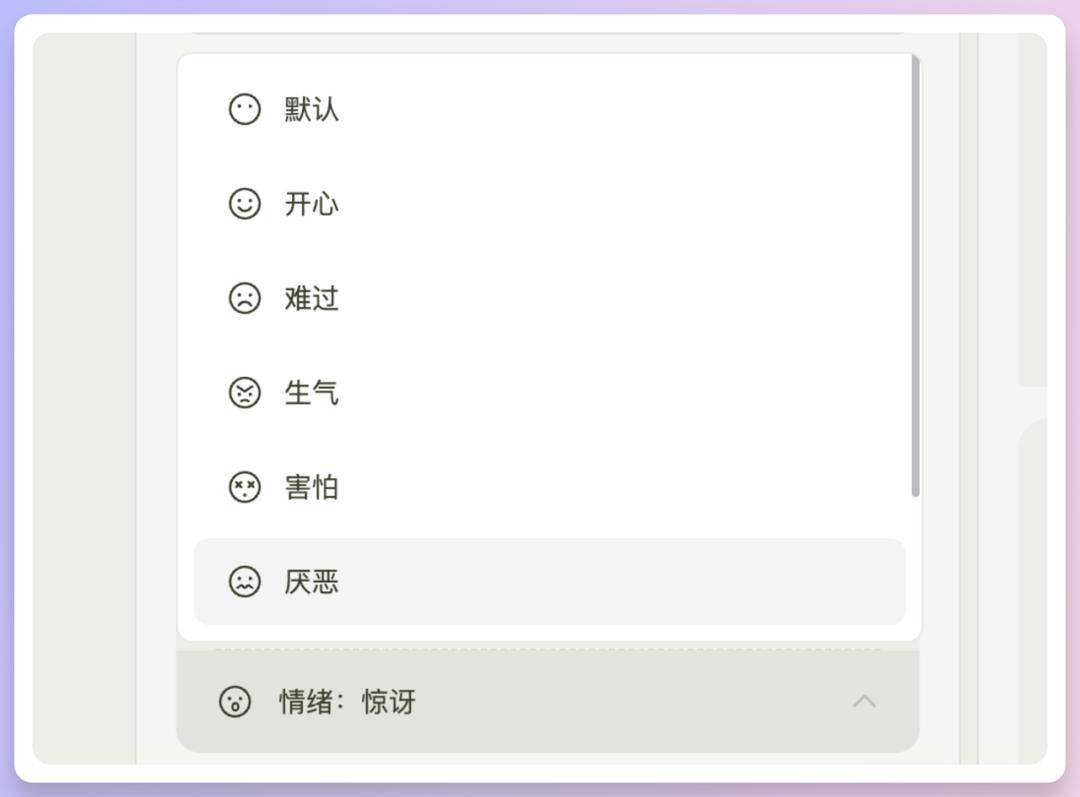
值得一提的是声音音色增加了非常多,粗略看了下至少60种以上,还增加了声音情绪,有8种情绪可以选:

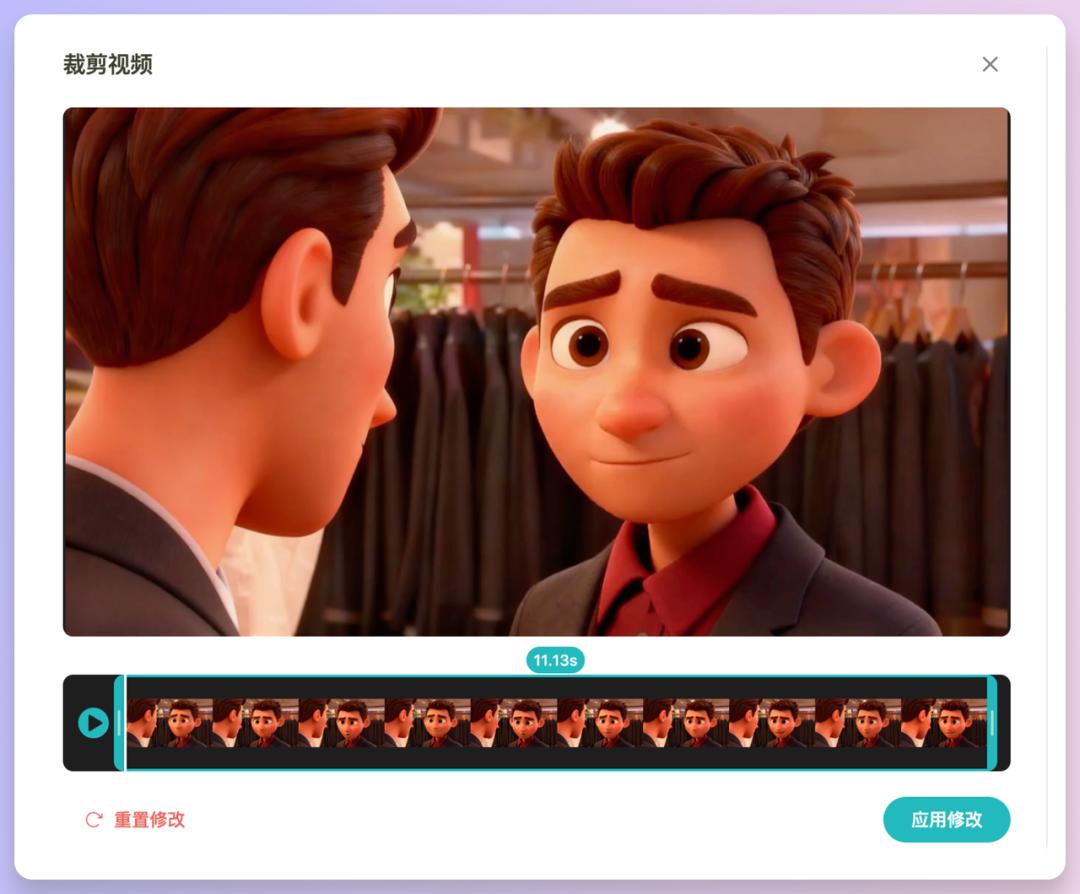
还有关于视频时长的一点,视频时长方面,现在有三种选择:5秒、10秒,或者直接按配音长度来定。如果选了”裁剪至配音时长”这个选项,视频就会自动匹配我们的旁白或角色对话的长度。也可以手动调整,点击分镜按钮里的剪裁图标就能自定义时长了👇

觉得满意,直接右上角点击导出视频就可以了。
5. Veo3 有声版效果
下面这个视频中我全程使用的是即梦4.0生成图片,VEO3 音效版生成视频,直出没怎么优化粗糙了点,大家将就看一下哈哈哈👇
最后补充一个知识点,在想要增加或重新生成分镜图片的时候,可以输入@来艾特我们之前设定好的主体,这样就可以保持一致性了,这个很好用。
小结
基于本次尝试,Seko在下面这些方面都做得很不错👇
- 图片视频模型选择:生图有即梦4.0、Flux.1、Nano,生视频有海螺02、可灵2.1、VEO3、SeedDance等等一大堆,基本上现在最顶的模型都齐了。也不用到处跑平台,一个地方就能都用上。
- 一致性保持:不管是单人还是多人场景,连续几十个分镜下来角色都不会跑偏,个别图片可以直接选中,通过对话优化修改再生成视频,这个对做视频的朋友来说真的很省心。@主体功能很贴心,直接艾特就能保持一致性。
- 音色与对口型:多种音色、8种情绪,选择更丰富,我们在视频中安排多个角色也有了更多音色选择。口型同步很好,商汤自家的舒适区了。
- 工作流:从分镜到成片一条龙,首尾帧功能让视频过渡非常丝滑,从头做到尾也不用几个工具反复横跳了。除了分辨率选定后不能改这点要注意,整体用下来是很流畅的。
上次我写Seko提到过的一些小问题,比如生图不能选,滑块拉动之类的细节现在都优化了,很贴心。
本文由人人都是产品经理作者【阿真Irene】,微信公众号:【阿真Irene】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






