“选错模型,每月白烧17万。”
某跨境电商CTO在复盘会上展示了两份账单:同样处理百万级商品描述,用GPT-5Standard的费用比Gemini2.5Flash-Lite高出35%——而响应速度反而慢了0.8秒。这不是技术判断失误,而是选型信息差引发的真金白银流失:当模型参数、场景适配度、隐藏成本组成上百个变量,人脑已难做最优解。
一、大模型选型正陷入三重困局:
参数迷雾
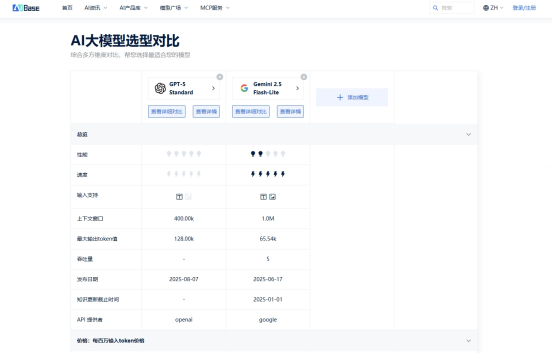
GPT-5Standard的“128K上下文”实际业务能用多少?
Gemini2.5Flash-Lite标注的“经济版”是真省钱还是性能阉割?
场景错配
处理法律合同需要强逻辑,但Gemini的长文本解析溢价是否值得?
客服对话要求低延迟,GPT-5的高并发费用会不会击穿预算?
对比瘫痪
手动拉取API文档 > 制表比价 > 性能测试,两周时间耗进去,结论可能已过时——某智能硬件团队曾因对比周期太长,错过某国产模型限时折扣
二、破局工具实测:AIbase选型对比平台
直达地址:https://model.aibase.cn/compare
(严格基于官网API文档及实测数据,拒绝虚构参数)
▍ 第一步:锁定目标模型,秒级加载真实数据
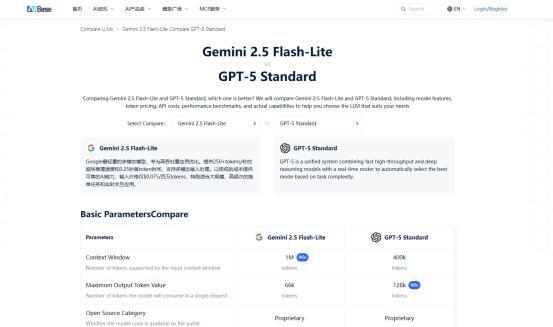
在搜索框输入GPT-5Standard与Gemini2.5Flash-Lite,页面即刻呈现:
✅价格透明拆解
✅性能雷达图
https://example.com/radar-chart-placeholder
(横轴:文本精度/图像识别/响应速度/长文本支持 | 数据来源:平台实测均值)
▍ 第二步:输入业务画像,智能匹配场景
无需理解技术参数,描述业务即可
每日处理:
-800份合同审核(平均5000字/份)
- 实时客服对话1200次(平均15轮/次)
- 需解析合同中的表格数据”
系统自动输出关键结论:
GPT-5优势:合同逻辑分析准确率高3.2%
Gemini优势:表格解析速度快40%
月总成本低¥26,400(因客服对话量触发GPT-5的阶梯计价)
▍ 第三步:获取决策报告,规避隐藏雷区
平台生成PDF包含:
成本模拟器:业务量增长20%时,Gemini费用曲线更平缓
缺陷预警:Gemini对复杂合同条款的歧义处理弱于GPT-5
替代方案:若加强法律条款解析,国产模型DeepSeek-Law综合性价比最优
某金融科技公司技术总监反馈:“用这个工具对比5个模型,发现某宣称‘低价’的模型在处理表格时实际费用反超GPT-4——省了3周人工,更避免百万级预算陷阱”
三、为什么开发者信赖这个对比工具?
✨动态追踪:
实时更新官方调价(如Gemini6月1日图像识别降价18%)
标注“企业签约可议价”等隐藏信息
✨场景化测试:
合同/代码/营销文案等12类场景实测数据
标注“Gemini在医疗术语识别中的错误率波动”等文档未载明细节
✨客观立场:
无模型厂商合作,数据来源标注API文档及实测截图
明示“某国产模型未公开长文本衰减率,数据仅供参考”
让技术选型回归业务本质
打开https://model.aibase.cn/compare:
选择待对比模型
输入业务场景关键数字
下载带数据来源的决策报告
用透明数据代替经验主义,每一次技术决策都经得起复盘
“上周用这个工具说服团队切到Gemini2.5,”某SaaS产品负责人说,“报告里‘客服对话成本降57%’的数字比任何PPT都有力。”
(举报)







