
AI赋能内容创作早已不是新鲜事,但如何真正“快速高质”产出一条可分发的解说漫画视频?本篇将拆解一个完整流程,从文案生成、脚本设计、漫画创作到视频剪辑与配音,帮助你理解文生视频的全链路操作方式,探索如何将AI工具变成你的创作助理。

开头先啰嗦两句,之前我的很多关于AI的分享,内容主要是涉及到AI的业界进展和个人研究的心得。期间时不时就有朋友问我说能不能讲讲日常使用AI的一些心得技巧。于是乎,我计划开启一个新的系列——“AI应用教学”,计划是聚焦到一个小的应用场景,全流程拆解它的步骤,既讲操作,也讲过程心得经验。
希望大家会喜欢。
场景拆解
我在之前发布的关于探讨假如AI可以完美复刻过世之人的视频中,就插入了一段关于“忒修斯之船”的解说漫画视频。后来就有朋友好奇,这样的解说漫画视频,是怎么制作出来的?于是,我也就顺着这次机会,打算开启一个新的系列“AI应用教学”。不定期地把我在日常中应用AI的一些场景或技巧,其中的一些落地细节,全流程地一一整理,分享给大家。
回到我们这次要分享的场景——解说漫画视频,先说说它的适用场景:针对一些相对通行的概念或事件,进行动画化的演示说明。“相对通用”,意味着我们只需要给AI说明该概念即可,而不必去详细构想每一幅画面。动画化演示,意味着是“先生图再图生视频”,“图生视频”尤其是动画,对真实性要求也没这么高,当前的AI是完全可以胜任的。我全程使用的是AI产品,是字节跳动出品的“豆包”。
具体而言,我们可以将这个场景,拆分为三个步骤:
- 针对要解说的“概念”,用AI拆解说明步骤并生成对应的图片。
- 针对各个图片,生成动态的视频。
- 将各个视频进行拼接,并配上配乐、旁白、字幕等内容,剪辑成片。
接下来,我们就针对这些步骤,进行详细介绍。
第一步:生成图片
第一步先使用AI对我们要解说的概念或事件进行“步骤拆解”,并基于拆解的步骤,生成对应的配图。这里严格来讲,步骤拆解、生成配图,是“两个步骤”。前面我们就有提到,对于相对通行的概念或事件,比如我本次想要解说的是哲学上著名的“忒修斯之船”悖论,AI预训练的内容肯定是有包含的。所以我在操作时就将它合并为一步直接进行处理了。
比例 「9:16」帮我创作一系列的漫画风格的图片,介绍“忒修斯之船”悖论(以及它的另外组建新船延伸讨论),上面不要有任何文字
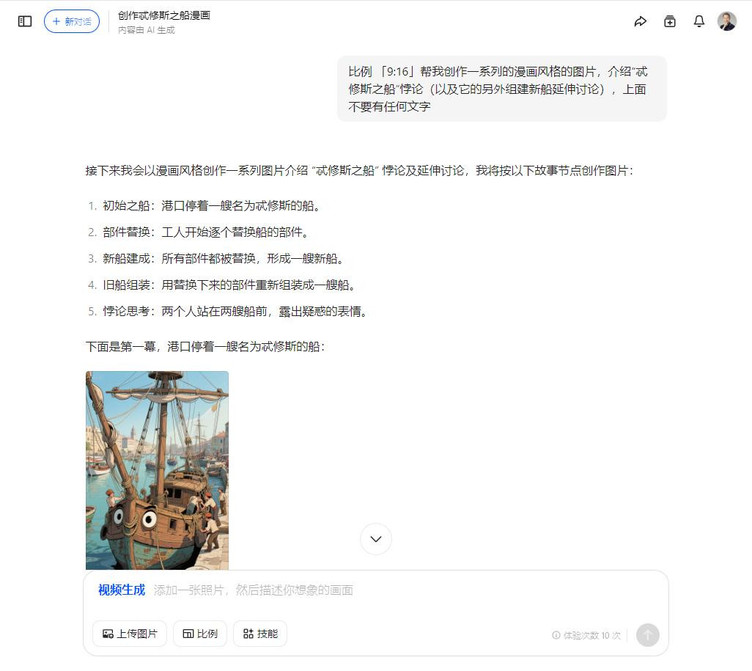
如各位所见,我的提示词相当地简单。当然,如果你要解说的概念或事件比较陌生,也可以先通过向AI描述,让AI来拆解具体步骤(可以告诉AI后续需要制作解说漫画,具体需要AI拆解为五个步骤之类的)。拆解后再将每一张图片的内容合并,作为生成图片的提示词。
当然,生成图片这里仍然有可能遇到生成出来的图片并不合我们心意,比如我生成的第一个版本,我就觉得画面过于复杂。此时就要尝试让AI多生成几次,挑选合适的版本(业内俗称“抽卡”)。至于具体如何操作,就要看遇到的“不合心意”的情况,比如风格是对的只是不够美观,那就直接再次生成;又比如风格或内容方向不对,那么就修改提示词后再次生成。而豆包是支持直接通过对话来修改图片的,因此我也就偷了个懒,直接通过对话来引导豆包生成其他的风格的图片了。
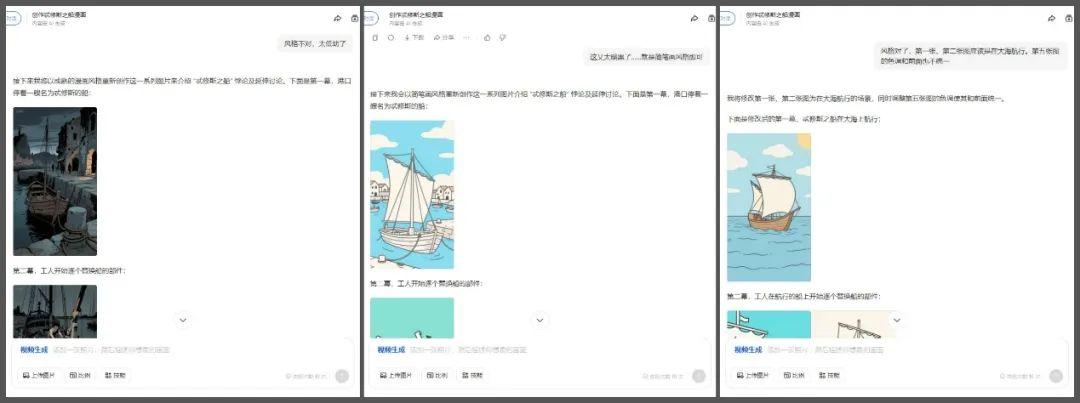
经过3次的对比,我最终挑选了“简笔画”这个风格的图片,作为下一步“图生视频”的素材。(实操过程中还有针对个别图片进行进一步调整,此处不再一一展示。)
第二步:图生视频
完成了图片素材的生成,就可以进入到第二步,“图生视频”。具体的方式是将生成的每张图片分别作为该次视频生成的参考图片,并补充希望转成视频后,画面如何运动的描述,也就是对应的提示词。
类似的任务,目前国内的各大视频生成AI产品都可以满足,包括我前面用来生成图片的豆包,它也可以支持“图生视频”。我们只需要选择“视频生成”的技能,点击打开具体的图片,将其添加为参考图,再加上对应的视频画面描述即可(比如我截图描述的就是“帆船在大海中航行”)。如果各位使用的是其他的AI产品,操作过程应该也是类似的,只不过需要多一步“下载再上传图片”的操作而已。
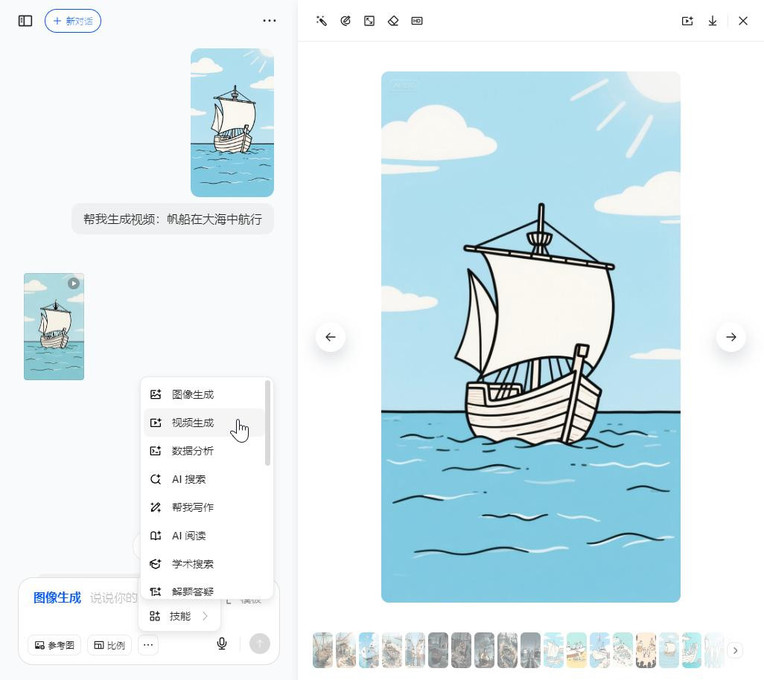
同样地,如果遇到生成出来的视频并不合我们心意,处理方法和前面所说的类似,“抽卡”应对之。而由于我这次的图片相对简单,所以也没有在这里花费太多时间。不过得多提一句是,生成视频所需要耗费的资源(Token)远高于生成图片。因此在前面描述画面时建议尽量想齐全想清楚并表达准确。至于如何做到,可以多学习平台上优秀作品的提示词,更多的是多去实践,才能熟能生巧。
第三步:剪辑成片
将每个步骤的配图都生成视频后,就可以作为素材进行拼接,并附上配乐、解说、字幕等内容,最终剪辑成片了。
我在本次的“忒修斯之船”的案例中,由于录制视频时我原本设想的是口头表达,当时还没想到要用“解说漫画”来替代。所以我其实是先录制了口头的解说,再用视频上去匹配的。如果你是把这一步放到最后,那么可以继续利用AI,让它生成对应的解说词(具体如何控制文案长度、风格这里就不展开了),然后自行录制或者使用AI来生成对应的旁白。
如果各位是希望尝试AI生成旁白(事实上如果不是先录制好了我自己的解说,我肯定会尝试用AI来生成),那么我可以推荐另一款产品,由Minimax稀宇科技出品的Hailuo AI的“声音生成”。它最新的Speech 02模型,增加了Voice Design声音设计的能力,可以支持用户选择各类声线、各类语调乃至于通过自然语言描述的音色来生成音频。这对于我们想制作解说漫画视频,可谓是无比适配。
旁白也准备好了,我们就可以将它们拼接在一起。
这里我使用的是产品倒没什么特别,就是“剪映”。
需要补充的一点经验就是,因为生成视频的长度往往是固定的(比如5秒、10秒),而对应的解说旁白则不可能刚好对齐。此时处理就比较简单的,可以音、画两边都尝试变速,在尽可能小影响的范围内对齐即可。
额外的一些总结
我在去年开发自己的AI课程时,针对AI生成图片/生成视频的领域,总结过当时面临的三大挑战:
- 肢体的协调性,尤其是生成人物的手指;
- 文字的生成,去年时的AI生图还无法处理文字,但这方面随着近半年的快速迭代,已经可以说是基本被解决了;
- 角色一致性,也就是生成多张图片时是否能保持其中角色形象的一致性。
而我之所以使用豆包来生成,很重要的一点是它在第3点的角色一致性上有长足的进步。这里再提供我利用豆包生成的另一组图片,让大家可以更好地感受豆包生图的角色一致性。

在这一组名为“AI时代下产品经理的工作变化”为主题的5幕图片中,可以看出,其中的主人公形象是保持一致的。
同样地,细心的朋友或许会发现,我所使用的都是偏向漫画的风格,这当然是经过老考量。如前面所说,AI生图在图像的真实性上仍有不足(也就是说AI生成的图片在真实性上还是比不过摄影作品)。而像漫画这样的风格,画面内容相对简单,也对于画面的真实性没有过高的要求,此时AI就可以很好地胜任,非常适配像解说概念或事件这样的场景。
与此同时,我们也期待迭代进化“一日千里”的AI,能够在多模态领域持续进步。或许在不远的某一天,我们就可以用上更真实、更易用、更强大的多模态AI产品。
作者:产品经理崇生,公众号:崇生的黑板报
本文由作者原创投稿/授权发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







