面试不只是问答,而是一场信息不对称的博弈。本文以“AI 对抗式模拟面试”为切口,探讨如何通过技术手段重构面试的评估逻辑、追问机制与复盘能力,让候选人与招聘方在更少的误判中做出更好的决策。

首先面试本质上是一场信息不对称的博弈。面试官带着岗位标准与有限时间去判断一个陌生人;
求职者在紧张、有限的时间里尽力把自己最好的一面呈现出来。两端的“噪声”——表达不佳、预期错位、追问不到位——造成了大量的误判与遗憾。
一款模拟面试小程序 AIjob模拟面试,核心功能:AI面试AI。不同于以往的AI面试让求职者答题,采用对抗的方法,让Ai在对抗中产生更好的问答方案。
不是用 AI 来替代面试,而是用 AI去模拟面试官和求职者,先打一场“对抗演习”。我们拆解一下它能解决什么、如何设计。
为什么需要“AI 对抗”这种方法?
- 信息不对称:候选人往往不知道面试官真正关心的点(追问逻辑、深挖维度),容易把精力放错地方。
- 评估噪声大:不同面试官的问法、风格、时长差异,会导致评价不一致。
- 练习成本高:高质量的模拟面试需要经验丰富的面试官,时间成本高且难以复盘。
- 可复盘性差:真实面试后难以回看“问法/追问逻辑”的全过程并系统改进回答。
把“AI 面试官”作为标准化、可复盘的评估器,把“AI 求职者”作为候选人的数字分身进行对抗,理论上可以提前暴露“考核逻辑”,帮助候选人聚焦答案结构与证据,同时为招聘方提供一致性更高的校准素材。
把想法具体化:AI 对抗应该做什么(不只是问答)
一个有价值的 AI 对抗流程,至少应包含下列模块(按产品设计思维):
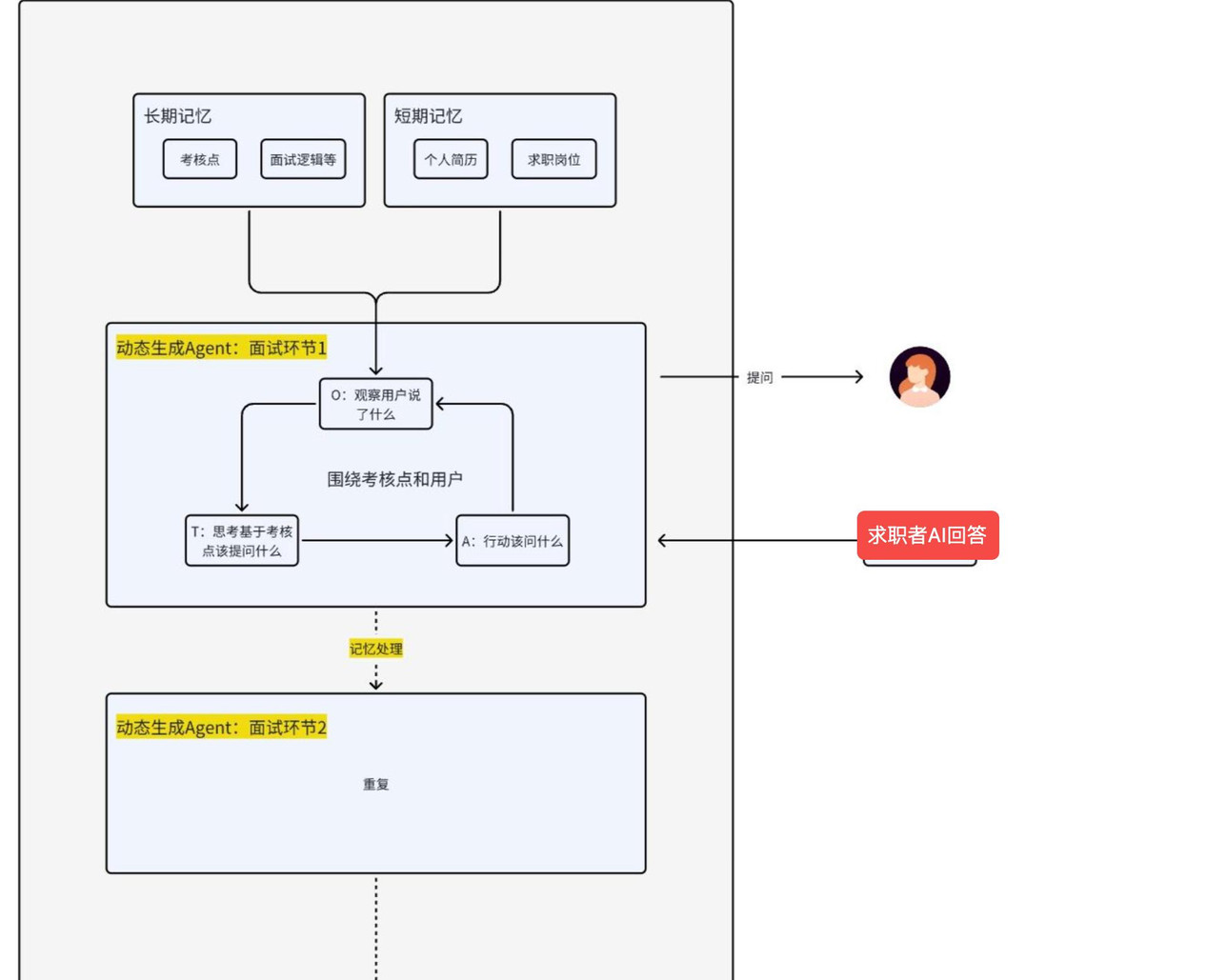
- 履历解析(Persona构建):自动把简历结构化成可查询的“事实点”(时间、职责、成果、技术栈、影响量化数据),并生成候选人的认知侧写(经验年限、常见假设、潜在薄弱点)。
- 岗位-等级化问卷/题库:根据岗位与经验年限选择不同的问题集,并内置追问策略(为什么、如何、举例、反思)。
- 多轮对话引擎(含追问策略):面试并非一问了之,追问的方向决定评估结论。引擎要能基于候选人回答发起合理追问,并记录问法逻辑(事实核验/能力深挖/场景还原)。
- 评分与解释层:给出分维度评分(比如:经历真实性、专业能力、岗位理解、潜力、动机),并附带可解释的理由与改进建议,而非一个不可理解的分数。
- 可视化复盘与最佳答案生成:展示问答树、关键追问节点、被质疑的事实点,给出“若这是你,你可以如何补充/重构回答”的示例(并说明为什么更好)。
这能带来的具体价值(候选人 / 招聘方)
对候选人:
- 看见“问法的逻辑”:明白面试官为什么会追问某个细节,从而学会把答案结构化、证据化。
- 降低盲目性:知道不同经验段面试官的期待点,调整目标与表达(不是用5年人的标准衡量2年经验)。
- 可复盘、可迭代:多次演练后,你能看到自己的进步路径,不再依赖主观感觉。
对招聘方 / 面试官:
- 统一面试节奏与尺度:提供面试模板和追问策略,帮助新手面试官稳定评分。
- 构建答题基准:通过AI模拟得到“候选人在不同回答情况下的表现分布”,用于校准面试官期待。
- 节省人力做低风险练习:把一些高频、标准化的问题让AI先跑,节省真人时间用于更高价值的评估环节。
关键设计与关注的问题
把技术幻想变成能产出价值、能被信任的产品。几个必须解决的问题:
评估的可验证性(Validation)如何证明 AI 的评分与真人面试结果具有统计相关性?A/B:AI 模拟评分 vs. 人类面试评分,衡量一致性、预测在岗表现的能力(预测效度)。
数据来源与质量:面试数据需要多公司、多岗位、多风格的考核标准,高标准的数据才能让模型提问更精准,避免提问单一或离谱。
可解释性与可纠错的输出:逻辑提问要复合真实面试场景,输出不仅是“你不合格”,而是“哪里缺事实/表达结构/量化指标”,并给出可操作的改进方案。
面试逻辑
像个HR一样提问,进行综合考察,多agent协同,围绕五个维度展开,独立Agent:
- 工作经历验证:深挖项目细节,判断经历的真实性与实际价值
- 专业能力评估:考察是否拥有对应岗位的硬技能与软技能)
- 岗位理解深度:你是否真的懂这个岗位要做什么
- 潜力判断:你的未来成长天花板
- 求职意向判断:判断你的稳定性与动机
不是要让 AI 把面试做掉,而是把“面试的技艺”可视化
把 AI 作为“对手”和“镜子”同时使用,能帮助候选人看到面试官的追问逻辑,帮助招聘方稳定评分尺度,但这只是工具,不是答案。真正的目标是减少因信息不对称和评价噪声造成的误判,让双方在更少的随机性下做决定。欢迎去体验测试
本文由 @易俊源 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







