
背景:一个AI问答应用的决策困境
2024年初,"智询未来"团队的CTO李哲和他的5人开发小组陷入了一场典型的技术选择困境。他们计划开发一款垂直领域的AI问答应用,核心功能是为用户提供专业、准确的长时间对话服务。
技术栈很快确定了,但核心模型选型成了难题。团队在三个主流大模型间犹豫不决:OpenAI的GPT-4-turbo以能力强著称但价格不菲,Anthropic的Claude-3系列在长文本处理上有独特优势,而Meta的Llama-3-70B作为开源代表虽然能力稍逊但成本可能最低。
"我们的种子轮融资只有50万元,"李哲回忆道,"如果选错模型,每个月的API调用费用可能就会烧掉我们一大半资金,项目可能撑不过三个月。"
困境:手动成本计算的复杂性与不确定性
团队最初尝试手动计算成本。工程师王瑞负责这项任务,他描述了其中的困难:"每个厂商的计费方式都不相同。GPT-4按输入输出token分别计费,Claude-3按每百万token统一计价,而Llama-3虽然开源免费,但如果通过AWS Bedrock调用,又有自己的计费规则。"
更复杂的是需要基于业务场景进行预测。团队预计初期日活跃用户(DAU)约1000人,每人平均进行5次问答对话。"我建了一个复杂的Excel模型,"王瑞说,"但需要不断查询各个平台的最新价格,还要考虑上下文窗口、图片处理等可能产生的额外费用。最担心的是计算出错或者忽略了某个隐藏成本项。"
解决方案:数据驱动的决策过程

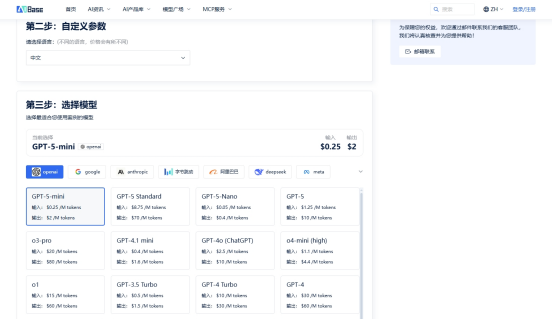
在几乎要抛硬币决定时,团队发现了AIbase的大模型费用计算器(https://model.aibase.com/zh/calculator)。
李哲描述了使用过程:"计算器的界面非常直观。我们只需要输入业务参数:预计的月调用量,平均每次对话的输入输出token数量。"系统立即生成了清晰的对比结果。令团队惊讶的是,GPT-4-turbo版本,Claude-3-sonnet版本,Llama-3-70B版本,三个模型的成本差异远比想象中大
"计算器最价值的功能是提供了细分的成本构成,"王瑞指出,"我们可以看到每个模型的输入输出费用占比,甚至能模拟不同上下文长度对成本的影响。这让我们对预算有了真正清晰的掌控。"
结果:出人意料的决策与资源重新配置
计算结果让团队做出了出乎意料的选择。他们原本倾向的GPT-4-turbo成本最高,而Claude-3在长对话场景下的性价比优势明显,且其200K的上下文窗口正好符合他们"长时间对话"的产品需求。
"我们最终选择了Claude-3-sonnet,"李哲说,"这个决定每月能为我们节省近4000元人民币。更重要的是,计算器帮助我们发现,通过优化prompt长度,还能进一步降低15%左右的成本。"
节省下来的预算被重新分配到两个关键领域:一部分用于加强数据安全和用户隐私保护,另一部分投入到了更精细的提示词工程优化中。
启示:成本预计算为必要决策流程
这个案例揭示了AI应用开发中的一个关键转变:模型选择不再仅仅是技术能力的比较,更是成本效益的精确计算。
对于初创团队而言,在项目启动前进行详细的成本测算,已经成为规避风险的必要步骤。通过专业的计算工具,团队能够将不确定的成本转化为可控的预算项,从而做出更加理性、可持续的技术决策。
"现在回看,如果没有这个计算过程,我们很可能会选择最知名但最昂贵的方案,"李哲总结道,"那将让我们的资金链处于危险境地。对于资源有限的初创公司来说,这种数据驱动的决策方式不是可选,而是必需。"
(本文中使用的成本数据基于计算器当时价格,实际费用可能因厂商调价而变动,请以平台实时计算结果为准。)
(举报)






