AI胡说八道,不是因为它“太聪明”,而是因为它“没知识”。RAG技术正在成为解决大模型幻觉的关键方案,让生成内容不再凭空捏造,而是有据可查。本文将从底层机制到产品应用,拆解RAG如何为AI注入真实认知。

什么是RAG?
RAG:检索增强生成,是AI领域非常重要的一种技术其核心作用是给LLM大模型外挂专门的知识库,指导大模型生成更准确的输出。
RAG是一种AI框架,它将传统信息检索系统(例如数据库)的优势与生成式大语言模型(LLM)的功能结合在一起。LLM通过将这些额外的知识与自己的语言技能相结合,可以撰写更准确、更具有时效性且更贴合具体需求的文字。
为什么大模型要做RAG?
存在幻觉问题
LLM大模型知识的底层原理是基于数学概率进行预测,模型输出本质上是一种概率预测的结果。所以LLM大模型有时候会出现胡言乱语,或生成一些似是而非的答案,在大模型并不擅长的领域,幻觉问题会更加严重。
缺乏对专业领域知识的理解
LLM大模型知识的获取严重依赖训练数据集的广度,但目前市面上大多数的数据训练集都来源于网络公开数据,对于企业内部数据、特定领域或高度专业化的知识,大模型无法学习到。
知识时效性不足
大模型的内在结构会被固化在其被训练完成的那一刻,但是当你询问大模型一些最新发生的事情,则难以给出答案。
缺乏对生成结果的可解释性
LLM大模型本身就是一个黑盒,这个模型使用了什么数据进行训练,对齐策略是怎么样的,使用者都无从得知。对于大模型生成的答案,更加难以追踪溯源,通过检索增强就可以直观了解到模型生成内容的依据所在。
RAG的技术原理
通过将大语言模型与外部信息源相整合,来提升模型的输出质量,RAG从外部知识库中检索相关的上下文(context),并将这些信息连同用户的问题一起传递给大语言模型,从而提高输出的准确性和可靠性。
工作流程
对知识库进行文本分块→文本块丢入嵌入模型(将文本块转变为向量)→向量嵌入模型(向量用一组数据表示)→向量存储于向量数据库→检索(找出与用户查询最为相关的内容)→进一步筛选出k个文本片段(系统将进一步从中筛选出,排名靠前的k个文本片段(top k text chunks–context))→重新排序→放入新的提示词模板里(上下文context+用户问题query)→发送给大模型生成答案→将答案输出给用户
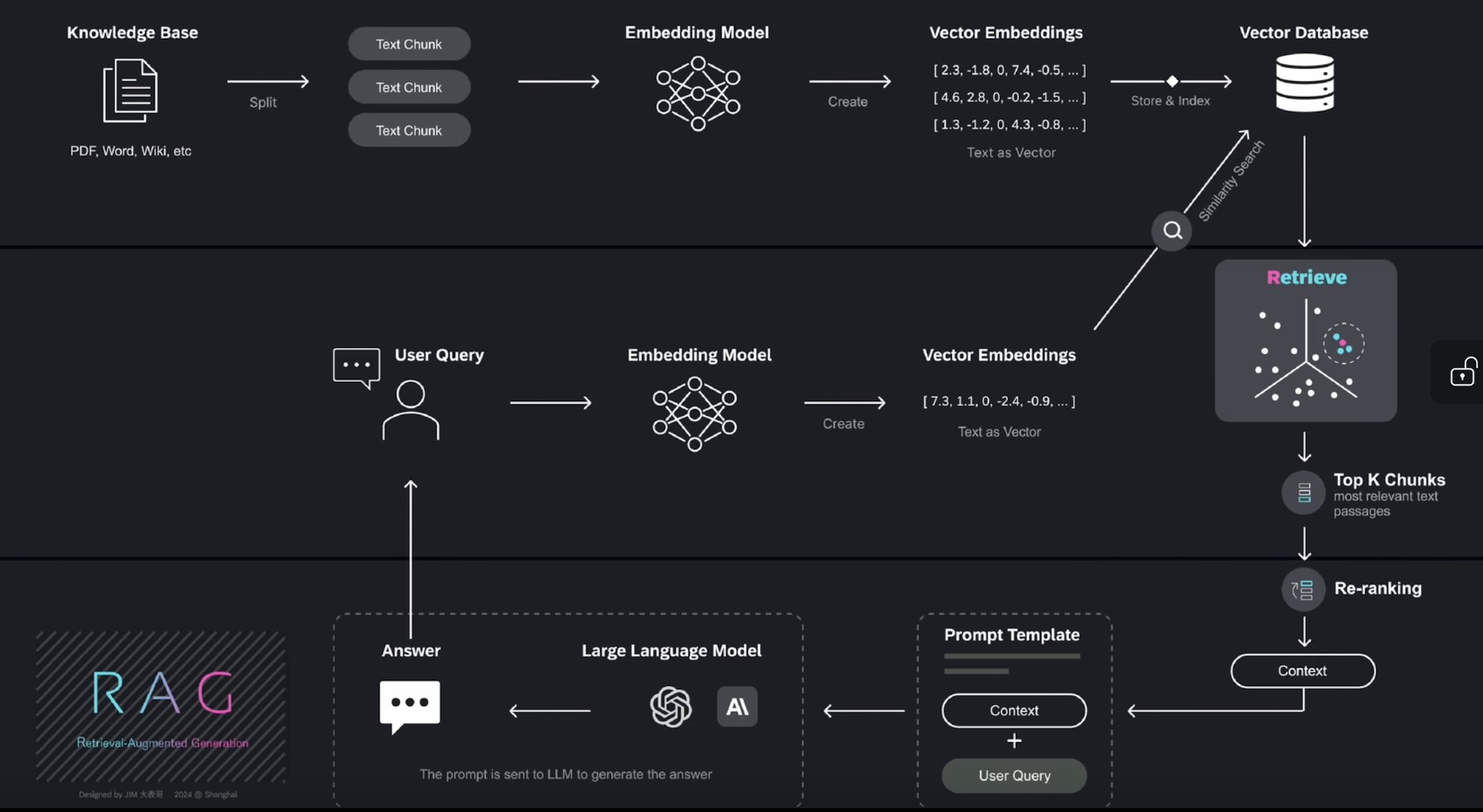
首要步骤:针对知识库内各类格式的文档(如PD、Word、Wiki等)进行处理,文档分割(检索的准确性和生成模型的效果)。
文本分块:将文本分割成有意义的片段或块的过程(能显著改善信息检索和内容生成效果,提供更精准、相关的结果)。这些文本块将由embedding mode(嵌入模型-机器学习模型,可将高维输入数据如文本、图像,转换为低维向量)转换为向量(向量捕捉了文本的语意信息,从而可以在海量文本库中检索相关内容)。
向量嵌入模型(vector embedding):使用一组数值表示的数据对象在多维空间中捕捉文本、图像或音频的语意和关联,可以让机器学习算法能够更轻松地应对其进行处理和解读。
向量搜索(相似性搜索):在向量空间中来查找相似对象,查询向量(query),在向量空间中寻找与之距离最近的邻居,这些邻居便是与查询向量最相似的对象。
向量数据库:是一种专门用于存储和检索高维向量数据库的知识库,它们主要用于处理与相似性搜索相关的任务。能够存储海量的高维向量,这些向量可以表示数据对象是特征,可以作为AI系统的长期记忆库。
向量存储在数据库中,这些向量主要是由非结构化数据(文本、视频和音频,占全球数据的大约80%,它们通常来源于人类生成的内容,不易以预定义格式存储,这类数据可以通过转换为向量嵌入,有效地存储在向量数据库中,以便进行管理和搜索)通过嵌入模型转化而来的结构化数据则以表格形式存在,与非结构化数据形成对比。对于这些非结构化数据可以基于语义相似度进行相似性搜索。在检索过程中,系统会从海量的文档或数据集中,找出与用户查询最为相关的内容,随后,系统将进一步从中筛选出,排名靠前的k个文本片段(top k text chunks),在检索出的top k文本片段基础上,进一步根据与用户查询的相关性和上下文适配度进行重新调整(reranking重新排序的步骤),这些重新排序过的文本之后将作为context被嵌入到提示词模板中与用户问题相结合,从而构建出一个全新的提示词,新的提示词将被发送给大语言模型以生成最终的答案,模型生成的答案再返回给用户。
如何衡量向量嵌入的相似性?
怎样计算两个向量之间的距离来确定它们是否相似?
显然,我们不能依赖肉眼进行这种比较。
在相似向量搜索中,最常用的度量距离的指标有:

欧氏距离-欧几里得距离,用于测量高维空间中两点之间的直线距离。

余弦相似度-通过计算两个非零向量的夹角的的余弦值,来衡量它们之间的相似性,它常用于文本的数据。
优势:即使两份文档因为长度不同而在欧氏距离上相距甚远,它们之间的夹角可能仍然很小,从而具有较高的余弦值相似度。因此,余弦相似度主要应用于自然语言处理领域。
余弦值相似度的值范围从-1到1
1表示两个向量完全相同,接近1的值则表明向量之间,有很高的相似性。
0表示它们正交(即没有相关性)
-1表示它们方向相反

点积相似度-两个向量的模长乘积与它们之间夹角的余弦值的乘积,点积会受到向量的长度和方向的影响。
五种分块策略大揭秘
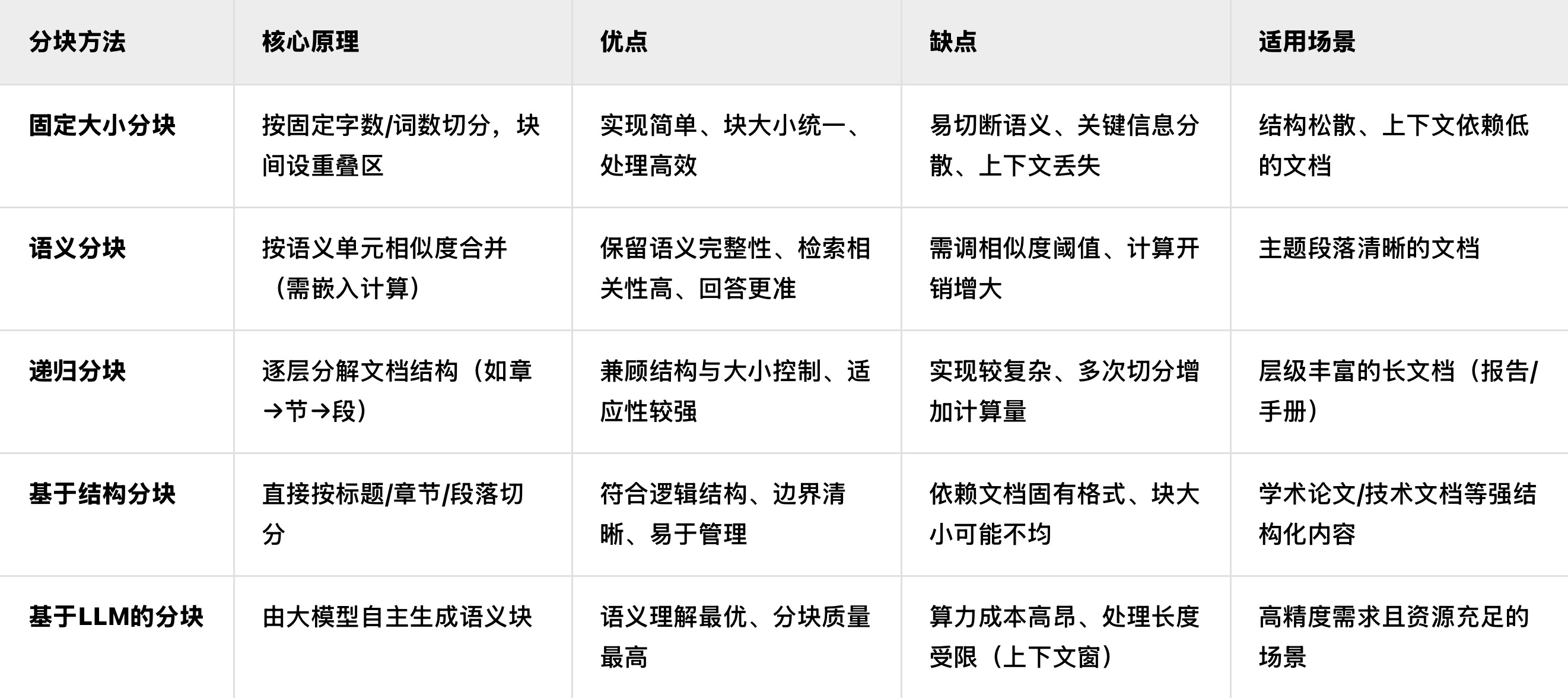
总结
RAG技术确实让AI回答问题变得“开挂”了,而文本分块策略,就是解锁这个超能力的关键一步。选对了方法,AI就能更聪明、更精准地帮到你。
不过实话实说,RAG真不是那种“一键部署,万事大吉”的省心技术。从怎么存你的资料、到怎么“切”这些资料、再到最后怎么找答案和生成回答,每一个环节都可能成为你项目成功路上的“坑”。
希望通过这篇文章,能帮你更清楚地理解RAG到底是怎么运作的,特别是“分块”这个关键小门道,让你在应用AI的时候少踩点雷。
本文由 @大栗 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议







