
自 Sora 亮相以来,AI 视频的真实感突飞猛进,但可控性仍是瓶颈:模型像才华横溢却随性的摄影师,难以精准执行 “导演指令”。我们能否让 AI 做到:
- 仅凭一张静态照片,就能 “脑补” 出整个 3D 空间,生成一段围绕主体的 360° 环绕视频?
- 现有的视频能否进行重新运镜,实现推、拉、摇、移等复杂的电影级镜头调度?
这些需求在影视制作、游戏开发、虚拟现实等领域至关重要,但实现起来却困难重重。现有的技术路线往往顾此失彼:要么通过微调(Fine-tuning)模型来实现,但所需算力昂贵,且易损害模型内在的 “世界知识”,导致生成质量下降;要么采用 “扭曲 - 重绘”(Warp-and-Repaint)的策略,但引导信号带有的噪点和伪影,往往会误导模型,造成几何结构错乱和细节失真。
有没有第三条路?一条既能实现精准控制,又不牺牲生成质量,还无需重新训练的优雅路径?
西湖大学 AGI 实验室的研究团队给出了他们的答案。他们提出了名为 WorldForge 的全新框架,以一种 “即插即用” 的推理时引导方式,在不改动任何权重的前提下,为视频扩散模型装上了一个 “导演大脑”,成功实现了单图到 360° 世界生成和电影级视频轨迹重运镜。

- 论文标题:WorldForge: Unlocking Emergent 3D/4D Generation in Video Diffusion Model via Training-Free Guidance
- 论文链接:https://arxiv.org/abs/2509.15130
- 项目主页:https://worldforge-agi.github.io/
本文第一作者宋晨曦,现为西湖大学 AGI 实验室博士后研究员,研究方向为 3D/4D 场景重建与可控生成。指导老师为西湖大学助理教授张驰。

图 1 WorldForge 实现单图 3D 场景生成与 4D 视频重运镜

方法概述:免训练引导框架,在推理时为视频模型注入 「时空几何」
WorldForge 的核心思想是:不在训练阶段 “改造” 模型,而是在生成过程的每一步进行精巧的 “干预” 和 “校准”。它将用户定义的相机轨迹作为指令,通过一系列创新的引导模块,确保模型在自由发挥创造力的同时,严格遵守时空几何的一致性。
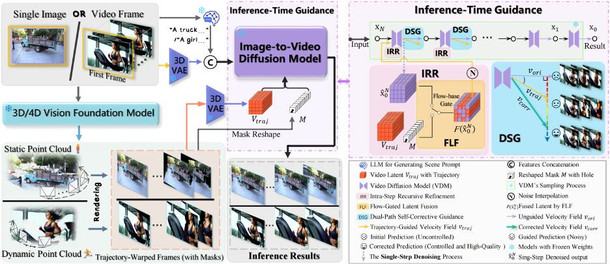
图 2 WorldForge 的流程图
整个框架的精髓,体现在以下三个关键创新点上:
1. 步内递归修正(IRR):高精度 “导航”,注入轨迹引导
要确保 AI 生成的运动严格遵循预设的相机轨迹,核心挑战在于如何将外部的控制信号精准有效地注入到模型的生成过程中。
IRR 模块为此引入了一种巧妙的步内递归优化机制:在每一步的推理过程中,首先让模型自由预测下一刻的内容,然后识别出画面中参考内容存在的 “已知区域”,并用真实内容替换掉模型的预测。通过这种增量式的逐步校正,IRR 能在每一步有效注入轨迹控制信号,避免轨迹逐步漂移。
2. 流门控潜在融合(FLF):动静分离,精准 “手术” 不伤细节
在 VAE 的潜在空间里,各通道分工不同:有的负责外观纹理,有的负责运动驱动。若把轨迹信号一股脑注入所有通道,必然干扰外观通道,破坏细节。因此关键在于:只把 “运动指令” 精准送达运动通道,避免触碰外观通道。
FLF 模块基于光流相似性,区分出潜空间中的 “运动通道” 和 “外观通道”,并仅向运动通道注入控制信号,从而保护外观通道不被干扰。它实现了动静分离,使得相机视角操控与画面细节得以兼顾。
3. 双路径自校正引导:“即兴” 与 “临摹” 互补,兼得轨迹与画质
生成模型往往面临一个两难困境:可控性与生成质量往往难以兼得。强引导(用深度扭曲得到的目标帧)虽然能确保模型 “听话”,但这个引导信号本身带有噪声和误差可能会影响最终的生成质量。因此,真正的挑战在于,如何设计一种机制,让模型既能遵从引导信号的轨迹,又能规避掉其带来的负面影响,保持自身强大的生成先验?
DSG 策略为此引入了一个非常精巧的动态引导机制。它巧妙地利用了 IRR 模块在去噪过程中产生的两条并行路径,将它们作为并行的 “解空间探索者”:
- “即兴创作”(Non-guided Path): 模型的原始预测。这条路径就像成一位技艺高超的艺术家凭借其深厚的功底和艺术直觉进行创作。其作品质感一流,细节丰富,但创作主题是自由的,不受约束。
- “精准描摹”(Guided Path): 注入轨迹引导后的模型预测。这条路径则像一位一丝不苟的学徒,严格按照一张已有的 “蓝图” 进行描摹。它确保最终画面的构图分毫不差,但代价是会一并复刻污点和瑕疵。
DSG 的核心操作是在每个去噪步骤中,计算两条路径的差异,形成动态校正项,将引导路径的结果向非引导路径的高质量解拉近,从而在轨迹精确性与画面质量之间取得平衡。

图 3、 消融实验
方法亮点:从静态到动态,从生成到编辑
凭借上述设计,WorldForge 在多项高难任务上表现突出:
亮点一:单图直生 360° 环绕视图,驾驭复杂开放场景
仅需一张照片,即可生成清晰、稳定、几何一致的 360° 环绕视频。无需先做全景中间件,更适合以目标为中心的复杂场景,这正是传统外向全景(outward-facing panorama)方案的短板。

图 4、 单图输入的 360° 场景生成
亮点二:视频的电影级可控重摄影
用户可为任意视频指定希区柯克变焦、弧形环绕、升降摇移等复杂轨迹。WorldForge 能稳定 “重拍” 并自动补全新视角内容。在人脸、动态物体与复杂环境中更稳,减少肢体变形、物体漂浮等问题。

图 5 视频重运镜效果
亮点三:视频内容的编辑与再创作
- 视频去抖与视角切换:在保持几何一致性的前提下去除视频抖动,并平滑切换不同机位;
- 物体擦除与添加:智能识别并移除画面中不需要的物体,或自然地添加新元素,使编辑结果与周围环境无缝融合;
- 主体变换与虚拟试穿:灵活替换人物主体或特定区域内容,并能为人物主体更换不同服饰或外观风格。

图6 视频去抖

图 7 视频编辑(物体消除)

图 8 虚拟试穿
亮点四:Training-Free,强泛化、易落地、低成本
WorldForge 最大的优势之一在于其无需训练(Training-free)的特性。这意味着它:
- 灵活可迁移:作为一个即插即用的模块,能够应用于多种主流视频模型,无需针对性训练。
- 泛化能力强:WorldForge 具有卓越的跨域适应性,无论是真实的摄影、艺术创作还是 AI 生成素材,都能稳定适配。
- 成本友好:免去重训与数据筹备,降低门槛,让高质量 3D/4D 创作更易获得。
结语:迈向 “可控世界模型” 的轻量路径
WorldForge 的出现,不仅仅是一项技术的突破,更代表着一种新的范式:在不牺牲大模型先验知识、不增加训练成本的前提下,于推理阶段实现对生成过程的精准控制。它证明视频模型不仅是一个出色的内容 “生成者”,更能成为一个听懂指令的 “执行者”。这项工作极大地降低了高质量的 3D/4D 视觉内容的创作门槛,为影视预览、游戏开发、数字孪生领域提供了强大的新工具。
展望未来,当这种精准的时空控制能力与更强的多模态理解(如语言、草图)相结合,我们或许只需通过口头描述或简单勾画,就能导演一部完全由 AI 生成的 “时空大片”。WorldForge 无疑为通往那个 “可控世界模型” 未来,提供了一条具有光明前景的技术路径。







