
服装视频广告太烧钱?卡点变装太难拍? 字节跳动智能创作团队联合清华大学最新推出一款全能的视频换装模型 DreamVVT,为视频虚拟试穿领域带来了突破性进展。
该模型基于 Diffusion Transformer(DiTs)构建,通过精细的两阶段设计,成功解决了现有技术在复杂场景下的痛点, 能够支持任意类型的衣服、处理大幅度的人物或者相机运动、复杂背景以及不同的风格的输入。


- 论文链接:https://arxiv.org/abs/2508.02807
- 代码链接:https://virtu-lab.github.io/
技术前沿:攻克复杂场景下的
视频虚拟试穿难题
视频虚拟试穿(Video Virtual Try-on, VVT),这项旨在将任意服装魔法般地 “穿” 在视频中人物身上的技术,正逐渐成为电商、广告及娱乐产业的焦点。然而,要实现理想效果,现有技术仍面临着严峻挑战。
主流的端到端方案高度依赖稀缺的 “服装 - 视频” 成对训练数据,同时难以充分利用强大预训练模型的先验知识。这导致在人物 360 度旋转、镜头剧烈运镜或背景动态变化的复杂场景下,生成的视频往往会遭遇 服装细节崩坏、纹理丢失与时序抖动 等一系列问题。
为攻克这一行业难题,字节跳动智能创作团队与清华大学携手,提出了全新的 DreamVVT 框架,刷新了该领域的 SOTA 记录。该框架基于强大的 Diffusion Transformer (DiT) 构建,并独创性地提出了一套分阶段生成方案,精准解决了现有技术在复杂场景下的核心痛点,能够生成高保真且时间连贯的虚拟试穿视频。
破局之道:精巧的两阶段生成框架
DreamVVT 的核心设计理念,在于其精巧的两阶段框架。这一设计巧妙地解耦了任务难度,使其既能充分利用海量的非成对数据进行学习,又能灵活地融合预训练模型的先验知识与测试阶段的即时信息。其核心贡献主要体现在以下三个方面:
1. 创新的分阶段框架:我们首次提出了基于 DiT 的分阶段方案,它打破了对成对数据的依赖,能够有效利用非成对数据、先进视觉模型的先验知识以及测试时的输入信息,显著提升了模型在复杂场景下的虚拟试穿性能。
2. 关键帧与大模型结合:我们将静态的关键帧试穿与视频语言模型(Video LLM)的推理能力相结合。这一机制为视频生成提供了兼具丰富外观细节与全局运动逻辑的综合指导,从而在根源上平衡了服装细节的保真度与视频整体的时间一致性。
3. 卓越的性能验证:最后,大量的实验结果有力地证明,在多样化的真实场景下,DreamVT 在保留高保真服装细节和确保时序稳定性方面,均显著优于现有的所有方法。
技术解码:揭秘两阶段高清视频换装方案
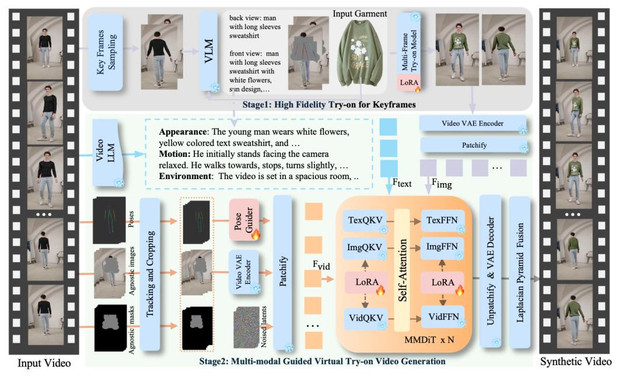
我们的高清视频换装技术,其核心是一个精心设计的两阶段框架。第一阶段负责生成高质量的多张静态换装参考图,第二阶段则基于这些参考图,结合多模态信息,生成时序稳定的高保真换装视频。
第一阶段:生成高质量的换装关键帧
1. 智能关键帧采样
为了全面捕捉人物的动态,我们设计了一套智能采样策略。首先,设定一个标准的正面 A 字姿态作为 “锚点帧”。接着,通过计算视频中每一帧与锚点帧的骨骼运动相似度,并结合人物在画面中的面积比重进行加权,为每帧的 “独特性” 打分。最后,我们采用一种反向搜索算法,从高分帧中筛选出一组信息冗余度最低的关键帧,为后续生成提供多样化的姿态或者视角参考。
2. 多帧换装参考图生成
有了关键帧,我们利用一个在预训练模型 Seedream 上微调的 Diffusion Transformer 来生成换装后的参考图。我们巧妙地集成了 LoRA 模块,实现了参数高效的微调。模型会同时接收多个关键帧、服装图以及我们精心设计的 “一致性图像指令”。通过注意力机制中的 QKV 拼接,模型能有效聚合所有关键帧的信息,确保生成的换装参考图在细节上保持高度一致。此外,我们还引入 VLM 对服装进行详细的文本描述,并进行对齐,进一步强化了多帧间的外观一致性。
第二阶段:多模态引导的视频生成
第二阶段的核心任务是,基于第一阶段生成的换装参考图,结合多种信息,生成最终的换装视频。我们基于一个强大的图生视频(I2V)框架进行构建。
1. 多模态输入处理
模型同时接收多种模态的输入,各司其职:
- 动作信息:为了精准还原身体动作,我们提取视频的 2D 骨骼序列,并通过一个带有时间注意力机制的 Pose Guider 将其转换为平滑的姿态特征。
- 视觉信息:我们将裁剪后的衣服不可知图像(Agnostic Image)和遮罩送入 VAE 编码器,得到基础的视觉特征。
- 文本信息:考虑到仅靠骨骼无法捕捉精细的服装动态,我们利用 Video LLM 提取详细的动作和视觉文本描述, 为模型提供不同维度和精细地指导。
- 外观信息:第一阶段生成的换装关键帧则作为核心的外观参考,同样被编码为图像特征。
2. 模型结构与训练
在模型结构上,我们冻结了 Seaweed 模型的所有权重,仅在视频流和图像流中插入轻量化的 LoRA 适配器,实现了高效训练。所有模态的特征在输入网络后,通过一次 全自注意力(Full Self-Attention) 操作进行深度融合,使模型能自适应地对齐不同信息。
3. 视频生成与融合
融合后的特征被送入 DiT 模块进行多轮去噪,最终由 VAE 解码器生成换装视频。我们还采用高效的拉普拉斯金字塔融合技术,将生成的视频无缝地嵌入原始背景中。在训练阶段,我们采用了多任务学习策略,随机切换训练任务,充分利用了不同模态的互补优势,最终实现了卓越的生成效果。
此外,针对长视频生成,团队使用前一段视频最后一帧的潜表示作为后一段的初始帧,避免了因反复编码解码导致的误差累积,显著延长了视频质量明显下降前的持续时间。
实验验证:全方位展现
通用场景下的 SOTA 性能
与 SOTA 方法的全面对比
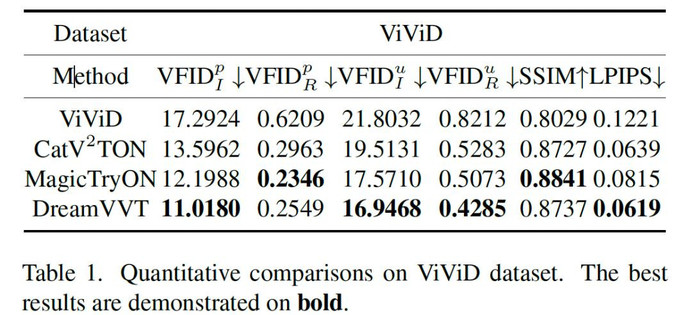
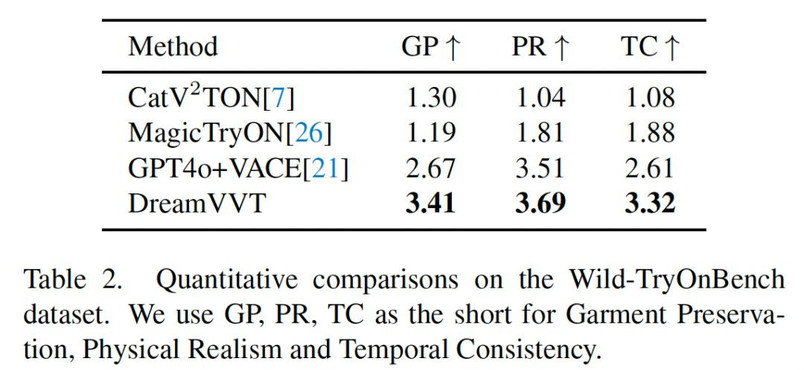
在定性对比中,面对 360 度旋转等复杂野外场景,现有方法(如 CatV²TON、MagicTryOn)常出现细节崩坏和模糊,而 DreamVVT 则能稳定生成时空平滑且细节逼真的结果。定量数据更有力地印证了这一点。在 ViViD-S 数据集上,我们的 VFID 和 LPIPS 等关键指标达到 SOTA。在更具挑战性的自建基准 Wild-TryOnBench 上,DreamVVT 在服装细节保留度(GP) 、物理真实感(PR) 和 时序一致性(TC) 三项人工评估中全面领先,展现了强大的泛化能力。


消融实验
1. 关键帧数量:将关键帧从 1 帧增至 2 帧,能为模型提供更丰富的服装与运动信息,显著提升了细节保真度与物理真实感,有效避免了伪影。
2. LoRA 微调:采用 LoRA 进行轻量化微调,相比全参数训练,能更好地继承预训练模型的文本控制能力,在不牺牲其他性能的前提下,显著增强了生成视频的物理真实感,尤其能够实现和服装的交互。
这些实验充分证明,DreamVVT 通过其创新的设计,在复杂场景下的视频虚拟试穿任务中取得了突破性的进展。

总结
DreamVVT 的出现,为视频虚拟试穿技术开辟了新的道路。它在复杂场景下的出色表现,标志着视频虚拟试穿技术正迈向成熟的商业应用,为电商和泛娱乐行业开启了无限的想象空间。







